|
|
Login |
[#]
Об одной задаче Data Science
habrabot(difrex,1) — All
2015-09-12 15:30:03
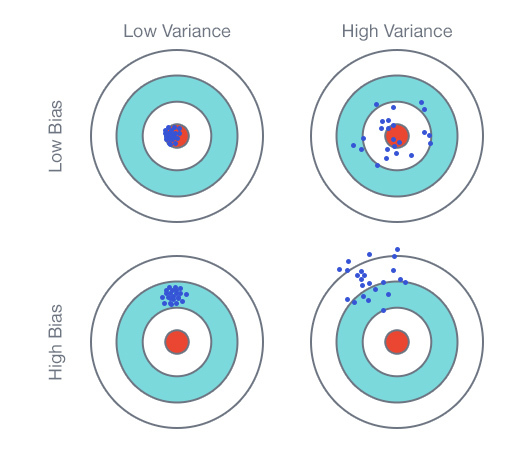
Привет, хабр! ![][1] Как и обещал, продолжаю публикацию статей, в которой описываю свой опыт после прохождения обучения по Data Science от ребят из [MLClass.ru][2] (кстати, кто еще не успел — [рекомендую зарегистрироваться][3]). В этот раз мы на примере задачи [Digit Recognizer][4] изучим влияние размера обучающей выборки на качество алгоритма машинного обучения. Это один из самых первых и основных вопросов, которые возникают при построении предиктивной модели [Читать дальше →][5]
[1]: https://habrastorage.org/files/60f/d96/61c/60fd9661cf9944bf890193af5e035a5e.jpg
[2]: http://dscourse.mlclass.ru
[3]: http://dscourse.mlclass.ru
[4]: https://www.kaggle.com/c/digit-recognizer
[5]: http://habrahabr.ru/post/266727/#habracut
habrabot(difrex,1) — All
2015-09-12 15:30:03
Привет, хабр! ![][1] Как и обещал, продолжаю публикацию статей, в которой описываю свой опыт после прохождения обучения по Data Science от ребят из [MLClass.ru][2] (кстати, кто еще не успел — [рекомендую зарегистрироваться][3]). В этот раз мы на примере задачи [Digit Recognizer][4] изучим влияние размера обучающей выборки на качество алгоритма машинного обучения. Это один из самых первых и основных вопросов, которые возникают при построении предиктивной модели [Читать дальше →][5]
[1]: https://habrastorage.org/files/60f/d96/61c/60fd9661cf9944bf890193af5e035a5e.jpg
{kind=link}
[2]: http://dscourse.mlclass.ru
[3]: http://dscourse.mlclass.ru
[4]: https://www.kaggle.com/c/digit-recognizer
[5]: http://habrahabr.ru/post/266727/#habracut