|
|
Login |
[>]
A fistful of relays. Часть 4. Система команд или что можно уместить в 8 машинных инструкций?
habra.16
habrabot(difrex,1) — All
2017-06-21 11:00:04
Наконец-то можно запустить в моём компьютере на электромагнитных реле программу длиннее одной инструкции. Сейчас в нём есть ПЗУ на 8 команд, процессор с АЛУ и 8 восьмибитных регистров (один из которых PC).
Всего процессор поддерживает 5 групп инструкций: Арифметико-логические операции (ALU), Загрузка числа в регистр (MOVI), пересылка между регистрами (MOV), Остановка работы (HALT), Работа с памятью (LDST). Но есть нюансы…
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331208/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-21 11:00:04
Наконец-то можно запустить в моём компьютере на электромагнитных реле программу длиннее одной инструкции. Сейчас в нём есть ПЗУ на 8 команд, процессор с АЛУ и 8 восьмибитных регистров (один из которых PC).
Всего процессор поддерживает 5 групп инструкций: Арифметико-логические операции (ALU), Загрузка числа в регистр (MOVI), пересылка между регистрами (MOV), Остановка работы (HALT), Работа с памятью (LDST). Но есть нюансы…
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331208/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Два года с Dart: о том, как мы пишем на языке, который ежегодно «хоронят» (часть 2)
habra.16
habrabot(difrex,1) — All
2017-06-21 13:30:04
![][1]
Продолжаем наше интервью с менеджером по разработке [Wrike][2] Игорем Демьяновым. Сегодня поговорим о перспективах языка, его развитии и улучшении инструментов, а также попробуем ответить на вопрос «Dart Шреденгира»: жив все-таки или умер язык, можно ли безбоязненно использовать его в своих проектах.
[Читать дальше →][3]
[1]: https://habrastorage.org/files/d41/0e5/717/d410e571775842ca9047e1d568171552.jpg
[2]: http://wrike.com/ru
[3]: https://habrahabr.ru/post/330900/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-21 13:30:04
![][1]
Продолжаем наше интервью с менеджером по разработке [Wrike][2] Игорем Демьяновым. Сегодня поговорим о перспективах языка, его развитии и улучшении инструментов, а также попробуем ответить на вопрос «Dart Шреденгира»: жив все-таки или умер язык, можно ли безбоязненно использовать его в своих проектах.
[Читать дальше →][3]
[1]: https://habrastorage.org/files/d41/0e5/717/d410e571775842ca9047e1d568171552.jpg
{kind=link}
[2]: http://wrike.com/ru
[3]: https://habrahabr.ru/post/330900/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] LSTM – сети долгой краткосрочной памяти
habra.16
habrabot(difrex,1) — All
2017-06-21 15:00:06
![][1]
## Рекуррентные нейронные сети
Люди не начинают думать с чистого листа каждую секунду. Читая этот пост, вы понимаете каждое слово, основываясь на понимании предыдущего слова. Мы не выбрасываем из головы все и не начинаем думать с нуля. Наши мысли обладают постоянством.
Традиционные нейронные сети не обладают этим свойством, и в этом их главный недостаток. Представим, например, что мы хотим классифицировать события, происходящие в фильме. Непонятно, как традиционная нейронная сеть могла бы использовать рассуждения о предыдущих событиях фильма, чтобы получить информацию о последующих.
Решить эту проблемы помогают рекуррентые нейронные сети (Recurrent Neural Networks, RNN). Это сети, содержащие обратные связи и позволяющие сохранять информацию.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/5f3/60f/ec1/5f360fec1bc24f9f973f7d1d3bded6c6.jpg
[2]: https://habrahabr.ru/post/331310/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-21 15:00:06
![][1]
## Рекуррентные нейронные сети
Люди не начинают думать с чистого листа каждую секунду. Читая этот пост, вы понимаете каждое слово, основываясь на понимании предыдущего слова. Мы не выбрасываем из головы все и не начинаем думать с нуля. Наши мысли обладают постоянством.
Традиционные нейронные сети не обладают этим свойством, и в этом их главный недостаток. Представим, например, что мы хотим классифицировать события, происходящие в фильме. Непонятно, как традиционная нейронная сеть могла бы использовать рассуждения о предыдущих событиях фильма, чтобы получить информацию о последующих.
Решить эту проблемы помогают рекуррентые нейронные сети (Recurrent Neural Networks, RNN). Это сети, содержащие обратные связи и позволяющие сохранять информацию.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/5f3/60f/ec1/5f360fec1bc24f9f973f7d1d3bded6c6.jpg
{kind=link}
[2]: https://habrahabr.ru/post/331310/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Магия SSH
habra.16
habrabot(difrex,1) — All
2017-06-21 20:00:09
С SSH многие знакомы давно, но, как и я, не все подозревают о том, какие возможности таятся за этими магическими тремя буквами. Хотел бы поделиться своим небольшим опытом использования SSH для решения различных административных задач.
Оглавление:
1) [Local TCP forwarding][1]
2) [Remote TCP forwarding][2]
3) [TCP forwarding chain через несколько узлов][3]
4) [TCP forwarding ssh-соединения][4]
5) [SSH VPN Tunnel][5]
6) [Коротко о беспарольном доступе][6]
7) [Спасибо (ссылки)][7]
[Читать дальше →][8]
[1]: #t1
[2]: #t2
[3]: #t3
[4]: #t4
[5]: #t5
[6]: #t6
[7]: #t7
[8]: https://habrahabr.ru/post/331348/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-21 20:00:09
С SSH многие знакомы давно, но, как и я, не все подозревают о том, какие возможности таятся за этими магическими тремя буквами. Хотел бы поделиться своим небольшим опытом использования SSH для решения различных административных задач.
Оглавление:
1) [Local TCP forwarding][1]
2) [Remote TCP forwarding][2]
3) [TCP forwarding chain через несколько узлов][3]
4) [TCP forwarding ssh-соединения][4]
5) [SSH VPN Tunnel][5]
6) [Коротко о беспарольном доступе][6]
7) [Спасибо (ссылки)][7]
[Читать дальше →][8]
[1]: #t1
[2]: #t2
[3]: #t3
[4]: #t4
[5]: #t5
[6]: #t6
[7]: #t7
[8]: https://habrahabr.ru/post/331348/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
UNIGINE С++ School: бесплатный онлайн-курс для продвинутых
habra.16
habrabot(difrex,1) — All
2017-06-22 02:30:04
В феврале мы запустили [бесплатный онлайн-курс ][1]программирования на С++, рассчитанный на продвинутых разработчиков. Цели было в основном две — сделать так, чтобы в мире было больше хороших программистов, а заодно набрать себе пополнение в команду. Идея взлетела: участвовать в первом наборе захотело 185 человек из 57 городов и 8 стран. В курсанты попало 30 из них, но со словами «неинтересно» ушёл только 1. Остальные по итогам курса сообщили, что было в целом круто и они с пользой провели время.
![][2]
Обкатав всю затею и учебный процесс на начальном бета-наборе, мы решили повторить курс ещё раз. Набор уже во всю идёт, подать заявку можно до понедельника, 26 июня. Чему, как и кто учит — рассказываем внутри. [Читать дальше →][3]
[1]: http://cpp-school.unigine.com?utm_source=habrahabr&utm_medium=post&utm_campaign=cpp_school_1_1
[2]: https://habrastorage.org/web/72b/8ea/e75/72b8eae750b6419aaa7161f037eb24c5.PNG
[3]: https://habrahabr.ru/post/331330/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 02:30:04
В феврале мы запустили [бесплатный онлайн-курс ][1]программирования на С++, рассчитанный на продвинутых разработчиков. Цели было в основном две — сделать так, чтобы в мире было больше хороших программистов, а заодно набрать себе пополнение в команду. Идея взлетела: участвовать в первом наборе захотело 185 человек из 57 городов и 8 стран. В курсанты попало 30 из них, но со словами «неинтересно» ушёл только 1. Остальные по итогам курса сообщили, что было в целом круто и они с пользой провели время.
![][2]
Обкатав всю затею и учебный процесс на начальном бета-наборе, мы решили повторить курс ещё раз. Набор уже во всю идёт, подать заявку можно до понедельника, 26 июня. Чему, как и кто учит — рассказываем внутри. [Читать дальше →][3]
[1]: http://cpp-school.unigine.com?utm_source=habrahabr&utm_medium=post&utm_campaign=cpp_school_1_1
[2]: https://habrastorage.org/web/72b/8ea/e75/72b8eae750b6419aaa7161f037eb24c5.PNG
{kind=link}
[3]: https://habrahabr.ru/post/331330/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Полезные функции Google Таблиц, которых нет в Excel
habra.16
habrabot(difrex,1) — All
2017-06-22 08:00:04
_Cтатья написана в соавторстве с Ренатом Шагабутдиновым._
![image][1]
В этой статье речь пойдет о нескольких очень полезных функциях Google Таблиц, которых нет в Excel (SORT, объединение массивов, FILTER, IMPORTRANGE, IMAGE, GOOGLETRANSLATE, DETECTLANGUAGE)
Очень много букв, но есть разборы интересных кейсов, все примеры, кстати, можно рассмотреть поближе в Google Документе [goo.gl/cOQAd9][2] (файл-> создать копию, чтобы скопировать файл себе на Google Диск и иметь возможность редактирования).
[Читать дальше →][3]
[1]: https://habrastorage.org/getpro/habr/post_images/3b9/ac9/ef8/3b9ac9ef855db70ed71b1baada210f8d.png
[2]: https://goo.gl/cOQAd9
[3]: https://habrahabr.ru/post/331360/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 08:00:04
_Cтатья написана в соавторстве с Ренатом Шагабутдиновым._
![image][1]
В этой статье речь пойдет о нескольких очень полезных функциях Google Таблиц, которых нет в Excel (SORT, объединение массивов, FILTER, IMPORTRANGE, IMAGE, GOOGLETRANSLATE, DETECTLANGUAGE)
Очень много букв, но есть разборы интересных кейсов, все примеры, кстати, можно рассмотреть поближе в Google Документе [goo.gl/cOQAd9][2] (файл-> создать копию, чтобы скопировать файл себе на Google Диск и иметь возможность редактирования).
[Читать дальше →][3]
[1]: https://habrastorage.org/getpro/habr/post_images/3b9/ac9/ef8/3b9ac9ef855db70ed71b1baada210f8d.png
{kind=link}
[2]: https://goo.gl/cOQAd9
[3]: https://habrahabr.ru/post/331360/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Программа PYCON RUSSIA готова: 25 докладов от спикеров из Disney, Facebook, Spotify, PyPy, Тинькофф Банк, Яндекс
habra.16
habrabot(difrex,1) — All
2017-06-22 08:30:05
Осталось чуть меньше месяца до пятого российского [PyConRu][1]. Конференция пройдет 16-17 июля в отеле «Cronwell Яхонты Таруса» в 95 км от Москвы (до места проведения и обратно будет трансфер).
В программе сейчас 25 докладов. Вот некоторые из спикеров: Paul Hildebrandt (Walt Disney Animation Studios, США), Łukasz Langa (Facebook, США), Nina Zakharenko (Venmo, США), Lynn Root (Spotify, США), Maciej Fijałkowski (PyPy, ЮАР), Андрей Степанов (Тинькофф Банк), Александр Кошкин (Positive Technologies), Кирилл Борисов (Яндекс), Елизавета Шашкова (JetBrains), Михаил Юматов (ЦИАН), Игорь Новиков (Scalr), Олег Чуркин (Rambler&Co).
До 30 июня билет стоит 15 500 рублей. Потом стоимость повышается. Самое время посмотреть на программу и зарегистрироваться, если вы откладывали это. Под катом коротко о всех докладах конференции.
![][2]
[Читать дальше →][3]
[1]: http://pycon.ru/2017/program/content/?utm_source=habr&utm_medium=post&utm_campaign=21.06
[2]: https://habrastorage.org/web/6f4/477/481/6f4477481e534588af991c9e53e8f8a0.png
[3]: https://habrahabr.ru/post/331336/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 08:30:05
Осталось чуть меньше месяца до пятого российского [PyConRu][1]. Конференция пройдет 16-17 июля в отеле «Cronwell Яхонты Таруса» в 95 км от Москвы (до места проведения и обратно будет трансфер).
В программе сейчас 25 докладов. Вот некоторые из спикеров: Paul Hildebrandt (Walt Disney Animation Studios, США), Łukasz Langa (Facebook, США), Nina Zakharenko (Venmo, США), Lynn Root (Spotify, США), Maciej Fijałkowski (PyPy, ЮАР), Андрей Степанов (Тинькофф Банк), Александр Кошкин (Positive Technologies), Кирилл Борисов (Яндекс), Елизавета Шашкова (JetBrains), Михаил Юматов (ЦИАН), Игорь Новиков (Scalr), Олег Чуркин (Rambler&Co).
До 30 июня билет стоит 15 500 рублей. Потом стоимость повышается. Самое время посмотреть на программу и зарегистрироваться, если вы откладывали это. Под катом коротко о всех докладах конференции.
![][2]
[Читать дальше →][3]
[1]: http://pycon.ru/2017/program/content/?utm_source=habr&utm_medium=post&utm_campaign=21.06
[2]: https://habrastorage.org/web/6f4/477/481/6f4477481e534588af991c9e53e8f8a0.png
{kind=link}
[3]: https://habrahabr.ru/post/331336/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Настройка сервера для проекта (Nginx, PHP-FPM, Elasticsearch, RabbitMQ)
habra.16
habrabot(difrex,1) — All
2017-06-22 09:00:04
Порой начиная новый проект мы примерно заранее знаем какие инструменты нам могут понадобиться.
Перед началом нового проекта я построил план работ, подобрал набор программ и решил подготовить небольшую и краткую инструкцию.
В качестве системы виртуализации я выбрать VMware Workstation.
## Подготовка сервера
1. ОС: CentOS 7
2. Сервер для анализа и поиска данных: Elasticsearch
3. Сервер очередей: RabbitMQ
4. Веб сервер: Nginx + PHP7 FPM
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331396/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 09:00:04
Порой начиная новый проект мы примерно заранее знаем какие инструменты нам могут понадобиться.
Перед началом нового проекта я построил план работ, подобрал набор программ и решил подготовить небольшую и краткую инструкцию.
В качестве системы виртуализации я выбрать VMware Workstation.
## Подготовка сервера
1. ОС: CentOS 7
2. Сервер для анализа и поиска данных: Elasticsearch
3. Сервер очередей: RabbitMQ
4. Веб сервер: Nginx + PHP7 FPM
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331396/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Волшебное введение в алгоритмы классификации
habra.16
habrabot(difrex,1) — All
2017-06-22 12:30:05
_Перевод [статьи ][1]Брайна Беренда._
Когда вы впервые приступаете к изучению теории анализа и обработки данных, то одними из первых вы изучаете алгоритмы классификации. Их суть проста: берётся информация о конкретном результате наблюдений (data point), на основании которой этот результат относится к определённой группе или классу.
Хороший пример — спам-фильтр электронной почты. Он должен помечать входящие письма (то есть результаты наблюдений) как «спам» или «не спам», ориентируясь на информацию о письмах (отправитель, количество слов, начинающихся с прописных букв, и так далее).
![][2]
Это пример хороший, но скучный. Спам-классификацию приводят в качестве примера на лекциях, презентациях и конференциях, так что вы наверняка уже не раз слышали о нём. Но что если поговорить о другом, более интересном алгоритме классификации? Каком-то более странном? Более… волшебном?
Всё верно! Сегодня мы поговорим о Распределяющей шляпе (Sorting Hat) из мира Гарри Поттера. Возьмём какие-то данные из сети, проанализируем и создадим классификатор, который будет сортировать персонажей по разным факультетам. Должно получиться забавно!
[Читать дальше →][3]
[1]: http://blog.yhat.com/posts/harry-potter-classification.html
[2]: https://habrastorage.org/web/420/b08/cd7/420b08cd728844a3863b0f7ae19b9ec0.png
[3]: https://habrahabr.ru/post/331352/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 12:30:05
_Перевод [статьи ][1]Брайна Беренда._
Когда вы впервые приступаете к изучению теории анализа и обработки данных, то одними из первых вы изучаете алгоритмы классификации. Их суть проста: берётся информация о конкретном результате наблюдений (data point), на основании которой этот результат относится к определённой группе или классу.
Хороший пример — спам-фильтр электронной почты. Он должен помечать входящие письма (то есть результаты наблюдений) как «спам» или «не спам», ориентируясь на информацию о письмах (отправитель, количество слов, начинающихся с прописных букв, и так далее).
![][2]
Это пример хороший, но скучный. Спам-классификацию приводят в качестве примера на лекциях, презентациях и конференциях, так что вы наверняка уже не раз слышали о нём. Но что если поговорить о другом, более интересном алгоритме классификации? Каком-то более странном? Более… волшебном?
Всё верно! Сегодня мы поговорим о Распределяющей шляпе (Sorting Hat) из мира Гарри Поттера. Возьмём какие-то данные из сети, проанализируем и создадим классификатор, который будет сортировать персонажей по разным факультетам. Должно получиться забавно!
[Читать дальше →][3]
[1]: http://blog.yhat.com/posts/harry-potter-classification.html
[2]: https://habrastorage.org/web/420/b08/cd7/420b08cd728844a3863b0f7ae19b9ec0.png
{kind=link}
[3]: https://habrahabr.ru/post/331352/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Реализация алгоритма A*
habra.16
habrabot(difrex,1) — All
2017-06-22 12:30:05
![][1]
Эта статья является продолжением моего [введения в алгоритм A\*][2]. В ней я показал, как реализуются поиск в ширину, алгоритм Дейкстры, жадный поиск по наилучшему первому совпадению и A\*. Я стремился как можно больше упростить объяснение.
Поиск по графам — это семейство схожих алгоритмов. Существует _множество_ вариаций алгоритов и их реализаций. Относитесь к коду этой статьи как к отправной точке, а не окончательной версии алгоритма, подходящей ко всем ситуациям.
[Читать дальше →][3]
[1]: https://habrastorage.org/web/3a8/810/442/3a8810442f124277a2a6d38536ea534a.png
[2]: https://habrahabr.ru/post/331192/
[3]: https://habrahabr.ru/post/331220/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 12:30:05
![][1]
Эта статья является продолжением моего [введения в алгоритм A\*][2]. В ней я показал, как реализуются поиск в ширину, алгоритм Дейкстры, жадный поиск по наилучшему первому совпадению и A\*. Я стремился как можно больше упростить объяснение.
Поиск по графам — это семейство схожих алгоритмов. Существует _множество_ вариаций алгоритов и их реализаций. Относитесь к коду этой статьи как к отправной точке, а не окончательной версии алгоритма, подходящей ко всем ситуациям.
[Читать дальше →][3]
[1]: https://habrastorage.org/web/3a8/810/442/3a8810442f124277a2a6d38536ea534a.png
{kind=link}
[2]: https://habrahabr.ru/post/331192/
[3]: https://habrahabr.ru/post/331220/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Приглашаем на Science Slam Digital 7 июля
habra.16
habrabot(difrex,1) — All
2017-06-22 14:30:13
![image][1]
Научные конференции — это нужное и важное дело, но зачастую они проходят в слишком академической атмосфере. Поэтому мы приглашаем студентов IT-специальностей, профессионалов в сфере IT и просто любителей высоких технологий на Science Slam Digital. Это сражение цифровых и технологических умов: молодые ученые и профессионалы в живой форме рассказывают о своих проектах. Только в нашем случае это будут сотрудники компании, которые расскажут о том, с какими технологиями они работают или какие создают ежедневно. То есть их задача — не просто рассказать о чём-то интересном, но и сделать это увлекательно. Победители в каждом поединке определяются аплодисментами зрителей и голосами тех, кто будет смотреть интернет-трансляцию через VK-Live. По результатам будут объявлены два победителя. Программу Science Slam Digital смотрите под катом.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/175/d62/df1/175d62df12344139a2bc202b08dde695.jpg
[2]: https://habrahabr.ru/post/331422/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 14:30:13
![image][1]
Научные конференции — это нужное и важное дело, но зачастую они проходят в слишком академической атмосфере. Поэтому мы приглашаем студентов IT-специальностей, профессионалов в сфере IT и просто любителей высоких технологий на Science Slam Digital. Это сражение цифровых и технологических умов: молодые ученые и профессионалы в живой форме рассказывают о своих проектах. Только в нашем случае это будут сотрудники компании, которые расскажут о том, с какими технологиями они работают или какие создают ежедневно. То есть их задача — не просто рассказать о чём-то интересном, но и сделать это увлекательно. Победители в каждом поединке определяются аплодисментами зрителей и голосами тех, кто будет смотреть интернет-трансляцию через VK-Live. По результатам будут объявлены два победителя. Программу Science Slam Digital смотрите под катом.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/175/d62/df1/175d62df12344139a2bc202b08dde695.jpg
{kind=link}
[2]: https://habrahabr.ru/post/331422/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Запускаем GSM сеть у себя дома
habra.16
habrabot(difrex,1) — All
2017-06-22 15:00:05
![][1]
В данной статье я хотел бы подробно описать, как мне удалось запустить собственную GSM сеть при помощи Osmocom и скромных вложениях в оборудование.
Инструкции на официальном сайте устарели и мне пришлось потратить довольно много времени на их адаптацию. К счастью все проблемы были решены, и, если вы будете строго следовать советам ниже, то и у Вас все получится.
В результате мы запустим экспериментальную 2G сотовую сеть в пределах комнаты с поддержкой СМС и голосовых вызовов, без GPRS. Ее можно будет использовать для изучения работы и взаимодействия устройств и компонентов GSM сети, не вмешиваясь в коммерческие сотовые сети.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/082/ec0/862/082ec0862edf4dda80bcce3720d55e96.jpg
[2]: https://habrahabr.ru/post/331406/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 15:00:05
![][1]
В данной статье я хотел бы подробно описать, как мне удалось запустить собственную GSM сеть при помощи Osmocom и скромных вложениях в оборудование.
Инструкции на официальном сайте устарели и мне пришлось потратить довольно много времени на их адаптацию. К счастью все проблемы были решены, и, если вы будете строго следовать советам ниже, то и у Вас все получится.
В результате мы запустим экспериментальную 2G сотовую сеть в пределах комнаты с поддержкой СМС и голосовых вызовов, без GPRS. Ее можно будет использовать для изучения работы и взаимодействия устройств и компонентов GSM сети, не вмешиваясь в коммерческие сотовые сети.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/082/ec0/862/082ec0862edf4dda80bcce3720d55e96.jpg
{kind=link}
[2]: https://habrahabr.ru/post/331406/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Финал конкурса SAP Кодер 2017 пройдёт в прямом эфире
habra.16
habrabot(difrex,1) — All
2017-06-22 16:30:04
В начале апреля мы анонсировали конкурс [«SAP Кодер»][1]. Участники должны были предложить свои проекты по заданным направлениям, сделанные на базе SAP Cloud Platform. Всё это время участники готовили свои решения — и вот настало время их презентовать. Решения получились интересные, поэтому мы предлагаем вам присоединиться к просмотру. Кроме презентации участников, вы услышите два доклада о SAP, которые обозначат передовые тренды в разработке. Узнайте подробности под катом и не забудьте присоединиться!
[![image][2]][3]
[Читать дальше →][4]
[1]: http://sapcoder.ru/
[2]: https://habrastorage.org/files/092/d48/470/092d484705c2440288b86d44d24aeabc.jpg
[3]: https://habrahabr.ru/company/sap/blog/331428/
[4]: https://habrahabr.ru/post/331428/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 16:30:04
В начале апреля мы анонсировали конкурс [«SAP Кодер»][1]. Участники должны были предложить свои проекты по заданным направлениям, сделанные на базе SAP Cloud Platform. Всё это время участники готовили свои решения — и вот настало время их презентовать. Решения получились интересные, поэтому мы предлагаем вам присоединиться к просмотру. Кроме презентации участников, вы услышите два доклада о SAP, которые обозначат передовые тренды в разработке. Узнайте подробности под катом и не забудьте присоединиться!
[![image][2]][3]
[Читать дальше →][4]
[1]: http://sapcoder.ru/
[2]: https://habrastorage.org/files/092/d48/470/092d484705c2440288b86d44d24aeabc.jpg
{kind=link}
[3]: https://habrahabr.ru/company/sap/blog/331428/
[4]: https://habrahabr.ru/post/331428/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Запускаем GSM-сеть у себя дома
habra.16
habrabot(difrex,1) — All
2017-06-22 17:30:05
![][1]
В данной статье я хотел бы подробно описать, как мне удалось запустить собственную GSM сеть при помощи Osmocom и скромных вложениях в оборудование.
Инструкции на официальном сайте устарели и мне пришлось потратить довольно много времени на их адаптацию. К счастью все проблемы были решены, и, если вы будете строго следовать советам ниже, то и у Вас все получится.
В результате мы запустим экспериментальную 2G сотовую сеть в пределах комнаты с поддержкой СМС и голосовых вызовов, без GPRS. Ее можно будет использовать для изучения работы и взаимодействия устройств и компонентов GSM сети, не вмешиваясь в коммерческие сотовые сети.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/082/ec0/862/082ec0862edf4dda80bcce3720d55e96.jpg
[2]: https://habrahabr.ru/post/331406/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-22 17:30:05
![][1]
В данной статье я хотел бы подробно описать, как мне удалось запустить собственную GSM сеть при помощи Osmocom и скромных вложениях в оборудование.
Инструкции на официальном сайте устарели и мне пришлось потратить довольно много времени на их адаптацию. К счастью все проблемы были решены, и, если вы будете строго следовать советам ниже, то и у Вас все получится.
В результате мы запустим экспериментальную 2G сотовую сеть в пределах комнаты с поддержкой СМС и голосовых вызовов, без GPRS. Ее можно будет использовать для изучения работы и взаимодействия устройств и компонентов GSM сети, не вмешиваясь в коммерческие сотовые сети.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/082/ec0/862/082ec0862edf4dda80bcce3720d55e96.jpg
[2]: https://habrahabr.ru/post/331406/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Это вопрос должен решать архитектор. Или нет?
habra.16
habrabot(difrex,1) — All
2017-06-23 01:30:04
У меня есть некоторый опыт в реализации систем на базе микросервисной архитектуры и я хотел бы поделится вопросами (и ответами), которые возникают при реализации подобных проектов. К сожалению, я не имею права распространяться о проектах в которых я участвовал, поэтому я выдумал собственный сферический проект в вакууме. В этом проекте нам встретится множество стандартных проблем.
Хочу сразу заметить, что имплементация будет рудиментарной и служит только базой для постановки вопросов. В любом случае, я надеюсь, вы найдете в статье пару интересных мыслей и ссылок.
Мы увидим, сколько интересных моментов могут возникнуть при написании всего трех классов и зададимся вопросом, должен ли в данном случае принимать решение архитектор или разработчик может решить эту проблему сам.
![image][1]
[Читать дальше →][2]
[1]: https://habrastorage.org/web/ec0/eff/85f/ec0eff85f4dd4381a9ab6076cefa05ef.jpg
[2]: https://habrahabr.ru/post/331104/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 01:30:04
У меня есть некоторый опыт в реализации систем на базе микросервисной архитектуры и я хотел бы поделится вопросами (и ответами), которые возникают при реализации подобных проектов. К сожалению, я не имею права распространяться о проектах в которых я участвовал, поэтому я выдумал собственный сферический проект в вакууме. В этом проекте нам встретится множество стандартных проблем.
Хочу сразу заметить, что имплементация будет рудиментарной и служит только базой для постановки вопросов. В любом случае, я надеюсь, вы найдете в статье пару интересных мыслей и ссылок.
Мы увидим, сколько интересных моментов могут возникнуть при написании всего трех классов и зададимся вопросом, должен ли в данном случае принимать решение архитектор или разработчик может решить эту проблему сам.
![image][1]
[Читать дальше →][2]
[1]: https://habrastorage.org/web/ec0/eff/85f/ec0eff85f4dd4381a9ab6076cefa05ef.jpg
{kind=link}
[2]: https://habrahabr.ru/post/331104/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Виртуальные твари и места их обитания: прошлое и настоящее TTY в Linux
habra.16
habrabot(difrex,1) — All
2017-06-23 11:30:04
![][1]Ubuntu интегрирована в Windows 10 Redstone, Visual Studio 2017 обзавелась поддержкой разработки под Linux – даже Microsoft сдает позиции в пользу растущего числа сторонников Торвальдса, а ты всё еще не знаешь тайны виртуального терминала в современных дистрибутивах?
Хочешь исправить этот пробел и открываешь исходный код? TTY, MASTER, SLAVE, N\_TTY, VT, PTS, PTMX… Нагромождение понятий, виртуальных устройств и беспорядочная магия? Всё это складывается в довольно логичную картину, если вспомнить, с чего всё началось…
[Читать дальше →][2]
[1]: https://habrastorage.org/web/e86/4ed/36b/e864ed36bd8144ec84b264c7b941ccab.jpg
[2]: https://habrahabr.ru/post/330764/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 11:30:04
![][1]Ubuntu интегрирована в Windows 10 Redstone, Visual Studio 2017 обзавелась поддержкой разработки под Linux – даже Microsoft сдает позиции в пользу растущего числа сторонников Торвальдса, а ты всё еще не знаешь тайны виртуального терминала в современных дистрибутивах?
Хочешь исправить этот пробел и открываешь исходный код? TTY, MASTER, SLAVE, N\_TTY, VT, PTS, PTMX… Нагромождение понятий, виртуальных устройств и беспорядочная магия? Всё это складывается в довольно логичную картину, если вспомнить, с чего всё началось…
[Читать дальше →][2]
[1]: https://habrastorage.org/web/e86/4ed/36b/e864ed36bd8144ec84b264c7b941ccab.jpg
{kind=link}
[2]: https://habrahabr.ru/post/330764/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Apache Cassandra + Apache Ignite — как совместить лучшее
habra.16
habrabot(difrex,1) — All
2017-06-23 13:30:04
Apache Cassandra — это одна из популярных распределенных дисковых NoSQL баз данных с открытым исходным кодом. Она применяется в ключевых частях инфраструктуры такими гигантами как Netflix, eBay, Expedia, и снискала популярность за свою скорость, способность линейно масштабироваться на тысячи узлов и “best-in-class” репликацию между различными центрами обработки данных.
Apache Ignite — это In-Memory Computing Platform, платформа для распределенного хранения данных в оперативной памяти и распределенных вычислений по ним в реальном времени с поддержкой JCache, SQL99, ACID-транзакциями и базовой алгеброй машинного обучения.
Apache Cassandra является классическим решением в своей области. Как и в случае с любым специализированным решением, её преимущества достигнуты благодаря ряду компромиссов, значительная часть которых вызвана ограничениями дисковых хранилищ данных. Cassandra оптимизирована под максимально быструю работу с ними в ущерб остальному. Примеры компромиссов: отсутствие ACID-транзакций и поддержки SQL, невозможность произвольных транзакционных и аналитических транзакций, если под них заранее не адаптированы данные. Эти компромиссы, в свою очередь, вызывают закономерные затруднения у пользователей, приводя к некорректному использованию продукта и негативному опыту, либо вынуждая разделять данные между различными видами хранилищ, фрагментируя инфраструктуру и усложняя логику сохранения данных в приложениях.
Возможное решение проблемы — использование Cassandra в связке с Apache Ignite. Это позволит сохранить ключевые преимущества Cassandra, при этом скомпенсировав ее недостатки за счет симбиоза двух систем.
Как? Читайте дальше, и смотрите пример кода.
![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/web/795/159/f7f/795159f7fa344ac9a5952b27acb8a579.jpg
[2]: https://habrahabr.ru/post/329736/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 13:30:04
Apache Cassandra — это одна из популярных распределенных дисковых NoSQL баз данных с открытым исходным кодом. Она применяется в ключевых частях инфраструктуры такими гигантами как Netflix, eBay, Expedia, и снискала популярность за свою скорость, способность линейно масштабироваться на тысячи узлов и “best-in-class” репликацию между различными центрами обработки данных.
Apache Ignite — это In-Memory Computing Platform, платформа для распределенного хранения данных в оперативной памяти и распределенных вычислений по ним в реальном времени с поддержкой JCache, SQL99, ACID-транзакциями и базовой алгеброй машинного обучения.
Apache Cassandra является классическим решением в своей области. Как и в случае с любым специализированным решением, её преимущества достигнуты благодаря ряду компромиссов, значительная часть которых вызвана ограничениями дисковых хранилищ данных. Cassandra оптимизирована под максимально быструю работу с ними в ущерб остальному. Примеры компромиссов: отсутствие ACID-транзакций и поддержки SQL, невозможность произвольных транзакционных и аналитических транзакций, если под них заранее не адаптированы данные. Эти компромиссы, в свою очередь, вызывают закономерные затруднения у пользователей, приводя к некорректному использованию продукта и негативному опыту, либо вынуждая разделять данные между различными видами хранилищ, фрагментируя инфраструктуру и усложняя логику сохранения данных в приложениях.
Возможное решение проблемы — использование Cassandra в связке с Apache Ignite. Это позволит сохранить ключевые преимущества Cassandra, при этом скомпенсировав ее недостатки за счет симбиоза двух систем.
Как? Читайте дальше, и смотрите пример кода.
![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/web/795/159/f7f/795159f7fa344ac9a5952b27acb8a579.jpg
{kind=link}
[2]: https://habrahabr.ru/post/329736/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Марафонский раунд Яндекс.Алгоритма 2017
habra.16
habrabot(difrex,1) — All
2017-06-23 13:30:04
И вновь, как и в прошлые годы, приближается финал конкурса Яндекс.Алгоритм. В этом году мы ввели новый раунд — марафонский. Он представляет из себя одну оптимизационную задачу без точного решения, которую участникам предлагалось «покрутить» в течение 48 часов. Такой формат похож на решение практических задач больше, чем популярные соревнования по спортивному программированию.
![][1]
Особенностью большинства практических задач является отсутствие точного решения — или же алгоритмы его нахождения оказываются слишком медленными. Команде и отдельному разработчику нужно сделать хороший прототип решения, который будет внедряться в окончательный алгоритм. Задачи подобного рода давно встречаются в соревнованиях [TopCoder][2], ежегодных соревнованиях [Marathon24][3], [Deadline24][4], [Google Hash Code][5] и других. Конкурс длится больше стандартных алгоритмических раундов, так что участники могут в спокойной обстановке и в удобное для себя время реализовать придуманный метод.
Мы, организаторы Алгоритма, очень хотим, чтобы разноплановые участники могли успешно себя проявить. Поэтому добавление марафонского раунда рассматриваем как путь к расширению аудитории и популяризации таких соревнований.
Мы попросили участников, показавших лучший результат, объяснить, как они его достигли.
[Читать дальше →][6]
[1]: https://habrastorage.org/web/cd7/85c/dc5/cd785cdc50894c69b2044d9b96aaaa93.JPG
[2]: https://www.topcoder.com/member-onboarding/competing-in-data-science-challenges-marathon-matches/
[3]: https://www.marathon24.com/
[4]: https://www.deadline24.pl/
[5]: https://hashcode.withgoogle.com/
[6]: https://habrahabr.ru/post/331482/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 13:30:04
И вновь, как и в прошлые годы, приближается финал конкурса Яндекс.Алгоритм. В этом году мы ввели новый раунд — марафонский. Он представляет из себя одну оптимизационную задачу без точного решения, которую участникам предлагалось «покрутить» в течение 48 часов. Такой формат похож на решение практических задач больше, чем популярные соревнования по спортивному программированию.
![][1]
Особенностью большинства практических задач является отсутствие точного решения — или же алгоритмы его нахождения оказываются слишком медленными. Команде и отдельному разработчику нужно сделать хороший прототип решения, который будет внедряться в окончательный алгоритм. Задачи подобного рода давно встречаются в соревнованиях [TopCoder][2], ежегодных соревнованиях [Marathon24][3], [Deadline24][4], [Google Hash Code][5] и других. Конкурс длится больше стандартных алгоритмических раундов, так что участники могут в спокойной обстановке и в удобное для себя время реализовать придуманный метод.
Мы, организаторы Алгоритма, очень хотим, чтобы разноплановые участники могли успешно себя проявить. Поэтому добавление марафонского раунда рассматриваем как путь к расширению аудитории и популяризации таких соревнований.
Мы попросили участников, показавших лучший результат, объяснить, как они его достигли.
[Читать дальше →][6]
[1]: https://habrastorage.org/web/cd7/85c/dc5/cd785cdc50894c69b2044d9b96aaaa93.JPG
{kind=link}
[2]: https://www.topcoder.com/member-onboarding/competing-in-data-science-challenges-marathon-matches/
[3]: https://www.marathon24.com/
[4]: https://www.deadline24.pl/
[5]: https://hashcode.withgoogle.com/
[6]: https://habrahabr.ru/post/331482/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Где в ZX Spectrum системный монитор? Загадка ПЭВМ Дуэт
habra.16
habrabot(difrex,1) — All
2017-06-23 13:30:04
[ПЭВМ Дуэт][1] — это российский клон ZX Spectrum 48k, производился Лианозовским электромеханическим заводом (ЛЭМЗ). Это мой самый первый компьютер и он со мной до сих пор. С юного возраста я начал постигать на нем азы программирования, микропроцессорных архитектур и проектирования цифровых схем. Но с тех пор мне не давал покоя вопрос: где системный монитор? Ведь он упоминается в документации. В стандартном ZX Spectrum я не припомню наличия какого-либо системного монитора. И в документации про системный монитор больше ни слова. Существует Монитор для 48к [в ПЗУ версии от 1990г][2]. Однако, после включения, ПЭВМ Дуэт выводит на экран вместо стандартного приветствия — _"(с) 1982 sinclair research ltd"_ другое приветствие: _"(с) DUET"_. А это значит, что ПЗУ там всё же изменено. А может быть есть аппаратные возможности мониторинга? К примеру, клон [Орель БК-08][3] имеет целый ряд доработок: теневое ОЗУ, кнопка NMI и монитор MZ80. Было бы очень интересно, спустя столько лет, найти какие-то скрытые возможности своей железки.
Наконец-то я нашел ответ на вопрос, который меня периодически волновал все эти годы.
![image][4]
[Заняться цифровой археологией][5]
[1]: http://speccy.info/%D0%94%D1%83%D1%8D%D1%82
[2]: https://habrastorage.org/web/5da/4a4/ab5/5da4a4ab59f54b93a015d98fc06eaee6.jpg
[3]: https://ru.wikipedia.org/wiki/%D0%9E%D1%80%D0%B5%D0%BB%D1%8C_%D0%91%D0%9A-08
[4]: https://habrastorage.org/web/94e/259/0a8/94e2590a8eac42f9bff906fd123b83f0.jpg
[5]: https://habrahabr.ru/post/264913/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 13:30:04
[ПЭВМ Дуэт][1] — это российский клон ZX Spectrum 48k, производился Лианозовским электромеханическим заводом (ЛЭМЗ). Это мой самый первый компьютер и он со мной до сих пор. С юного возраста я начал постигать на нем азы программирования, микропроцессорных архитектур и проектирования цифровых схем. Но с тех пор мне не давал покоя вопрос: где системный монитор? Ведь он упоминается в документации. В стандартном ZX Spectrum я не припомню наличия какого-либо системного монитора. И в документации про системный монитор больше ни слова. Существует Монитор для 48к [в ПЗУ версии от 1990г][2]. Однако, после включения, ПЭВМ Дуэт выводит на экран вместо стандартного приветствия — _"(с) 1982 sinclair research ltd"_ другое приветствие: _"(с) DUET"_. А это значит, что ПЗУ там всё же изменено. А может быть есть аппаратные возможности мониторинга? К примеру, клон [Орель БК-08][3] имеет целый ряд доработок: теневое ОЗУ, кнопка NMI и монитор MZ80. Было бы очень интересно, спустя столько лет, найти какие-то скрытые возможности своей железки.
Наконец-то я нашел ответ на вопрос, который меня периодически волновал все эти годы.
![image][4]
[Заняться цифровой археологией][5]
[1]: http://speccy.info/%D0%94%D1%83%D1%8D%D1%82
[2]: https://habrastorage.org/web/5da/4a4/ab5/5da4a4ab59f54b93a015d98fc06eaee6.jpg
{kind=link}
[3]: https://ru.wikipedia.org/wiki/%D0%9E%D1%80%D0%B5%D0%BB%D1%8C_%D0%91%D0%9A-08
[4]: https://habrastorage.org/web/94e/259/0a8/94e2590a8eac42f9bff906fd123b83f0.jpg
{kind=link}
[5]: https://habrahabr.ru/post/264913/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Как провести розыгрыш призов среди Java программистов
habra.16
habrabot(difrex,1) — All
2017-06-23 13:30:04
Давно ли вы участвовали в лотерее или розыгрыше? Приходилось ли вам самим их устраивать? Даже если ответы: никогда и нет, уверен, что вы знаете что это такое.
А какие у вас ассоциации от слов «лотерея» и «розыгрыш»? У меня — разноцветные шары с номерами и лотерейная машина, из которой разноцветные шары выпадают по одному и определяют победителя.
Вот и мне некоторое время назад понадобилось “определить” победителей розыгрыша бесплатных места на курс “Разработчик Java” в [Otus.ru][1]. Задача звучала просто: есть N email-ов, нужно выбрать среди них случайным образом M email-ов тех, кто будет учиться бесплатно.
Сложность задачи была в том, что это были email-ы всех, кто успешно прошел входное тестирование курса. То есть email-ы программистов. Я представил себе, как я “достаю из кармана” M email-ов и говорю: “Вот эти победили”. И… мне никто не верит. Даже если победители начинают радостно писать в общий чат: “Спасибо, как мы рады!”, мне все равно никто из оставшихся не поверит. Да я бы и сам не поверил, если бы мне просто сказали «победили _эти_».
![image][2]
Программистам мало сказать кто победил, надо доказать что это действительно случайные победители, и что в общем списке действительно был их email, и что вероятность попасть в победители у всех равна.
[Читать дальше →][3]
[1]: http://otus.ru?utm_source=habr&utm_medium=affilate&utm_campaign=javapost&utm_term=javalotery
[2]: https://habrastorage.org/web/490/686/fad/490686fada654d87a50b660ffa5bbd67.jpg
[3]: https://habrahabr.ru/post/331478/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 13:30:04
Давно ли вы участвовали в лотерее или розыгрыше? Приходилось ли вам самим их устраивать? Даже если ответы: никогда и нет, уверен, что вы знаете что это такое.
А какие у вас ассоциации от слов «лотерея» и «розыгрыш»? У меня — разноцветные шары с номерами и лотерейная машина, из которой разноцветные шары выпадают по одному и определяют победителя.
Вот и мне некоторое время назад понадобилось “определить” победителей розыгрыша бесплатных места на курс “Разработчик Java” в [Otus.ru][1]. Задача звучала просто: есть N email-ов, нужно выбрать среди них случайным образом M email-ов тех, кто будет учиться бесплатно.
Сложность задачи была в том, что это были email-ы всех, кто успешно прошел входное тестирование курса. То есть email-ы программистов. Я представил себе, как я “достаю из кармана” M email-ов и говорю: “Вот эти победили”. И… мне никто не верит. Даже если победители начинают радостно писать в общий чат: “Спасибо, как мы рады!”, мне все равно никто из оставшихся не поверит. Да я бы и сам не поверил, если бы мне просто сказали «победили _эти_».
![image][2]
Программистам мало сказать кто победил, надо доказать что это действительно случайные победители, и что в общем списке действительно был их email, и что вероятность попасть в победители у всех равна.
[Читать дальше →][3]
[1]: http://otus.ru?utm_source=habr&utm_medium=affilate&utm_campaign=javapost&utm_term=javalotery
[2]: https://habrastorage.org/web/490/686/fad/490686fada654d87a50b660ffa5bbd67.jpg
{kind=link}
[3]: https://habrahabr.ru/post/331478/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Вехи истории шифрования и борьбы с ним
habra.16
habrabot(difrex,1) — All
2017-06-23 15:30:04
Шифрование — это тема, вокруг которой в последние годы постоянно кипят страсти. Производители устройств и программ встраивают в свои изделия системы защиты. Эти системы, с одной стороны, помогают обычным людям и организациям, с другой же — ими же пользуются и нарушители закона. Последнее ведёт к обеспокоенности спецслужб, которым, в идеале, хотелось бы, чтобы у них были ключи ко всем зашифрованным данным. Перед вами — рассказ о десяти событиях из истории шифрования и борьбы с ним.
[![][1]][2]
[Читать дальше →][3]
[1]: https://habrastorage.org/web/04a/014/e72/04a014e7206d49748d961c60e89c93c7.jpg
[2]: https://habrahabr.ru/company/ruvds/blog/331496/
[3]: https://habrahabr.ru/post/331496/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 15:30:04
Шифрование — это тема, вокруг которой в последние годы постоянно кипят страсти. Производители устройств и программ встраивают в свои изделия системы защиты. Эти системы, с одной стороны, помогают обычным людям и организациям, с другой же — ими же пользуются и нарушители закона. Последнее ведёт к обеспокоенности спецслужб, которым, в идеале, хотелось бы, чтобы у них были ключи ко всем зашифрованным данным. Перед вами — рассказ о десяти событиях из истории шифрования и борьбы с ним.
[![][1]][2]
[Читать дальше →][3]
[1]: https://habrastorage.org/web/04a/014/e72/04a014e7206d49748d961c60e89c93c7.jpg
{kind=link}
[2]: https://habrahabr.ru/company/ruvds/blog/331496/
[3]: https://habrahabr.ru/post/331496/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Челленджи марафонского раунда Яндекс.Алгоритма 2017
habra.16
habrabot(difrex,1) — All
2017-06-23 15:30:04
И вновь, как и в прошлые годы, приближается финал конкурса Яндекс.Алгоритм. В этом году мы ввели новый раунд — марафонский. Он представляет из себя одну оптимизационную задачу без точного решения, которую участникам предлагалось «покрутить» в течение 48 часов. Такой формат похож на решение практических задач больше, чем популярные соревнования по спортивному программированию.
![][1]
Особенностью большинства практических задач является отсутствие точного решения — или же алгоритмы его нахождения оказываются слишком медленными. Команде и отдельному разработчику нужно сделать хороший прототип решения, который будет внедряться в окончательный алгоритм. Задачи подобного рода давно встречаются в соревнованиях [TopCoder][2], ежегодных соревнованиях [Marathon24][3], [Deadline24][4], [Google Hash Code][5] и других. Конкурс длится больше стандартных алгоритмических раундов, так что участники могут в спокойной обстановке и в удобное для себя время реализовать придуманный метод.
Мы, организаторы Алгоритма, очень хотим, чтобы разноплановые участники могли успешно себя проявить. Поэтому добавление марафонского раунда рассматриваем как путь к расширению аудитории и популяризации таких соревнований.
Мы попросили участников, показавших лучший результат, объяснить, как они его достигли.
[Читать дальше →][6]
[1]: https://habrastorage.org/web/cd7/85c/dc5/cd785cdc50894c69b2044d9b96aaaa93.JPG
[2]: https://www.topcoder.com/member-onboarding/competing-in-data-science-challenges-marathon-matches/
[3]: https://www.marathon24.com/
[4]: https://www.deadline24.pl/
[5]: https://hashcode.withgoogle.com/
[6]: https://habrahabr.ru/post/331482/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 15:30:04
И вновь, как и в прошлые годы, приближается финал конкурса Яндекс.Алгоритм. В этом году мы ввели новый раунд — марафонский. Он представляет из себя одну оптимизационную задачу без точного решения, которую участникам предлагалось «покрутить» в течение 48 часов. Такой формат похож на решение практических задач больше, чем популярные соревнования по спортивному программированию.
![][1]
Особенностью большинства практических задач является отсутствие точного решения — или же алгоритмы его нахождения оказываются слишком медленными. Команде и отдельному разработчику нужно сделать хороший прототип решения, который будет внедряться в окончательный алгоритм. Задачи подобного рода давно встречаются в соревнованиях [TopCoder][2], ежегодных соревнованиях [Marathon24][3], [Deadline24][4], [Google Hash Code][5] и других. Конкурс длится больше стандартных алгоритмических раундов, так что участники могут в спокойной обстановке и в удобное для себя время реализовать придуманный метод.
Мы, организаторы Алгоритма, очень хотим, чтобы разноплановые участники могли успешно себя проявить. Поэтому добавление марафонского раунда рассматриваем как путь к расширению аудитории и популяризации таких соревнований.
Мы попросили участников, показавших лучший результат, объяснить, как они его достигли.
[Читать дальше →][6]
[1]: https://habrastorage.org/web/cd7/85c/dc5/cd785cdc50894c69b2044d9b96aaaa93.JPG
[2]: https://www.topcoder.com/member-onboarding/competing-in-data-science-challenges-marathon-matches/
[3]: https://www.marathon24.com/
[4]: https://www.deadline24.pl/
[5]: https://hashcode.withgoogle.com/
[6]: https://habrahabr.ru/post/331482/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
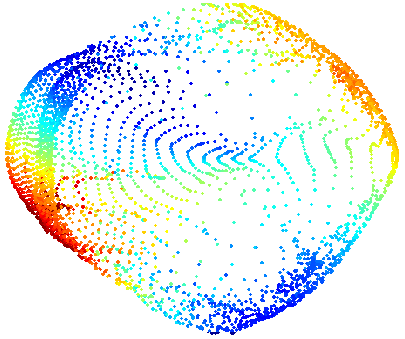
Автоэнкодеры в Keras, Часть 2: Manifold learning и скрытые (latent) переменные
habra.16
habrabot(difrex,1) — All
2017-06-23 16:30:04
### Содержание
* [Часть 1: Введение][1]
* **Часть 2: _Manifold learning_ и скрытые (_latent_) переменные**
* Часть 3: Вариационные автоэнкодеры (_VAE_)
* Часть 4: _Conditional VAE_
* Часть 5: _GAN_ (Generative Adversarial Networks) и tensorflow
* Часть 6: _VAE_ + _GAN_
![][2]
Для того, чтобы лучше понимать, как работают автоэнкодеры, а также чтобы в последствии генерировать из кодов что-то новое, стоит разобраться в том, что такое коды и как их можно интерпретировать.
[Читать дальше →][3]
[1]: https://habrahabr.ru/post/331382/
[2]: https://habrastorage.org/getpro/habr/post_images/46b/e14/15d/46be1415d995915a25aeb8fae24b8295.gif
[3]: https://habrahabr.ru/post/331500/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 16:30:04
### Содержание
* [Часть 1: Введение][1]
* **Часть 2: _Manifold learning_ и скрытые (_latent_) переменные**
* Часть 3: Вариационные автоэнкодеры (_VAE_)
* Часть 4: _Conditional VAE_
* Часть 5: _GAN_ (Generative Adversarial Networks) и tensorflow
* Часть 6: _VAE_ + _GAN_
![][2]
Для того, чтобы лучше понимать, как работают автоэнкодеры, а также чтобы в последствии генерировать из кодов что-то новое, стоит разобраться в том, что такое коды и как их можно интерпретировать.
[Читать дальше →][3]
[1]: https://habrahabr.ru/post/331382/
[2]: https://habrastorage.org/getpro/habr/post_images/46b/e14/15d/46be1415d995915a25aeb8fae24b8295.gif
{kind=link}
[3]: https://habrahabr.ru/post/331500/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Автоэнкодеры в Keras, Часть 1: Введение
habra.16
habrabot(difrex,1) — All
2017-06-23 20:00:03
# Автоэнкодеры в Keras
# Часть 1: Введение
### Содержание
* **Часть 1: Введение**
* [Часть 2: _Manifold learning_ и скрытые (_latent_) переменные][1]
* Часть 3: Вариационные автоэнкодеры (_VAE_)
* Часть 4: _Conditional VAE_
* Часть 5: _GAN_ (Generative Adversarial Networks) и tensorflow
* Часть 6: _VAE_ + _GAN_
Во время погружения в _Deep Learning_ зацепила меня тема автоэнкодеров, особенно с точки зрения генерации новых объектов. Стремясь улучшить качество генерации, читал различные блоги и литературу на тему генеративных подходов. В результате набравшийся опыт решил облечь в небольшую серию статей, в которой постарался кратко и с примерами описать все те проблемные места с которыми сталкивался сам, заодно вводя в синтаксис _Keras_.
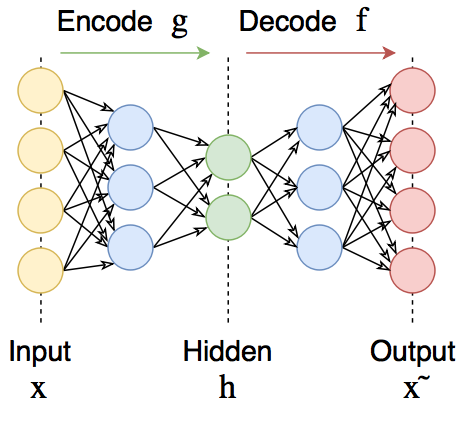
## Автоэнкодеры
**_Автоэнкодеры_** — это нейронные сети прямого распространения, которые восстанавливают входной сигнал на выходе. Внутри у них имеется скрытый слой, который представляет собой _код_, описывающий модель. _Автоэнкодеры_ конструируются таким образом, чтобы не иметь возможность точно скопировать вход на выходе. Обычно их ограничивают в размерности _кода_ (он меньше, чем размерность сигнала) или штрафуют за активации в _коде_. Входной сигнал восстанавливается с ошибками из-за потерь при кодировании, но, чтобы их минимизировать, сеть вынуждена учиться отбирать наиболее важные признаки.
![][2]
Кому интересно, добро пожаловать под кат
[Читать дальше →][3]
[1]: https://habrahabr.ru/post/331500/
[2]: https://habrastorage.org/web/cf6/228/613/cf6228613fdc4f8fb819cbd41bb677eb.png
[3]: https://habrahabr.ru/post/331382/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 20:00:03
# Автоэнкодеры в Keras
# Часть 1: Введение
### Содержание
* **Часть 1: Введение**
* [Часть 2: _Manifold learning_ и скрытые (_latent_) переменные][1]
* Часть 3: Вариационные автоэнкодеры (_VAE_)
* Часть 4: _Conditional VAE_
* Часть 5: _GAN_ (Generative Adversarial Networks) и tensorflow
* Часть 6: _VAE_ + _GAN_
Во время погружения в _Deep Learning_ зацепила меня тема автоэнкодеров, особенно с точки зрения генерации новых объектов. Стремясь улучшить качество генерации, читал различные блоги и литературу на тему генеративных подходов. В результате набравшийся опыт решил облечь в небольшую серию статей, в которой постарался кратко и с примерами описать все те проблемные места с которыми сталкивался сам, заодно вводя в синтаксис _Keras_.
## Автоэнкодеры
**_Автоэнкодеры_** — это нейронные сети прямого распространения, которые восстанавливают входной сигнал на выходе. Внутри у них имеется скрытый слой, который представляет собой _код_, описывающий модель. _Автоэнкодеры_ конструируются таким образом, чтобы не иметь возможность точно скопировать вход на выходе. Обычно их ограничивают в размерности _кода_ (он меньше, чем размерность сигнала) или штрафуют за активации в _коде_. Входной сигнал восстанавливается с ошибками из-за потерь при кодировании, но, чтобы их минимизировать, сеть вынуждена учиться отбирать наиболее важные признаки.
![][2]
Кому интересно, добро пожаловать под кат
[Читать дальше →][3]
[1]: https://habrahabr.ru/post/331500/
[2]: https://habrastorage.org/web/cf6/228/613/cf6228613fdc4f8fb819cbd41bb677eb.png
{kind=link}
[3]: https://habrahabr.ru/post/331382/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Как мы собрали 1500 звезд на Гитхабе, соединив проверенную временем технологию и новый интерфейс
habra.16
habrabot(difrex,1) — All
2017-06-23 23:30:03
![][1]
Недавно мы выпустили инструмент с открытым исходным кодом [GraphQL Voyager][2]. Удивительно, но он попал на первую страницу новостей Hacker News и GitHub, и в первые несколько дней получил 1000+ звезд. Сейчас у него уже более [1600 звезд][3].\*
Людям понравился гладкий интерфейс, интерактивные функции и анимация. Мы использовали TypeScript, React, Redux, webpack и даже PostCSS, но это **НЕ еще одна статья об этом**. Давайте заглянем под капот...
[Читать дальше →][4]
[1]: https://habrastorage.org/web/1c1/26f/51f/1c126f51fecb4a1eb1d7b35b8c875bb7.png
[2]: https://github.com/APIs-guru/graphql-voyager
[3]: https://github.com/APIs-guru/graphql-voyager/stargazers
[4]: https://habrahabr.ru/post/331514/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-23 23:30:03
![][1]
Недавно мы выпустили инструмент с открытым исходным кодом [GraphQL Voyager][2]. Удивительно, но он попал на первую страницу новостей Hacker News и GitHub, и в первые несколько дней получил 1000+ звезд. Сейчас у него уже более [1600 звезд][3].\*
Людям понравился гладкий интерфейс, интерактивные функции и анимация. Мы использовали TypeScript, React, Redux, webpack и даже PostCSS, но это **НЕ еще одна статья об этом**. Давайте заглянем под капот...
[Читать дальше →][4]
[1]: https://habrastorage.org/web/1c1/26f/51f/1c126f51fecb4a1eb1d7b35b8c875bb7.png
{kind=link}
[2]: https://github.com/APIs-guru/graphql-voyager
[3]: https://github.com/APIs-guru/graphql-voyager/stargazers
[4]: https://habrahabr.ru/post/331514/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
В сеть утекли исходные коды операционной системы Windows 10 [маленькая часть]
habra.16
habrabot(difrex,1) — All
2017-06-24 11:30:05
**UPD** Выяснилось, что theregister все [сильно преувеличил][1].
![image][2]
По информации портала [theregister.co.uk][3] недавно произошла массивная утечка приватных билдов ОС Windows 10 и фрагментов ее исходных кодов.
Массив из 32 терабайтов данных (в архивированном виде — 8 терабайт), состоящий из официальных и приватных образов, закрытой технической документации и исходных текстов, [оказался загруженным][4] на ресурс betaarchive.com
Предполагается, что конфиденциальные данные в этом дампе были нелегально скопированы из внутреннего хранилища Microsoft приблизительно в марте 2017 года.
По сообщениям людей, успевших ознакомиться с материалами внушительного архива, утекшие исходные коды в нем относятся к Microsoft's Shared Source Kit. Этот набор включает в себя исходники базовых драйверов Windows 10, стеков Wi-Fi,USB и PnP, драйверов систем хранения и ARM-версии ядра OneCore.
На данный момент имеются все предпосылки того, что инцидент окажется не менее значительным, чем в свое время утечка исходных кодов Windows 2000. [Читать дальше →][5]
[1]: https://habrahabr.ru/post/331534/#comment_10280792
[2]: https://habrastorage.org/getpro/habr/post_images/963/920/cd2/963920cd2ebf0dbd6a1ff15d50f80d9e.jpg
[3]: http://www.theregister.co.uk/2017/06/23/windows_10_leak/
[4]: https://www.betaarchive.com/forum/viewtopic.php?f=2&t=6083&start=475
[5]: https://habrahabr.ru/post/331534/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-24 11:30:05
**UPD** Выяснилось, что theregister все [сильно преувеличил][1].
![image][2]
По информации портала [theregister.co.uk][3] недавно произошла массивная утечка приватных билдов ОС Windows 10 и фрагментов ее исходных кодов.
Массив из 32 терабайтов данных (в архивированном виде — 8 терабайт), состоящий из официальных и приватных образов, закрытой технической документации и исходных текстов, [оказался загруженным][4] на ресурс betaarchive.com
Предполагается, что конфиденциальные данные в этом дампе были нелегально скопированы из внутреннего хранилища Microsoft приблизительно в марте 2017 года.
По сообщениям людей, успевших ознакомиться с материалами внушительного архива, утекшие исходные коды в нем относятся к Microsoft's Shared Source Kit. Этот набор включает в себя исходники базовых драйверов Windows 10, стеков Wi-Fi,USB и PnP, драйверов систем хранения и ARM-версии ядра OneCore.
На данный момент имеются все предпосылки того, что инцидент окажется не менее значительным, чем в свое время утечка исходных кодов Windows 2000. [Читать дальше →][5]
[1]: https://habrahabr.ru/post/331534/#comment_10280792
[2]: https://habrastorage.org/getpro/habr/post_images/963/920/cd2/963920cd2ebf0dbd6a1ff15d50f80d9e.jpg
{kind=link}
[3]: http://www.theregister.co.uk/2017/06/23/windows_10_leak/
[4]: https://www.betaarchive.com/forum/viewtopic.php?f=2&t=6083&start=475
[5]: https://habrahabr.ru/post/331534/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Борьба со спамом на хостинге. Настройка EFA Project Free Spam/antivirus filter
habra.16
habrabot(difrex,1) — All
2017-06-24 11:30:05
![image][1]
В этой статье, [как и обещали][2], хотим поделиться нашим опытом борьбы со спамом. Известно, что у любой причины есть следствие. Эта фраза выражает одну из философских форм связи явлений.
Нашей причиной стали многократные жалобы на спам, исходящий от наших клиентов хостинга и VPS. Не всегда можно с уверенностью сказать, были ли это умышленные действия клиентов или они сами не подозревали, что стали жертвой спам-ботов. Что бы там ни было, проблему пришлось решать.
[Читать дальше →][3]
[1]: https://trello-attachments.s3.amazonaws.com/58d3ccb0d0b0255bd1b81750/59147b2e3723806bab861dff/36ad405f3790208d93ef17da94a1ccd1/Hab-2.jpg
[2]: https://habrahabr.ru/post/327588/
[3]: https://habrahabr.ru/post/331498/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-24 11:30:05
![image][1]
В этой статье, [как и обещали][2], хотим поделиться нашим опытом борьбы со спамом. Известно, что у любой причины есть следствие. Эта фраза выражает одну из философских форм связи явлений.
Нашей причиной стали многократные жалобы на спам, исходящий от наших клиентов хостинга и VPS. Не всегда можно с уверенностью сказать, были ли это умышленные действия клиентов или они сами не подозревали, что стали жертвой спам-ботов. Что бы там ни было, проблему пришлось решать.
[Читать дальше →][3]
[1]: https://trello-attachments.s3.amazonaws.com/58d3ccb0d0b0255bd1b81750/59147b2e3723806bab861dff/36ad405f3790208d93ef17da94a1ccd1/Hab-2.jpg
{kind=link}
[2]: https://habrahabr.ru/post/327588/
[3]: https://habrahabr.ru/post/331498/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Security Week 25: В *NIX реанимировали древнюю уязвимость, WannaCry оказался не доделан, ЦРУ прослушивает наши роутеры
habra.16
habrabot(difrex,1) — All
2017-06-24 11:30:05
**Земля, 2005 год**. По всей планете происходят загадочные события: Nokia выводит на рынок [планшет на Linux][1], в глубокой тайне идет разработка [игры][2] с участниками группы Metallica в главных ролях, Джобс [объявил о переходе][3] Маков на платформу Intel.
Тем временем на конференции CancSecWest Гаэль Делалло из Beijaflore представил фундаментальный [доклад][4] об уязвимостях системы управления памятью в разнообразных NIX-ах, и проиллюстрировал свои находки эксплойтами для Apache. Все запатчились. Прошло несколько лет.
**2010 год.** Рафаль Войтчук [продемонстрировал][5] эксплуатацию уязвимости того же класса в сервере Xorg. В том же году Йон Оберайде опубликовал пару [забавных][6] [сообщений][7] о своих невинных играх с никсовым стеком ядра. Все снова запатчились.
**2016 год.** Гуглевский Project Zero разродился [исследованием][8] эксплуатации уязвимостей стека ядра под Ubuntu. Оберайде передает в комментах привет. Убунта запатчилась.
**2017 год.** Никогда такого не было, [и вот опять][9]. Qualys научилась мухлевать со стеком юзермода в любых никсах, согласно идеям Делалло.
[Читать дальше →][10]
[1]: https://www.mobilegazette.com/nokia-770-internet-tablet.htm
[2]: http://uproxx.com/gaming/metallica-videogame-car-shooter/
[3]: https://en.wikipedia.org/wiki/Apple%27s_transition_to_Intel_processors
[4]: http://cansecwest.com/core05/memory_vulns_delalleau.pdf
[5]: http://www.invisiblethingslab.com/resources/misc-2010/xorg-large-memory-attacks.pdf
[6]: https://jon.oberheide.org/blog/2010/11/29/exploiting-stack-overflows-in-the-linux-kernel/
[7]: https://jon.oberheide.org/files/infiltrate12-thestackisback.pdf
[8]: https://googleprojectzero.blogspot.ru/2016/06/exploiting-recursion-in-linux-kernel_20.html
[9]: https://threatpost.com/stack-clash-vulnerability-in-linux-bsd-systems-enables-root-access/126355/
[10]: https://habrahabr.ru/post/331524/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-24 11:30:05
**Земля, 2005 год**. По всей планете происходят загадочные события: Nokia выводит на рынок [планшет на Linux][1], в глубокой тайне идет разработка [игры][2] с участниками группы Metallica в главных ролях, Джобс [объявил о переходе][3] Маков на платформу Intel.
Тем временем на конференции CancSecWest Гаэль Делалло из Beijaflore представил фундаментальный [доклад][4] об уязвимостях системы управления памятью в разнообразных NIX-ах, и проиллюстрировал свои находки эксплойтами для Apache. Все запатчились. Прошло несколько лет.
**2010 год.** Рафаль Войтчук [продемонстрировал][5] эксплуатацию уязвимости того же класса в сервере Xorg. В том же году Йон Оберайде опубликовал пару [забавных][6] [сообщений][7] о своих невинных играх с никсовым стеком ядра. Все снова запатчились.
**2016 год.** Гуглевский Project Zero разродился [исследованием][8] эксплуатации уязвимостей стека ядра под Ubuntu. Оберайде передает в комментах привет. Убунта запатчилась.
**2017 год.** Никогда такого не было, [и вот опять][9]. Qualys научилась мухлевать со стеком юзермода в любых никсах, согласно идеям Делалло.
[Читать дальше →][10]
[1]: https://www.mobilegazette.com/nokia-770-internet-tablet.htm
[2]: http://uproxx.com/gaming/metallica-videogame-car-shooter/
[3]: https://en.wikipedia.org/wiki/Apple%27s_transition_to_Intel_processors
[4]: http://cansecwest.com/core05/memory_vulns_delalleau.pdf
[5]: http://www.invisiblethingslab.com/resources/misc-2010/xorg-large-memory-attacks.pdf
[6]: https://jon.oberheide.org/blog/2010/11/29/exploiting-stack-overflows-in-the-linux-kernel/
[7]: https://jon.oberheide.org/files/infiltrate12-thestackisback.pdf
[8]: https://googleprojectzero.blogspot.ru/2016/06/exploiting-recursion-in-linux-kernel_20.html
[9]: https://threatpost.com/stack-clash-vulnerability-in-linux-bsd-systems-enables-root-access/126355/
[10]: https://habrahabr.ru/post/331524/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Руководство: как использовать Python для алгоритмической торговли на бирже. Часть 1
habra.16
habrabot(difrex,1) — All
2017-06-24 16:00:06
[![][1]][2]
Технологии стали активом — финансовые организации теперь не только занимаются своим основным бизнесом, но уделяют много внимания новым разработкам. Мы уже рассказывали о том, что в мире высокочастотной торговли лучших результатов добиваются обладатели не только самого эффективного, но и быстрого софта и железа.
Среди наиболее популярных в сфере финансов языков программирования можно отметить R и Python, также часто используются C++, C# и Java. В опубликованном на сайте DataCamp [руководстве][3] речь идет о том, как начать использовать Python для создания финансовых приложений — мы представляем вам серию статей-адаптаций глав этого материала. [Читать дальше →][4]
[1]: https://habrastorage.org/web/ae7/bc3/f82/ae7bc3f8279f40dabc93bc979768a45f.png
[2]: https://habrahabr.ru/company/itinvest/blog/331542/
[3]: https://www.datacamp.com/community/tutorials/finance-python-trading#gs.8u7rQvs
[4]: https://habrahabr.ru/post/331542/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-24 16:00:06
[![][1]][2]
Технологии стали активом — финансовые организации теперь не только занимаются своим основным бизнесом, но уделяют много внимания новым разработкам. Мы уже рассказывали о том, что в мире высокочастотной торговли лучших результатов добиваются обладатели не только самого эффективного, но и быстрого софта и железа.
Среди наиболее популярных в сфере финансов языков программирования можно отметить R и Python, также часто используются C++, C# и Java. В опубликованном на сайте DataCamp [руководстве][3] речь идет о том, как начать использовать Python для создания финансовых приложений — мы представляем вам серию статей-адаптаций глав этого материала. [Читать дальше →][4]
[1]: https://habrastorage.org/web/ae7/bc3/f82/ae7bc3f8279f40dabc93bc979768a45f.png
{kind=link}
[2]: https://habrahabr.ru/company/itinvest/blog/331542/
[3]: https://www.datacamp.com/community/tutorials/finance-python-trading#gs.8u7rQvs
[4]: https://habrahabr.ru/post/331542/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Из песочницы] Установка ArchLinux ARM рядом с Android без chroot
habra.16
habrabot(difrex,1) — All
2017-06-24 17:00:04
Я испробовал множество средств для установки Linux на свое Android устройство, но все они или не работали вовсе, или были слишком глючные. К счастью я использую на ПК ArchLinux и узнав о проекте ArchLinux ARM решил попробовать его в деле. И не просто установить в chroot, а заставить его работать и без него.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331546/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-24 17:00:04
Я испробовал множество средств для установки Linux на свое Android устройство, но все они или не работали вовсе, или были слишком глючные. К счастью я использую на ПК ArchLinux и узнав о проекте ArchLinux ARM решил попробовать его в деле. И не просто установить в chroot, а заставить его работать и без него.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331546/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Автоэнкодеры в Keras, Часть 3: Вариационные автоэнкодеры (VAE)
habra.16
habrabot(difrex,1) — All
2017-06-24 20:00:03
### Содержание
* Часть 1: [ Введение ][1]
* Часть 2: [ _Manifold learning_ и скрытые (_latent_) переменные ][2]
* **Часть 3: Вариационные автоэнкодеры (_VAE_)**
* Часть 4: _Conditional VAE_
* Часть 5: _GAN_ (Generative Adversarial Networks) и tensorflow
* Часть 6: _VAE_ + _GAN_
В [ прошлой части ][3] мы уже обсуждали, что такое скрытые переменные, взглянули на их распределение, а также поняли, что из распределения скрытых переменных в обычных автоэнкодерах сложно генерировать новые объекты. Для того чтобы можно было генерировать новые объекты, пространство _скрытых переменных_ (_latent variables_) должно быть предсказуемым.
**_Вариационные автоэнкодеры_** (_Variational Autoencoders_) — это автоэнкодеры, которые учатся отображать объекты в заданное скрытое пространство и, соответственно, сэмплить из него. Поэтому _вариационные автоэнкодеры_ относят также к семейству генеративных моделей.
![][4]
[Читать дальше →][5]
[1]: https://habrahabr.ru/post/331382/
[2]: https://habrahabr.ru/post/331500/
[3]: https://habrahabr.ru/post/331500/
[4]: https://habrastorage.org/web/725/94b/5de/72594b5de85e4e58a0ae071bf2ab2ca7.png
[5]: https://habrahabr.ru/post/331552/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-24 20:00:03
### Содержание
* Часть 1: [ Введение ][1]
* Часть 2: [ _Manifold learning_ и скрытые (_latent_) переменные ][2]
* **Часть 3: Вариационные автоэнкодеры (_VAE_)**
* Часть 4: _Conditional VAE_
* Часть 5: _GAN_ (Generative Adversarial Networks) и tensorflow
* Часть 6: _VAE_ + _GAN_
В [ прошлой части ][3] мы уже обсуждали, что такое скрытые переменные, взглянули на их распределение, а также поняли, что из распределения скрытых переменных в обычных автоэнкодерах сложно генерировать новые объекты. Для того чтобы можно было генерировать новые объекты, пространство _скрытых переменных_ (_latent variables_) должно быть предсказуемым.
**_Вариационные автоэнкодеры_** (_Variational Autoencoders_) — это автоэнкодеры, которые учатся отображать объекты в заданное скрытое пространство и, соответственно, сэмплить из него. Поэтому _вариационные автоэнкодеры_ относят также к семейству генеративных моделей.
![][4]
[Читать дальше →][5]
[1]: https://habrahabr.ru/post/331382/
[2]: https://habrahabr.ru/post/331500/
[3]: https://habrahabr.ru/post/331500/
[4]: https://habrastorage.org/web/725/94b/5de/72594b5de85e4e58a0ae071bf2ab2ca7.png
{kind=link}
[5]: https://habrahabr.ru/post/331552/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Подбор закона распределения случайной величины по данным статистической выборки средствами Python
habra.16
habrabot(difrex,1) — All
2017-06-25 02:00:05
### О чём могут «рассказать» законы распределения случайных величин, если научиться их «слушать»
Законы распределения случайных величин наиболее «красноречивы» при статистической обработке результатов измерений. Адекватная оценка результатов измерений возможна лишь в том случае, когда известны правила, определяющие поведение погрешностей измерения. Основу этих правил и составляют законы распределения погрешностей, которые могут быть представлены представлены в дифференциальной **(pdf)** или интегральной **(cdf)** формах.
К основным характеристикам законов распределения относятся: наиболее вероятное значение измеряемой величины под названием математическое ожидание **(mean)**; мера рассеивания случайной величины вокруг математического ожидания под названием среднеквадратическое отклонение **(std)**.
Дополнительными характеристиками являются – мера скученности дифференциальной формы закона распределения относительно оси симметрии под названием асимметрия **(skew) **и мера крутости, огибающей дифференциальной формы под названием эксцесс **(kurt)**. Читатель уже догадался, что приведенные сокращения взяты из библиотек scipy. stats, numpy, которые мы и будем использовать.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331560/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-25 02:00:05
### О чём могут «рассказать» законы распределения случайных величин, если научиться их «слушать»
Законы распределения случайных величин наиболее «красноречивы» при статистической обработке результатов измерений. Адекватная оценка результатов измерений возможна лишь в том случае, когда известны правила, определяющие поведение погрешностей измерения. Основу этих правил и составляют законы распределения погрешностей, которые могут быть представлены представлены в дифференциальной **(pdf)** или интегральной **(cdf)** формах.
К основным характеристикам законов распределения относятся: наиболее вероятное значение измеряемой величины под названием математическое ожидание **(mean)**; мера рассеивания случайной величины вокруг математического ожидания под названием среднеквадратическое отклонение **(std)**.
Дополнительными характеристиками являются – мера скученности дифференциальной формы закона распределения относительно оси симметрии под названием асимметрия **(skew) **и мера крутости, огибающей дифференциальной формы под названием эксцесс **(kurt)**. Читатель уже догадался, что приведенные сокращения взяты из библиотек scipy. stats, numpy, которые мы и будем использовать.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331560/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
История оптимизации одного IoC контейнера
habra.16
habrabot(difrex,1) — All
2017-06-25 16:00:10
В этой заметке мне хотелось бы поделиться информацией о небольшом, но, на мой взгляд, весьма и весьма полезном [проекте][1], в котором [Stefán Jökull Sigurðarson][2] добавляет все известные ему IoC контейнеры, которые мигрировали на .NET Core, и с использованием [BenchmarkDotNet][3] проводит замеры instance resolving performance. Не упустил возможности поучавствовать в этом соревновании и я со своим маленьким проектом [FsContainer][4].
![image][5]
[Читать дальше →][6]
[1]: https://github.com/stebet/DependencyInjectorBenchmarks
[2]: https://github.com/stebet
[3]: https://github.com/dotnet/BenchmarkDotNet
[4]: https://github.com/FSou1/FsContainer
[5]: https://habrastorage.org/web/789/422/6db/7894226db2db4dce8cec9a5cfe678254.jpeg
[6]: https://habrahabr.ru/post/331584/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-25 16:00:10
В этой заметке мне хотелось бы поделиться информацией о небольшом, но, на мой взгляд, весьма и весьма полезном [проекте][1], в котором [Stefán Jökull Sigurðarson][2] добавляет все известные ему IoC контейнеры, которые мигрировали на .NET Core, и с использованием [BenchmarkDotNet][3] проводит замеры instance resolving performance. Не упустил возможности поучавствовать в этом соревновании и я со своим маленьким проектом [FsContainer][4].
![image][5]
[Читать дальше →][6]
[1]: https://github.com/stebet/DependencyInjectorBenchmarks
[2]: https://github.com/stebet
[3]: https://github.com/dotnet/BenchmarkDotNet
[4]: https://github.com/FSou1/FsContainer
[5]: https://habrastorage.org/web/789/422/6db/7894226db2db4dce8cec9a5cfe678254.jpeg
{kind=link}
[6]: https://habrahabr.ru/post/331584/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Из песочницы] Два в одном: как пользоваться Vim и Nano?
habra.16
habrabot(difrex,1) — All
2017-06-25 17:30:04
## Вступительное слово
Зачем нужна ещё одна, 1001я публикация на эту тему? Статей про vim и nano написано огромное количество, но как правило они касаются только одного из редакторов, либо представляют из себя общий обзор. Чтобы в одной были сжато описаны оба редактора, но при этом без углубления в дебри приведены все основные клавиши управления для полноценной работы, я не не нашёл. Поэтому, почитав найденные материалы, я начал их конспектировать, так и родилась эта статья.
![][1]![][2]
_Любой текстовый редактор можно освоить «методом тыка». Но только не vim._
_Чем nano лучше vim?
Из nano можно выйти без reset'а! (с) Интернет
_
Изначально я не планировал писать об обоих редакторах, а хотел сделать краткую справку только по nano, но в процессе сбора информации накопились данные и по vim тоже. Тут я обнаружил, что Vim не так уж и страшен, если знать команды и концепцию его использования.
[Читать дальше →][3]
[1]: https://pp.userapi.com/c637517/v637517413/5de3c/rdWHkazVRg8.jpg
[2]: https://pp.userapi.com/c637517/v637517413/5de43/MbLYzCv10Ko.jpg
[3]: https://habrahabr.ru/post/331600/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-25 17:30:04
## Вступительное слово
Зачем нужна ещё одна, 1001я публикация на эту тему? Статей про vim и nano написано огромное количество, но как правило они касаются только одного из редакторов, либо представляют из себя общий обзор. Чтобы в одной были сжато описаны оба редактора, но при этом без углубления в дебри приведены все основные клавиши управления для полноценной работы, я не не нашёл. Поэтому, почитав найденные материалы, я начал их конспектировать, так и родилась эта статья.
![][1]![][2]
_Любой текстовый редактор можно освоить «методом тыка». Но только не vim._
_Чем nano лучше vim?
Из nano можно выйти без reset'а! (с) Интернет
_
Изначально я не планировал писать об обоих редакторах, а хотел сделать краткую справку только по nano, но в процессе сбора информации накопились данные и по vim тоже. Тут я обнаружил, что Vim не так уж и страшен, если знать команды и концепцию его использования.
[Читать дальше →][3]
[1]: https://pp.userapi.com/c637517/v637517413/5de3c/rdWHkazVRg8.jpg
{kind=link}
[2]: https://pp.userapi.com/c637517/v637517413/5de43/MbLYzCv10Ko.jpg
{kind=link}
[3]: https://habrahabr.ru/post/331600/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Скрипт статического коллтрекинга
habra.16
habrabot(difrex,1) — All
2017-06-26 07:30:06
![][1]
Описание работы скрипта для подмены на сайте номеров любых операторов. Конструктор для визуальной настройки скрипта. Подмена заголовков, для разных источников трафика.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/e63/103/3a4/e631033a41f344adbd5e16d05e2294f9.jpg
[2]: https://habrahabr.ru/post/331540/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 07:30:06
![][1]
Описание работы скрипта для подмены на сайте номеров любых операторов. Конструктор для визуальной настройки скрипта. Подмена заголовков, для разных источников трафика.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/e63/103/3a4/e631033a41f344adbd5e16d05e2294f9.jpg
{kind=link}
[2]: https://habrahabr.ru/post/331540/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
«База знаний»: 100 практических материалов по безопасности, экономике и инструментарию IaaS
habra.16
habrabot(difrex,1) — All
2017-06-26 10:30:04
Сегодня мы подготовили мегаподборку из материалов «[Первого блога о корпоративном IaaS][1]». Здесь собраны руководства, практические советы по ИБ, сетям и железу. Плюс мы привели наиболее интересные кейсы в сфере взаимодействия бизнеса и IaaS-провайдера.
[ ![][2]][3] [Читать дальше →][4]
[1]: http://iaas-blog.it-grad.ru
[2]: https://habrastorage.org/web/e82/aee/1d3/e82aee1d3cde4ccd8fdb36ad1914f19b.jpg
[3]: https://habrahabr.ru/company/it-grad/blog/331620/
[4]: https://habrahabr.ru/post/331620/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 10:30:04
Сегодня мы подготовили мегаподборку из материалов «[Первого блога о корпоративном IaaS][1]». Здесь собраны руководства, практические советы по ИБ, сетям и железу. Плюс мы привели наиболее интересные кейсы в сфере взаимодействия бизнеса и IaaS-провайдера.
[ ![][2]][3] [Читать дальше →][4]
[1]: http://iaas-blog.it-grad.ru
[2]: https://habrastorage.org/web/e82/aee/1d3/e82aee1d3cde4ccd8fdb36ad1914f19b.jpg
{kind=link}
[3]: https://habrahabr.ru/company/it-grad/blog/331620/
[4]: https://habrahabr.ru/post/331620/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Зачем нужен Kubernetes и почему он больше, чем PaaS?
habra.16
habrabot(difrex,1) — All
2017-06-26 11:00:05
![][1]
В большой production пришёл не только [Docker][2], но и Kubernetes. И если даже с контейнерами далеко не всегда всё достаточно просто, то уж «кормчий» и подавно остаётся за гранью правильного понимания среди многих системных администраторов, DevOps-инженеров, разработчиков. В этой небольшой статье предпринята попытка ответить на один из вечных вопросов (в контексте Kubernetes) с помощью наглядного объяснения идеи и особенностей данного проекта. Возможно, именно этого вам не хватало для того, чтобы начать плотное знакомство с Kubernetes или даже его эксплуатацию?
Соучредитель и архитектор крупного онлайн-сервиса Box _(около 1400 сотрудников)_ Sam Ghods в своём прошлогоднем [выступлении][3] на KubeCon указал на типовую ошибку восприятия Kubernetes. Многие рассматривают этот продукт как очередной фреймворк для оркестровки контейнеров. Но если бы всё действительно было так, то зачем его разработчики неустанно напоминают про «корни Kubernetes API, уходящие в архитектуру\*, создаваемую более 10 лет в рамках проекта Google Borg»?..
[Читать дальше →][4]
[1]: https://habrastorage.org/web/51e/487/9f5/51e4879f51914bdbba7744c38741c3d9.jpg
[2]: https://habrahabr.ru/company/flant/blog/326784/
[3]: https://www.youtube.com/watch?v=of45hYbkIZs
[4]: https://habrahabr.ru/post/327338/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 11:00:05
![][1]
В большой production пришёл не только [Docker][2], но и Kubernetes. И если даже с контейнерами далеко не всегда всё достаточно просто, то уж «кормчий» и подавно остаётся за гранью правильного понимания среди многих системных администраторов, DevOps-инженеров, разработчиков. В этой небольшой статье предпринята попытка ответить на один из вечных вопросов (в контексте Kubernetes) с помощью наглядного объяснения идеи и особенностей данного проекта. Возможно, именно этого вам не хватало для того, чтобы начать плотное знакомство с Kubernetes или даже его эксплуатацию?
Соучредитель и архитектор крупного онлайн-сервиса Box _(около 1400 сотрудников)_ Sam Ghods в своём прошлогоднем [выступлении][3] на KubeCon указал на типовую ошибку восприятия Kubernetes. Многие рассматривают этот продукт как очередной фреймворк для оркестровки контейнеров. Но если бы всё действительно было так, то зачем его разработчики неустанно напоминают про «корни Kubernetes API, уходящие в архитектуру\*, создаваемую более 10 лет в рамках проекта Google Borg»?..
[Читать дальше →][4]
[1]: https://habrastorage.org/web/51e/487/9f5/51e4879f51914bdbba7744c38741c3d9.jpg
{kind=link}
[2]: https://habrahabr.ru/company/flant/blog/326784/
[3]: https://www.youtube.com/watch?v=of45hYbkIZs
[4]: https://habrahabr.ru/post/327338/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Головная боль от использования математического софта
habra.16
habrabot(difrex,1) — All
2017-06-26 11:00:05
![Picture 2][1]
Так получилось, что в один период времени я обсуждал в интернете, казалось бы, разные темы: бесплатные альтернативы Matlab для университетов и студентов, и поиск ошибок в алгоритмах с помощью статического анализа кода. Все эти обсуждения объединило ужасное качество кода современных программ. В частности, качество софта для математиков и учёных. Тут же возникает вопрос о доверии к расчётам и исследованиям, проведённым с помощью таких программ. Попробуем поразмыслить на эту тему и поискать ошибки.
[Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/ac3/68a/cf4/ac368acf43861c19d5d104659cf61044.png
[2]: https://habrahabr.ru/post/331638/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 11:00:05
![Picture 2][1]
Так получилось, что в один период времени я обсуждал в интернете, казалось бы, разные темы: бесплатные альтернативы Matlab для университетов и студентов, и поиск ошибок в алгоритмах с помощью статического анализа кода. Все эти обсуждения объединило ужасное качество кода современных программ. В частности, качество софта для математиков и учёных. Тут же возникает вопрос о доверии к расчётам и исследованиям, проведённым с помощью таких программ. Попробуем поразмыслить на эту тему и поискать ошибки.
[Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/ac3/68a/cf4/ac368acf43861c19d5d104659cf61044.png
{kind=link}
[2]: https://habrahabr.ru/post/331638/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Как Pony Express удается вам доставлять
habra.16
habrabot(difrex,1) — All
2017-06-26 14:00:05
Чего хочет любой клиент от логистического оператора? Конечно, чтобы всё происходило быстро, качественно и желательно, по максимуму, без его — клиента — непосредственного участия. Чтобы можно было заплатить свои кровные, а дальше оно уж как-нибудь само. Но в некоторых случаях, чтобы «оно само», клиенту тоже нужно немного пошевелиться. Как быть компании, если он не торопится? Под катом — опыт Pony Express.
![][1]
[Читать дальше →][2]
[1]: https://habrastorage.org/web/625/90a/c2b/62590ac2b7694d48b798415a20dc40aa.jpg
[2]: https://habrahabr.ru/post/331650/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 14:00:05
Чего хочет любой клиент от логистического оператора? Конечно, чтобы всё происходило быстро, качественно и желательно, по максимуму, без его — клиента — непосредственного участия. Чтобы можно было заплатить свои кровные, а дальше оно уж как-нибудь само. Но в некоторых случаях, чтобы «оно само», клиенту тоже нужно немного пошевелиться. Как быть компании, если он не торопится? Под катом — опыт Pony Express.
![][1]
[Читать дальше →][2]
[1]: https://habrastorage.org/web/625/90a/c2b/62590ac2b7694d48b798415a20dc40aa.jpg
{kind=link}
[2]: https://habrahabr.ru/post/331650/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Z-order в 8D
habra.16
habrabot(difrex,1) — All
2017-06-26 15:00:03
![][1]
Индексы на основе самоподобных заметающих кривых пригодны не только для организации поиска пространственных данных. Они работоспособны и на разнородных данных, положенных на целочисленную решетку.
Под катом мы займёмся проверкой возможности применения [Z-кривой][2] для реализации 8-мерного индекса с прицелом на [куб OLAP][3].
[Читать дальше →][4]
[1]: https://habrastorage.org/web/823/1d6/d77/8231d6d774204a5289c8a1417d5cfd68.png
[2]: https://en.wikipedia.org/wiki/Z-order_curve
[3]: https://ru.wikipedia.org/wiki/OLAP-%D0%BA%D1%83%D0%B1
[4]: https://habrahabr.ru/post/331420/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 15:00:03
![][1]
Индексы на основе самоподобных заметающих кривых пригодны не только для организации поиска пространственных данных. Они работоспособны и на разнородных данных, положенных на целочисленную решетку.
Под катом мы займёмся проверкой возможности применения [Z-кривой][2] для реализации 8-мерного индекса с прицелом на [куб OLAP][3].
[Читать дальше →][4]
[1]: https://habrastorage.org/web/823/1d6/d77/8231d6d774204a5289c8a1417d5cfd68.png
{kind=link}
[2]: https://en.wikipedia.org/wiki/Z-order_curve
[3]: https://ru.wikipedia.org/wiki/OLAP-%D0%BA%D1%83%D0%B1
[4]: https://habrahabr.ru/post/331420/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Автоэнкодеры в Keras, Часть 4: Conditional VAE
habra.16
habrabot(difrex,1) — All
2017-06-26 15:00:03
### Содержание
* Часть 1: [ Введение ][1]
* Часть 2: [ _Manifold learning_ и скрытые (_latent_) переменные ][2]
* Часть 3: [Вариационные автоэнкодеры (_VAE_) ][3]
* **Часть 4: Conditional VAE**
* Часть 5: _GAN_ (Generative Adversarial Networks) и tensorflow
* Часть 6: _VAE_ + _GAN_
В [ прошлой части ][4] мы познакомились с **вариационными автоэнкодерами (VAE)**, реализовали такой на _keras_, а также поняли, как с его помощью генерировать изображения. Получившаяся модель, однако, обладала некоторыми недостатками:
1. Не все цифры получилось хорошо закодировать в скрытом пространстве: некоторые цифры либо вообще отсутствовали, либо были очень смазанными. В промежутках между областями, в которых были сконцентрированы варианты одной и той же цифры, находились вообще какие-то бессмысленные иероглифы.
Что тут писать, вот так выглядели сгенерированные цифры:
**Картинка**
2. Сложно было генерировать картинку какой-то заданной цифры. Для этого надо было смотреть, в какую область латентного пространства попадали изображения конкретной цифры, и сэмплить уже откуда-то оттуда, а тем более было сложно генерировать цифру в каком-то заданном стиле.
В этой части мы посмотрим, как можно лишь совсем немного усложнив модель преодолеть обе эти проблемы, и заодно получим возможность генерировать картинки новых цифр в стиле другой цифры – это, наверное, самая интересная фича будущей модели.
[Читать дальше →][5]
[1]: https://habrahabr.ru/post/331382/
[2]: https://habrahabr.ru/post/331500/
[3]: https://habrahabr.ru/post/331552/
[4]: https://habrahabr.ru/post/331552/
[5]: https://habrahabr.ru/post/331664/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 15:00:03
### Содержание
* Часть 1: [ Введение ][1]
* Часть 2: [ _Manifold learning_ и скрытые (_latent_) переменные ][2]
* Часть 3: [Вариационные автоэнкодеры (_VAE_) ][3]
* **Часть 4: Conditional VAE**
* Часть 5: _GAN_ (Generative Adversarial Networks) и tensorflow
* Часть 6: _VAE_ + _GAN_
В [ прошлой части ][4] мы познакомились с **вариационными автоэнкодерами (VAE)**, реализовали такой на _keras_, а также поняли, как с его помощью генерировать изображения. Получившаяся модель, однако, обладала некоторыми недостатками:
1. Не все цифры получилось хорошо закодировать в скрытом пространстве: некоторые цифры либо вообще отсутствовали, либо были очень смазанными. В промежутках между областями, в которых были сконцентрированы варианты одной и той же цифры, находились вообще какие-то бессмысленные иероглифы.
Что тут писать, вот так выглядели сгенерированные цифры:
**Картинка**
2. Сложно было генерировать картинку какой-то заданной цифры. Для этого надо было смотреть, в какую область латентного пространства попадали изображения конкретной цифры, и сэмплить уже откуда-то оттуда, а тем более было сложно генерировать цифру в каком-то заданном стиле.
В этой части мы посмотрим, как можно лишь совсем немного усложнив модель преодолеть обе эти проблемы, и заодно получим возможность генерировать картинки новых цифр в стиле другой цифры – это, наверное, самая интересная фича будущей модели.
[Читать дальше →][5]
[1]: https://habrahabr.ru/post/331382/
[2]: https://habrahabr.ru/post/331500/
[3]: https://habrahabr.ru/post/331552/
[4]: https://habrahabr.ru/post/331552/
[5]: https://habrahabr.ru/post/331664/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Ubuntu для мобильных устройств: посмертный анализ
habra.16
habrabot(difrex,1) — All
2017-06-26 15:00:03
![][1]
Так выглядела Ubuntu Touch, когда проект анонсировали 2 января 2013 года. Изображение: Canonical
Теперь, когда телефонов и планшетов Ubuntu больше нет, я бы хотел поделиться мыслями, почему проект провалился и какие уроки из этого можно извлечь.
Чтобы резюмировать моё участие в проекте: я использовал Ubuntu Touch на Nexus 7 постоянно и периодически с момента его анонса в 2013 году и до декабря 2014 года, начал работать над приложениями Click в декабре 2014-го, начал писать [статью][2] из 15-ти частей “Hacking Ubuntu Touch” об устройстве системы в январе 2015-го, был инсайдером по программе Ubuntu Phone Insider, получил Meizu MX4 от Canonical, организовал конкурс для разработчиков приложений [UbuContest][3] и был его спонсором, работал над баг-репортами и приложениями примерно до апреля 2016 года, а затем продал или переделал все мои оставшиеся устройства в середине 2016-го. Так что думаю, что могу поделиться какими-то мыслями о проекте, его проблемах и о том, где мы могли сработать лучше.
Пожалуйста, обратите внимание, что эта статья не затрагивает проект [UBPorts][4], который продолжает работать на операционной системе телефонов, Unity 8 и другие компоненты.
[Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/1d3/fb5/bac/1d3fb5bacfdae7285086227f19325b11.jpg
[2]: http://www.lieberbiber.de/2015/05/07/hacking-ubuntu-touch-index/
[3]: https://ubucon.de/2015/contest
[4]: https://ubports.com/
[5]: https://habrahabr.ru/post/331658/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 15:00:03
![][1]
Так выглядела Ubuntu Touch, когда проект анонсировали 2 января 2013 года. Изображение: Canonical
Теперь, когда телефонов и планшетов Ubuntu больше нет, я бы хотел поделиться мыслями, почему проект провалился и какие уроки из этого можно извлечь.
Чтобы резюмировать моё участие в проекте: я использовал Ubuntu Touch на Nexus 7 постоянно и периодически с момента его анонса в 2013 году и до декабря 2014 года, начал работать над приложениями Click в декабре 2014-го, начал писать [статью][2] из 15-ти частей “Hacking Ubuntu Touch” об устройстве системы в январе 2015-го, был инсайдером по программе Ubuntu Phone Insider, получил Meizu MX4 от Canonical, организовал конкурс для разработчиков приложений [UbuContest][3] и был его спонсором, работал над баг-репортами и приложениями примерно до апреля 2016 года, а затем продал или переделал все мои оставшиеся устройства в середине 2016-го. Так что думаю, что могу поделиться какими-то мыслями о проекте, его проблемах и о том, где мы могли сработать лучше.
Пожалуйста, обратите внимание, что эта статья не затрагивает проект [UBPorts][4], который продолжает работать на операционной системе телефонов, Unity 8 и другие компоненты.
[Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/1d3/fb5/bac/1d3fb5bacfdae7285086227f19325b11.jpg
{kind=link}
[2]: http://www.lieberbiber.de/2015/05/07/hacking-ubuntu-touch-index/
[3]: https://ubucon.de/2015/contest
[4]: https://ubports.com/
[5]: https://habrahabr.ru/post/331658/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Dlang Tour переведен на русский язык
habra.16
habrabot(difrex,1) — All
2017-06-26 18:00:04
[Dlang Tour][1] — это интерактивное введение в язык [D][2]. Сделан по образцу [Golang Tour][3].
![][4]
В большинстве статей есть примеры кода, которые можно запустить из браузера.
[Читать дальше →][5]
[1]: https://tour.dlang.org/tour/ru/welcome/welcome-to-d
[2]: http://dlang.org/
[3]: https://tour.golang.org/welcome/1
[4]: https://habrastorage.org/web/288/f04/be5/288f04be5b7d4da995f1f00fd059f2f1.png
[5]: https://habrahabr.ru/post/331670/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 18:00:04
[Dlang Tour][1] — это интерактивное введение в язык [D][2]. Сделан по образцу [Golang Tour][3].
![][4]
В большинстве статей есть примеры кода, которые можно запустить из браузера.
