|
|
Login |
[#]
[Перевод] Поиск с помощью регулярных выражений может быть простым и быстрым
habrabot(difrex,1) — All
2015-11-10 16:30:02
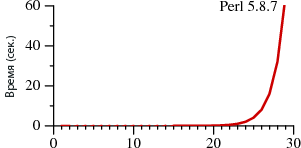
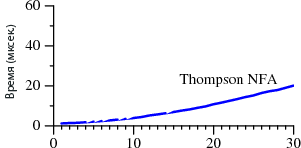
В этой статье мы рассмотрим два способа поиска с помощью регулярных выражений. Один широко распространён и используется в стандартных интерпретаторах многих языков. Второй мало где применяется, в основном в реализациях awk и grep. Оба подхода сильно различаются по своей производительности: ![][1] ![][2] В первом случае поиск занимает A? лет. Причём он взят лишь для примера, во многих других языках наблюдается та же картина — в Python, PHP, Ruby и т. д. Ниже мы рассмотрим этот вопрос более детально. Наверняка вам трудно поверить приведённым данным. Если вы работали с Perl, то вряд ли подмечали за ним низкую производительность при работе с регулярными выражениями. Дело в том, что в большинстве случаев Perl обращается с ними достаточно быстро. Однако, как следует из графика, можно столкнуться с так называемыми патологическими регулярными выражениями, на которых Perl начинает буксовать. В то же время у Thompson NFA такой проблемы нет. Возникает логичный вопрос: а почему бы в Perl не использовать метод Thompson NFA? Это возможно и следует делать, и об этом пойдёт далее речь. [Читать дальше →][3]
[1]: https://habrastorage.org/files/6fe/449/288/6fe44928826a4306a4c11b441da9ac94.png
[2]: https://habrastorage.org/files/0f7/f0d/5d6/0f7f0d5d608e4dbbb602934d3b5c3b7e.png
[3]: http://habrahabr.ru/post/270507/#habracut
habrabot(difrex,1) — All
2015-11-10 16:30:02
В этой статье мы рассмотрим два способа поиска с помощью регулярных выражений. Один широко распространён и используется в стандартных интерпретаторах многих языков. Второй мало где применяется, в основном в реализациях awk и grep. Оба подхода сильно различаются по своей производительности: ![][1] ![][2] В первом случае поиск занимает A? лет. Причём он взят лишь для примера, во многих других языках наблюдается та же картина — в Python, PHP, Ruby и т. д. Ниже мы рассмотрим этот вопрос более детально. Наверняка вам трудно поверить приведённым данным. Если вы работали с Perl, то вряд ли подмечали за ним низкую производительность при работе с регулярными выражениями. Дело в том, что в большинстве случаев Perl обращается с ними достаточно быстро. Однако, как следует из графика, можно столкнуться с так называемыми патологическими регулярными выражениями, на которых Perl начинает буксовать. В то же время у Thompson NFA такой проблемы нет. Возникает логичный вопрос: а почему бы в Perl не использовать метод Thompson NFA? Это возможно и следует делать, и об этом пойдёт далее речь. [Читать дальше →][3]
[1]: https://habrastorage.org/files/6fe/449/288/6fe44928826a4306a4c11b441da9ac94.png
{kind=link}
[2]: https://habrastorage.org/files/0f7/f0d/5d6/0f7f0d5d608e4dbbb602934d3b5c3b7e.png
{kind=link}
[3]: http://habrahabr.ru/post/270507/#habracut