|
|
Login |
[#]
[Из песочницы] Нечеткий поиск в словаре с универсальным автоматом Левенштейна. Часть 1
habrabot(difrex,1) — All
2016-01-26 19:30:03
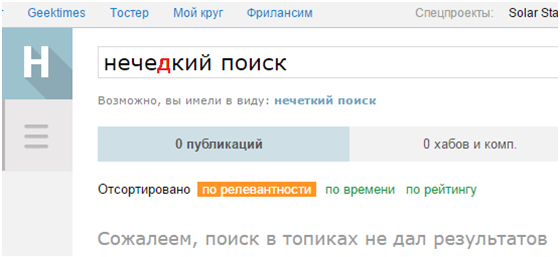
![][1] Нечеткий поиск строк является весьма дорогостоящей в смысле вычислительных ресурсов задачей, особенно если вам необходима высокая точность получаемых результатов. В статье описан алгоритм нечеткого поиска в словаре, который обеспечивает высокую скорость поиска при сохранении 100% точности и сравнительно низком потреблении памяти. Именно автомат Левенштейна позволил разработчикам Lucene повысить скорость нечеткого поиска [на два порядка][2] [Читать дальше →][3]
[1]: https://habrastorage.org/files/543/5b4/0f0/5435b40f0ed04ef2971984189149ce95.png
[2]: http://blog.mikemccandless.com/2011/03/lucenes-fuzzyquery-is-100-times-faster.html
[3]: https://habrahabr.ru/post/275937/#habracut
habrabot(difrex,1) — All
2016-01-26 19:30:03
![][1] Нечеткий поиск строк является весьма дорогостоящей в смысле вычислительных ресурсов задачей, особенно если вам необходима высокая точность получаемых результатов. В статье описан алгоритм нечеткого поиска в словаре, который обеспечивает высокую скорость поиска при сохранении 100% точности и сравнительно низком потреблении памяти. Именно автомат Левенштейна позволил разработчикам Lucene повысить скорость нечеткого поиска [на два порядка][2] [Читать дальше →][3]
[1]: https://habrastorage.org/files/543/5b4/0f0/5435b40f0ed04ef2971984189149ce95.png
{kind=link}
[2]: http://blog.mikemccandless.com/2011/03/lucenes-fuzzyquery-is-100-times-faster.html
[3]: https://habrahabr.ru/post/275937/#habracut