[Читать дальше →][5]
[1]: https://tour.dlang.org/tour/ru/welcome/welcome-to-d
[2]: http://dlang.org/
[3]: https://tour.golang.org/welcome/1
[4]: https://habrastorage.org/web/288/f04/be5/288f04be5b7d4da995f1f00fd059f2f1.png
{kind=link}
[5]: https://habrahabr.ru/post/331670/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Взгляд изнутри: «On Rails!» об участии в «Противостоянии»
habra.16
habrabot(difrex,1) — All
2017-06-26 18:30:04
![][1]
Противостояние — ежегодное мероприятие, в котором специалисты по информационной безопасности пробуют свои силы в атаке и защите, используя различные системы и программные платформы. Обычно проводится соревнование в виде реального противостояния двух команд. Первая команда атакует системы безопасности, которые поддерживаются командой защитников и экспертных центров мониторинга. Само мероприятие проводится в рамках Международного форума по практической безопасности Positive Hack Days. «Цель Противостояния — столкнуть две противоборствующие стороны в более или менее контролируемой среде, чтобы посмотреть, что победит — целенаправленные атаки или целенаправленная защита. На роль защитников и SOC пришли эксперты отрасли — интеграторы, вендоры и те, кто выполняет функцию ИБ на стороне заказчиков», — рассказывает о мероприятии член оргкомитета форума Михаил Левин.
Каждый год команды, принимающие участие в «Противостоянии», преследуют свои цели. В этом плане текущий год ничем не отличается от предыдущих. Одна из команд, On Rails!, которая представляет IBM и практикующих экспертов in-house SOC, пробовала свои силы в Противостоянии с решениями из портфеля IBM Security. Само мероприятие уже прошло, и о нем не раз и не два рассказывали в сети. Настало время и нам сделать небольшое review участия команды «On Rails!» в противостоянии «The Standoff». Команда была сформирована в конце апреля из экспертов, с которыми не страшно было пойти в бой против хакеров: Эльман Бейбутов, Роман Андреев, Андрей Курицын, Сергей Кулаков, Сергей Романов, Владимир Камышанов и другие, пожелавшие остаться неизвестными героями. Многие были знакомы между собой и даже работали в прошлом в одних компаниях, поэтому быстро удалось скоординироваться и обсудить тактику защиты.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/8ff/cc8/057/8ffcc8057d3948ce8b86502a9ff1103b.jpg
[2]: https://habrahabr.ru/post/331672/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 18:30:04
![][1]
Противостояние — ежегодное мероприятие, в котором специалисты по информационной безопасности пробуют свои силы в атаке и защите, используя различные системы и программные платформы. Обычно проводится соревнование в виде реального противостояния двух команд. Первая команда атакует системы безопасности, которые поддерживаются командой защитников и экспертных центров мониторинга. Само мероприятие проводится в рамках Международного форума по практической безопасности Positive Hack Days. «Цель Противостояния — столкнуть две противоборствующие стороны в более или менее контролируемой среде, чтобы посмотреть, что победит — целенаправленные атаки или целенаправленная защита. На роль защитников и SOC пришли эксперты отрасли — интеграторы, вендоры и те, кто выполняет функцию ИБ на стороне заказчиков», — рассказывает о мероприятии член оргкомитета форума Михаил Левин.
Каждый год команды, принимающие участие в «Противостоянии», преследуют свои цели. В этом плане текущий год ничем не отличается от предыдущих. Одна из команд, On Rails!, которая представляет IBM и практикующих экспертов in-house SOC, пробовала свои силы в Противостоянии с решениями из портфеля IBM Security. Само мероприятие уже прошло, и о нем не раз и не два рассказывали в сети. Настало время и нам сделать небольшое review участия команды «On Rails!» в противостоянии «The Standoff». Команда была сформирована в конце апреля из экспертов, с которыми не страшно было пойти в бой против хакеров: Эльман Бейбутов, Роман Андреев, Андрей Курицын, Сергей Кулаков, Сергей Романов, Владимир Камышанов и другие, пожелавшие остаться неизвестными героями. Многие были знакомы между собой и даже работали в прошлом в одних компаниях, поэтому быстро удалось скоординироваться и обсудить тактику защиты.
[Читать дальше →][2]
[1]: https://habrastorage.org/web/8ff/cc8/057/8ffcc8057d3948ce8b86502a9ff1103b.jpg
{kind=link}
[2]: https://habrahabr.ru/post/331672/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Чипы Intel Skylake и Kaby Lake — обнаружена проблема при активном Hyper-Threading
habra.16
habrabot(difrex,1) — All
2017-06-26 21:00:04
В мае — апреле этого года Intel [обновляла][1] документацию на свои процессоры. Стало известно почему — появилось описание новой ошибки. Согласно [документу][2], опубликованному Debian, чипы с микроархитектурой Skylake и Kaby Lake, а также серверные процессоры Xeon v5 и v6 и некоторые процессоры Pentium могут вести себя непредсказуемо при активном Hyper-Threading.
[![][3]][4] [Читать дальше →][5]
[1]: https://www.theregister.co.uk/2017/06/25/intel_skylake_kaby_lake_microcode_bug/
[2]: https://lists.debian.org/debian-devel/2017/06/msg00308.html
[3]: https://habrastorage.org/web/445/c12/392/445c123928ce44e1a9ce9ca2e6104e85.jpg
[4]: https://habrahabr.ru/company/it-grad/blog/330580/
[5]: https://habrahabr.ru/post/330580/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 21:00:04
В мае — апреле этого года Intel [обновляла][1] документацию на свои процессоры. Стало известно почему — появилось описание новой ошибки. Согласно [документу][2], опубликованному Debian, чипы с микроархитектурой Skylake и Kaby Lake, а также серверные процессоры Xeon v5 и v6 и некоторые процессоры Pentium могут вести себя непредсказуемо при активном Hyper-Threading.
[![][3]][4] [Читать дальше →][5]
[1]: https://www.theregister.co.uk/2017/06/25/intel_skylake_kaby_lake_microcode_bug/
[2]: https://lists.debian.org/debian-devel/2017/06/msg00308.html
[3]: https://habrastorage.org/web/445/c12/392/445c123928ce44e1a9ce9ca2e6104e85.jpg
{kind=link}
[4]: https://habrahabr.ru/company/it-grad/blog/330580/
[5]: https://habrahabr.ru/post/330580/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Дискриминация котов: веб-трекинг через невидимые картинки
habra.16
habrabot(difrex,1) — All
2017-06-26 22:00:04
![image][1]
Вы когда-нибудь задумывались над тем, по какому принципу вам показывают таргетированную рекламу? Почему, даже не лайкая ничего во время сёрфинга вы, возвращаясь на Facebook, видите рекламу, связанную с посещёнными вами сайтами? И кто заинтересован в том, чтобы отслеживать пользователей? В рамках моего учебного проекта, мне предстояло выяснить, какие компании стоят за трекингом посещений сайтов, и что они используют, чтобы делать это, не привлекая особого внимания.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/b1f/8e4/eb4/b1f8e4eb4d584d0fa147f5721316211d.png
[2]: https://habrahabr.ru/post/326070/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-26 22:00:04
![image][1]
Вы когда-нибудь задумывались над тем, по какому принципу вам показывают таргетированную рекламу? Почему, даже не лайкая ничего во время сёрфинга вы, возвращаясь на Facebook, видите рекламу, связанную с посещёнными вами сайтами? И кто заинтересован в том, чтобы отслеживать пользователей? В рамках моего учебного проекта, мне предстояло выяснить, какие компании стоят за трекингом посещений сайтов, и что они используют, чтобы делать это, не привлекая особого внимания.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/b1f/8e4/eb4/b1f8e4eb4d584d0fa147f5721316211d.png
{kind=link}
[2]: https://habrahabr.ru/post/326070/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Новые возможности C#, которые можно ожидать в ближайшее время
habra.16
habrabot(difrex,1) — All
2017-06-27 09:30:03
[![][1]][2]
В апреле 2003-его года был выпущен C# 1.2 и с тех пор все версии имели только major версию.
И вот сейчас, если верить [официальной страничке roslyn на github][3], в работе версии 7.1 и 7.2.
[Узнать что нового нас ожидает в C#][4]
[1]: https://habrastorage.org/web/9b6/29f/a8e/9b629fa8e5e84ea4be45506281ef46e9.jpg
[2]: http://habrahabr.ru/post/331554/
[3]: https://github.com/dotnet/roslyn/blob/master/docs/Language%20Feature%20Status.md
[4]: https://habrahabr.ru/post/331554/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-27 09:30:03
[![][1]][2]
В апреле 2003-его года был выпущен C# 1.2 и с тех пор все версии имели только major версию.
И вот сейчас, если верить [официальной страничке roslyn на github][3], в работе версии 7.1 и 7.2.
[Узнать что нового нас ожидает в C#][4]
[1]: https://habrastorage.org/web/9b6/29f/a8e/9b629fa8e5e84ea4be45506281ef46e9.jpg
{kind=link}
[2]: http://habrahabr.ru/post/331554/
[3]: https://github.com/dotnet/roslyn/blob/master/docs/Language%20Feature%20Status.md
[4]: https://habrahabr.ru/post/331554/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Как я сдал экзамен на сертификат CISSP
habra.16
habrabot(difrex,1) — All
2017-06-27 09:30:03
Первый источник информации, из которого я многое узнал о CISSP, это [публикация на Хабре][1]. В своем описании постараюсь не дублировать информацию из этого поста.
Я начинал готовиться еще в 2014 году и переход от 10 доменов к 8 еще не состоялся. Мне пришлось готовиться сначала по старым учебникам, а потом переходить на новые. Приведу ниже описание моего собственного опыта, и некоторых выводов, которые могут быть полезны для тех, кто планирует получить сертификат.
Для подготовки я избрал тактику медленного освоения материала — учебник читал по дороге из дома в офис и обратно. Получалось около часа в день. Лучше готовиться по английским учебникам, ибо в переведенных на русский учебниках осталось мало английских терминов, и будет трудно ориентироваться в вопросах на английском. [Читать дальше →][2]
[1]: https://habrahabr.ru/company/it/blog/196638/
[2]: https://habrahabr.ru/post/330984/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-27 09:30:03
Первый источник информации, из которого я многое узнал о CISSP, это [публикация на Хабре][1]. В своем описании постараюсь не дублировать информацию из этого поста.
Я начинал готовиться еще в 2014 году и переход от 10 доменов к 8 еще не состоялся. Мне пришлось готовиться сначала по старым учебникам, а потом переходить на новые. Приведу ниже описание моего собственного опыта, и некоторых выводов, которые могут быть полезны для тех, кто планирует получить сертификат.
Для подготовки я избрал тактику медленного освоения материала — учебник читал по дороге из дома в офис и обратно. Получалось около часа в день. Лучше готовиться по английским учебникам, ибо в переведенных на русский учебниках осталось мало английских терминов, и будет трудно ориентироваться в вопросах на английском. [Читать дальше →][2]
[1]: https://habrahabr.ru/company/it/blog/196638/
[2]: https://habrahabr.ru/post/330984/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Тюнинг сетевого стека Linux для ленивых
habra.16
habrabot(difrex,1) — All
2017-06-27 12:30:05
Сетевой стек Linux по умолчанию замечательно работает на десктопах. На серверах с нагрузкой чуть выше средней уже приходится разбираться как всё нужно правильно настраивать. На моей текущей работе этим приходится заниматься едва ли не в промышленных масштабах, так что без автоматизации никуда – объяснять каждому коллеге что и как устроено долго, а заставлять людей читать ≈300 страниц английского текста, перемешанного с кодом на C… Можно и нужно, но результаты будут не через час и не через день. Поэтому я попробовал накидать набор утилит для тюнинга сетевого стека и руководство по их использованию, не уходящее в специфические детали определённых задач, которое при этом остаётся достаточно компактным для того, чтобы его можно было прочитать меньше чем за час и вынести из него хоть какую-то пользу.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331720/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-27 12:30:05
Сетевой стек Linux по умолчанию замечательно работает на десктопах. На серверах с нагрузкой чуть выше средней уже приходится разбираться как всё нужно правильно настраивать. На моей текущей работе этим приходится заниматься едва ли не в промышленных масштабах, так что без автоматизации никуда – объяснять каждому коллеге что и как устроено долго, а заставлять людей читать ≈300 страниц английского текста, перемешанного с кодом на C… Можно и нужно, но результаты будут не через час и не через день. Поэтому я попробовал накидать набор утилит для тюнинга сетевого стека и руководство по их использованию, не уходящее в специфические детали определённых задач, которое при этом остаётся достаточно компактным для того, чтобы его можно было прочитать меньше чем за час и вынести из него хоть какую-то пользу.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/331720/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Статический анализ как часть процесса разработки Unreal Engine
habra.16
habrabot(difrex,1) — All
2017-06-27 12:30:05
![PVS-Studio & Unreal Engine][1]
Проект Unreal Engine развивается — добавляется новый код и изменятся уже написанный. Неизбежное следствие развития проекта — появление в коде новых ошибок, которые желательно выявлять как можно раньше. Одним из способов сокращения количества ошибок является использование статического анализатора кода PVS-Studio. Причем анализатор также быстро развивается и учится находить новые паттерны ошибок, некоторые из которых будут рассмотрены в этой статье. Если вас заботит качество кода ваших проектов, то эта статья для вас.
[Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/dda/dc7/98b/ddadc798b6b8f4cdd200b7d9360dffd4.png
[2]: https://habrahabr.ru/post/331724/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-06-27 12:30:05
![PVS-Studio & Unreal Engine][1]
Проект Unreal Engine развивается — добавляется новый код и изменятся уже написанный. Неизбежное следствие развития проекта — появление в коде новых ошибок, которые желательно выявлять как можно раньше. Одним из способов сокращения количества ошибок является использование статического анализатора кода PVS-Studio. Причем анализатор также быстро развивается и учится находить новые паттерны ошибок, некоторые из которых будут рассмотрены в этой статье. Если вас заботит качество кода ваших проектов, то эта статья для вас.
[Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/dda/dc7/98b/ddadc798b6b8f4cdd200b7d9360dffd4.png
{kind=link}
[2]: https://habrahabr.ru/post/331724/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut