|
|
Login |
[#]
[recovery mode] Кластер высокой доступности на postgresql 9.6 + repmgr + pgbouncer + haproxy + keepalived + контроль через telegram
habrabot(difrex,1) — All
2016-11-01 19:00:05
![image][1]
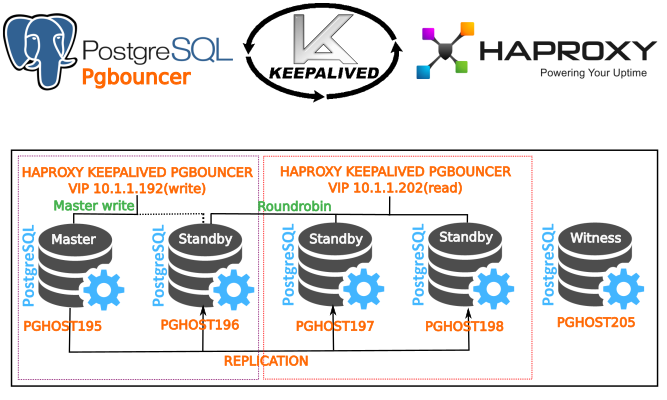
На сегодняшний день процедура реализации **«failover» ** в Postgresql является одной из самых простых и интуитивно понятных. Для ее реализации необходимо определиться со сценариями файловера — это залог успешной работы кластера, протестировать его работу. В двух словах — настраивается репликация, чаще всего асинхронная, и в случае отказа текущего мастера, другая нода(standby) становится текущем «мастером», другие ноды standby начинают следовать за новым мастером.
На сегодняшний день repmgr поддерживает сценарий автоматического Failover — autofailover, что позволяет поддерживать кластер в рабочем состоянии после выхода из строя ноды-мастера без мгновенного вмешательства сотрудника, что немаловажно, так как не происходит большого падения UPTIME. Для уведомлений используем telegram.
Появилась необходимость в связи с развитием внутренних сервисов реализовать систему хранения БД на Postgresql + репликация + балансировка + failover(отказоустойчивость). Как всегда в интернете вроде бы что то и есть, но всё оно устаревшее или на практике не реализуемое в том виде, в котором оно представлено. Было решено представить данное решение, чтобы в будущем у специалистов, решивших реализовать подобную схему было представление как это делается, и чтобы новичкам было легко это реализовать следуя данной инструкции. Постарались описать все как можно подробней, вникнуть во все нюансы и особенности.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/a17/d60/054/a17d600549ef46759aa32c7c22b4a2fc.png
[2]: https://habrahabr.ru/post/314000/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habrabot(difrex,1) — All
2016-11-01 19:00:05
![image][1]
На сегодняшний день процедура реализации **«failover» ** в Postgresql является одной из самых простых и интуитивно понятных. Для ее реализации необходимо определиться со сценариями файловера — это залог успешной работы кластера, протестировать его работу. В двух словах — настраивается репликация, чаще всего асинхронная, и в случае отказа текущего мастера, другая нода(standby) становится текущем «мастером», другие ноды standby начинают следовать за новым мастером.
На сегодняшний день repmgr поддерживает сценарий автоматического Failover — autofailover, что позволяет поддерживать кластер в рабочем состоянии после выхода из строя ноды-мастера без мгновенного вмешательства сотрудника, что немаловажно, так как не происходит большого падения UPTIME. Для уведомлений используем telegram.
Появилась необходимость в связи с развитием внутренних сервисов реализовать систему хранения БД на Postgresql + репликация + балансировка + failover(отказоустойчивость). Как всегда в интернете вроде бы что то и есть, но всё оно устаревшее или на практике не реализуемое в том виде, в котором оно представлено. Было решено представить данное решение, чтобы в будущем у специалистов, решивших реализовать подобную схему было представление как это делается, и чтобы новичкам было легко это реализовать следуя данной инструкции. Постарались описать все как можно подробней, вникнуть во все нюансы и особенности.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/a17/d60/054/a17d600549ef46759aa32c7c22b4a2fc.png
{kind=link}
[2]: https://habrahabr.ru/post/314000/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut