|
|
Login |
[#]
Распределенное выполнение Python-задач с использованием Apache Mesos. Опыт Яндекса
habrabot(difrex,1) — All
2016-07-28 17:30:04
Подготовка релиза картографических данных включают в себя запуск массовой обработки данных. Некоторые задачи хорошо ложатся на идеологию Map-Reduce. В этом случае задача инфраструктуры традиционно решается использованием Hadoop или [YT][1]
В реальности часть задач таковы, что разбиение их на маленькие подзадачи невозможно, или нецелесообразно (из-за наличия существующего решения и дорогой разработки, например). Для этого мы в Яндекс.Картах разработали и используем свою систему планирования и выполнения взаимосвязанных задач. Одним из элементов такой системы является планировщик, запускающий задачи на кластере с учетом доступных ресурсов.
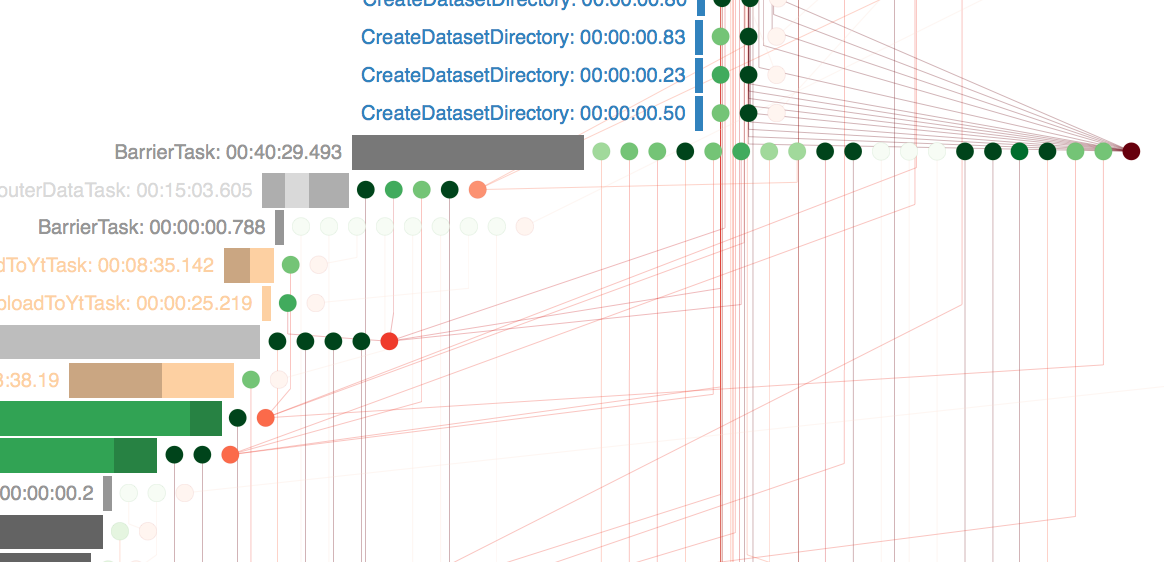
![Workflow Graph][2]
Эта статья о том как мы решили эту задачу с использованием [Apache Mesos][3].
[Читать дальше →][4]
[1]: https://events.yandex.ru/lib/talks/1091/
[2]: https://habrastorage.org/files/1a4/37b/092/1a437b092908486b9edec66bc74d2d55.png
[3]: http://mesos.apache.org/
[4]: https://habrahabr.ru/post/306548/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habrabot(difrex,1) — All
2016-07-28 17:30:04
Подготовка релиза картографических данных включают в себя запуск массовой обработки данных. Некоторые задачи хорошо ложатся на идеологию Map-Reduce. В этом случае задача инфраструктуры традиционно решается использованием Hadoop или [YT][1]
В реальности часть задач таковы, что разбиение их на маленькие подзадачи невозможно, или нецелесообразно (из-за наличия существующего решения и дорогой разработки, например). Для этого мы в Яндекс.Картах разработали и используем свою систему планирования и выполнения взаимосвязанных задач. Одним из элементов такой системы является планировщик, запускающий задачи на кластере с учетом доступных ресурсов.
![Workflow Graph][2]
Эта статья о том как мы решили эту задачу с использованием [Apache Mesos][3].
[Читать дальше →][4]
[1]: https://events.yandex.ru/lib/talks/1091/
[2]: https://habrastorage.org/files/1a4/37b/092/1a437b092908486b9edec66bc74d2d55.png
{kind=link}
[3]: http://mesos.apache.org/
[4]: https://habrahabr.ru/post/306548/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut