|
|
Login |
[#]
Интересные алгоритмы кластеризации, часть первая: Affinity propagation
habrabot(difrex,1) — All
2017-02-06 11:30:03
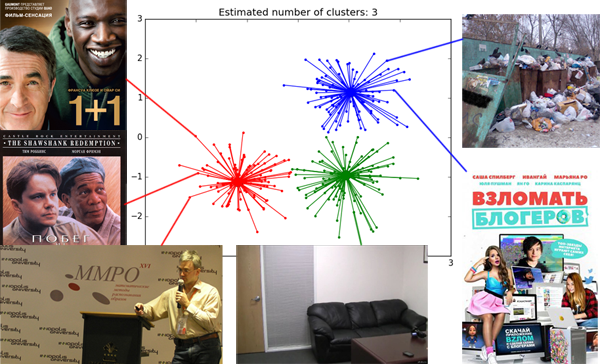
Если вы спросите начинающего аналитика данных, какие он знает методы классификации, вам наверняка перечислят довольно приличный список: статистика, деревья, SVM, нейронные сети… Но если спросить про методы кластеризации, в ответ вы скорее всего получите уверенное «k-means же!» Именно этот золотой молоток рассматривают на всех курсах машинного обучения. Часто дело даже не доходит до его модификаций (k-medians) или связно-графовых методов.
Не то чтобы k-means так уж плох, но его результат почти всегда дёшев и сердит. Есть [более совершенные][1] способы кластеризации, но не все знают, какой когда следует применять, и очень немногие понимают, как они работают. Я бы хотел приоткрыть завесу тайны над некоторыми алгоритмами. Начнём с Affinity propagation.
![image][2]
[Читать дальше →][3]
[1]: http://scikit-learn.org/stable/modules/clustering.html
[2]: https://habrastorage.org/files/95e/84e/c80/95e84ec802934e708b155579624c9360.png
[3]: https://habrahabr.ru/post/321216/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habrabot(difrex,1) — All
2017-02-06 11:30:03
Если вы спросите начинающего аналитика данных, какие он знает методы классификации, вам наверняка перечислят довольно приличный список: статистика, деревья, SVM, нейронные сети… Но если спросить про методы кластеризации, в ответ вы скорее всего получите уверенное «k-means же!» Именно этот золотой молоток рассматривают на всех курсах машинного обучения. Часто дело даже не доходит до его модификаций (k-medians) или связно-графовых методов.
Не то чтобы k-means так уж плох, но его результат почти всегда дёшев и сердит. Есть [более совершенные][1] способы кластеризации, но не все знают, какой когда следует применять, и очень немногие понимают, как они работают. Я бы хотел приоткрыть завесу тайны над некоторыми алгоритмами. Начнём с Affinity propagation.
![image][2]
[Читать дальше →][3]
[1]: http://scikit-learn.org/stable/modules/clustering.html
[2]: https://habrastorage.org/files/95e/84e/c80/95e84ec802934e708b155579624c9360.png
{kind=link}
[3]: https://habrahabr.ru/post/321216/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut