|
|
Login |
[>]
Первый опыт разработки игры для Apple Watch
habra.16
habrabot(difrex,1) — All
2017-03-24 08:30:06
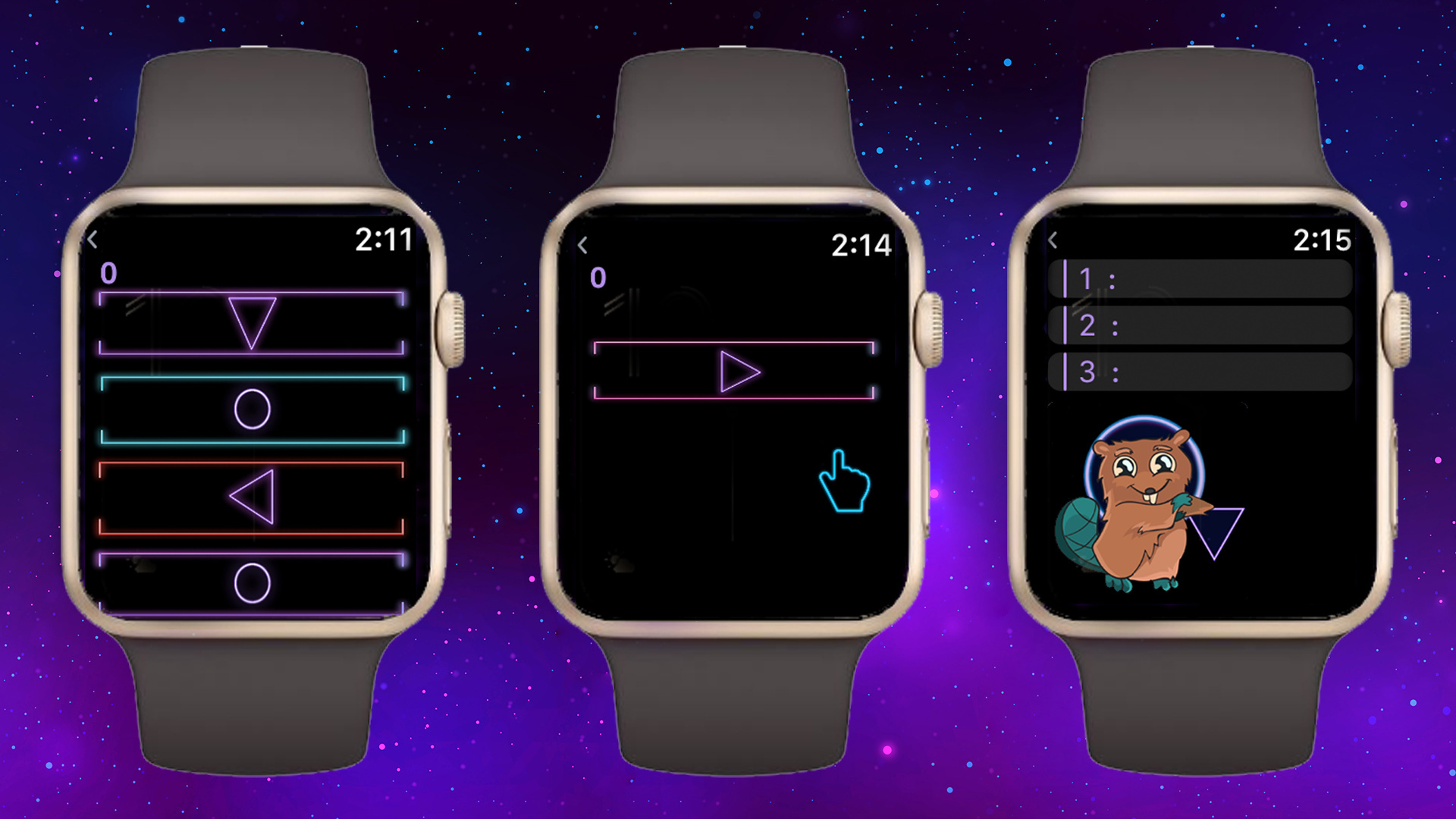
Всем привет! В своей статье я хочу рассказать о опыте разработки игры для Apple Watch. Игра называется Space Beaver(Бобер и Космос). Она также доступна и на iphone. Но в этой статье будет рассказ именно о версии для часов. Исходный код [здесь][1].
![][2]
[Читать дальше →][3]
[1]: https://github.com/darkwind666/SpaceBeaverAppleWatch
[2]: https://habrastorage.org/files/2fb/8eb/887/2fb8eb8877e943a3807a546c24b9fb8b.jpg
[3]: https://habrahabr.ru/post/322540/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 08:30:06
Всем привет! В своей статье я хочу рассказать о опыте разработки игры для Apple Watch. Игра называется Space Beaver(Бобер и Космос). Она также доступна и на iphone. Но в этой статье будет рассказ именно о версии для часов. Исходный код [здесь][1].
![][2]
[Читать дальше →][3]
[1]: https://github.com/darkwind666/SpaceBeaverAppleWatch
[2]: https://habrastorage.org/files/2fb/8eb/887/2fb8eb8877e943a3807a546c24b9fb8b.jpg
{kind=link}
[3]: https://habrahabr.ru/post/322540/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Java-конференция JBreak 2017, или зачем Charles Nutter едет в Новосибирск из Миннеаполиса, США
habra.16
habrabot(difrex,1) — All
2017-03-24 10:00:03
[Charles Nutter][1] — JVM-разработчик из Red Hat, работающий на OpenJDK, мейнтейнер проекта JRuby, Java Champion и Ruby Hero, первоклассный специалист и спикер многих Java-конференций. Впервые в Россию он приехал в прошлом году на Joker 2016, где выступил с двумя [хардкорными докладами][2], после чего признался в том, что не ожидал такого теплого приема и решил во что бы то ни стало вернуться в Россию:
> The Russian people are warm, friendly, and intelligent. They welcomed me to their country to teach and learn. We must strive to be friends.
>
> — Charles Nutter (@headius) [October 17, 2016][3]
Все сложилось удачно, и Charles запланировал визиты в Новосибирск (JBreak, 4 апреля) и в Москву (JPoint, 7-8 апреля). [Обзор программы JPoint 2017][4] мы уже делали, вот руки дошли и до JBreak 2017. Под катом – длиннопост про всех, кто будет выступать в Новосибе, и про все, что они будут рассказывать.
[Читать дальше →][5]
[1]: https://twitter.com/headius
[2]: http://2016.jokerconf.com/speakers/charles-nutter/
[3]: https://twitter.com/headius/status/788079926159216640
[4]: https://habrahabr.ru/company/jugru/blog/323040/
[5]: https://habrahabr.ru/post/324668/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 10:00:03
[Charles Nutter][1] — JVM-разработчик из Red Hat, работающий на OpenJDK, мейнтейнер проекта JRuby, Java Champion и Ruby Hero, первоклассный специалист и спикер многих Java-конференций. Впервые в Россию он приехал в прошлом году на Joker 2016, где выступил с двумя [хардкорными докладами][2], после чего признался в том, что не ожидал такого теплого приема и решил во что бы то ни стало вернуться в Россию:
> The Russian people are warm, friendly, and intelligent. They welcomed me to their country to teach and learn. We must strive to be friends.
>
> — Charles Nutter (@headius) [October 17, 2016][3]
Все сложилось удачно, и Charles запланировал визиты в Новосибирск (JBreak, 4 апреля) и в Москву (JPoint, 7-8 апреля). [Обзор программы JPoint 2017][4] мы уже делали, вот руки дошли и до JBreak 2017. Под катом – длиннопост про всех, кто будет выступать в Новосибе, и про все, что они будут рассказывать.
[Читать дальше →][5]
[1]: https://twitter.com/headius
[2]: http://2016.jokerconf.com/speakers/charles-nutter/
[3]: https://twitter.com/headius/status/788079926159216640
[4]: https://habrahabr.ru/company/jugru/blog/323040/
[5]: https://habrahabr.ru/post/324668/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Визуализация атак на базе ELK (elasticsearch, kibana, logstash)
habra.16
habrabot(difrex,1) — All
2017-03-24 12:30:04
Доброго времени суток. В процессе обслуживания большого количества серверов возникает необходимость централизации управления всем зоопарком машин, а так же централизованный сбор логов и аналитика логов на предмет выявления аномалий, ошибок и общей статистики.
В качестве централизованного сбора логов используется rsyslog, а для структурирования и визуализации elasticsearch + kibana. Все бы ничего, но когда количество подключенных машин разрастается, то данных настолько много, что уходит (уходило) большое количество времени на их обработку и анализ. Наряду с другими интересными штуками всегда хотелось организовать свой центр безопасности. Этакая мультимониторная статистика с картами, графиками и прочим.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324760/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 12:30:04
Доброго времени суток. В процессе обслуживания большого количества серверов возникает необходимость централизации управления всем зоопарком машин, а так же централизованный сбор логов и аналитика логов на предмет выявления аномалий, ошибок и общей статистики.
В качестве централизованного сбора логов используется rsyslog, а для структурирования и визуализации elasticsearch + kibana. Все бы ничего, но когда количество подключенных машин разрастается, то данных настолько много, что уходит (уходило) большое количество времени на их обработку и анализ. Наряду с другими интересными штуками всегда хотелось организовать свой центр безопасности. Этакая мультимониторная статистика с картами, графиками и прочим.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324760/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Больше, чем React: Почему не следует использовать ReactJS для сложных интерактивных фронтенд-проектов
habra.16
habrabot(difrex,1) — All
2017-03-24 15:00:04
_Перевод [статьи][1], посвящённой использованию ReactJS для создания фронтенда._
React — отличный инструмент для реализации простых интерактивных веб-сайтов. Но насколько он применим в сложных фронтенд-проектах? Работает ли он там столь же хорошо?
В этой статье мы рассмотрим некоторые проблемы, с которыми можно столкнуться при использовании React во время веб-разработки. Также вы узнаете, почему автор статьи решил разработать новый фреймворк на Scala, благодаря которому удалось сократить количество строк кода с 30 тысяч (на React) до одной тысячи.
[Читать дальше →][2]
[1]: https://www.infoq.com/articles/more-than-react-part-i
[2]: https://habrahabr.ru/post/324748/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 15:00:04
_Перевод [статьи][1], посвящённой использованию ReactJS для создания фронтенда._
React — отличный инструмент для реализации простых интерактивных веб-сайтов. Но насколько он применим в сложных фронтенд-проектах? Работает ли он там столь же хорошо?
В этой статье мы рассмотрим некоторые проблемы, с которыми можно столкнуться при использовании React во время веб-разработки. Также вы узнаете, почему автор статьи решил разработать новый фреймворк на Scala, благодаря которому удалось сократить количество строк кода с 30 тысяч (на React) до одной тысячи.
[Читать дальше →][2]
[1]: https://www.infoq.com/articles/more-than-react-part-i
[2]: https://habrahabr.ru/post/324748/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Геометрия машинного обучения. Разделяющие гиперплоскости или в чём геометрический смысл линейной комбинации?
habra.16
habrabot(difrex,1) — All
2017-03-24 15:00:04
Во многих алгоритмах машинного обучения, в том числе в нейронных сетях, нам постоянно приходится иметь дело со взвешенной суммой или, иначе, линейной комбинацией компонент входного вектора. А в чём смысл получаемого скалярного значения?
В статье попробуем ответить на этот вопрос с примерами, формулами, а также множеством иллюстраций и кода на Python, чтобы вы могли легко всё воспроизвести и поставить свои собственные эксперименты. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/324736/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 15:00:04
Во многих алгоритмах машинного обучения, в том числе в нейронных сетях, нам постоянно приходится иметь дело со взвешенной суммой или, иначе, линейной комбинацией компонент входного вектора. А в чём смысл получаемого скалярного значения?
В статье попробуем ответить на этот вопрос с примерами, формулами, а также множеством иллюстраций и кода на Python, чтобы вы могли легко всё воспроизвести и поставить свои собственные эксперименты. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/324736/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Недокументированные возможности Windows: скрываем изменения в реестре от программ, работающих с неактивным реестром
habra.16
habrabot(difrex,1) — All
2017-03-24 18:00:04
Можно ли создать такой ключ реестра, который будет виден в Windows в составе активного (подключенного) реестра, но не будет виден программам, работающим с неактивным (отключенным) реестром? Оказывается, если у вас есть возможность изменить лишь одну переменную ядра (например, с помощью драйвера), то да, способ есть.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324746/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 18:00:04
Можно ли создать такой ключ реестра, который будет виден в Windows в составе активного (подключенного) реестра, но не будет виден программам, работающим с неактивным (отключенным) реестром? Оказывается, если у вас есть возможность изменить лишь одну переменную ядра (например, с помощью драйвера), то да, способ есть.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324746/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Дефекты безопасности, которые устранила команда PVS-Studio на этой неделе: выпуск N3
habra.16
habrabot(difrex,1) — All
2017-03-24 18:00:04
![Правим потенциальные уязвимости][1]
Мы решили в меру своих сил регулярно искать и устранять потенциальные уязвимости и баги в различных проектах. Можно назвать это помощью open-source проектам. Можно — разновидностью рекламы или тестированием анализатора. Еще вариант — очередной способ привлечения внимания к вопросам качества и надёжности кода. На самом деле, не важно название, просто нам нравится это делать. Назовём это необычным хобби. Давайте посмотрим, что интересного было обнаружено в коде различных проектов на этой неделе. Мы нашли время сделать исправления и предлагаем вам ознакомиться с ними.
[Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/b68/6c1/0b3/b686c10b311adba53da6e21dc90355ec.png
[2]: https://habrahabr.ru/post/324802/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 18:00:04
![Правим потенциальные уязвимости][1]
Мы решили в меру своих сил регулярно искать и устранять потенциальные уязвимости и баги в различных проектах. Можно назвать это помощью open-source проектам. Можно — разновидностью рекламы или тестированием анализатора. Еще вариант — очередной способ привлечения внимания к вопросам качества и надёжности кода. На самом деле, не важно название, просто нам нравится это делать. Назовём это необычным хобби. Давайте посмотрим, что интересного было обнаружено в коде различных проектов на этой неделе. Мы нашли время сделать исправления и предлагаем вам ознакомиться с ними.
[Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/b68/6c1/0b3/b686c10b311adba53da6e21dc90355ec.png
{kind=link}
[2]: https://habrahabr.ru/post/324802/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Эврика! Моменты озарения при изучении React
habra.16
habrabot(difrex,1) — All
2017-03-24 18:00:04
Светлана Шаповалова, редактор [«Нетологии»][1], перевела [статью][2] Тайлера МакГинниса, в которой он перечислил основные моменты озарения, которые возникают при изучении React.
![image][3]
Одна из моих главных преподавательских задач — сделать так, чтобы у людей чаще случались моменты озарения. «Эврика!» — это момент внезапного прояснения, когда ранее непонятные факты вдруг обретают смысл. Такое случалось с каждым. Я знаком со многими преподавателями и лучшие из них умеют так преподносить урок, чтобы озарение у учеников возникало намного чаще.
[Читать дальше →][4]
[1]: http://netology.ru/development/programs?utm_source=blog&utm_medium=747&utm_campaign=habr
[2]: https://medium.freecodecamp.com/react-aha-moments-4b92bd36cc4e#.x98mxxjvb
[3]: https://habrastorage.org/files/9a4/67d/9f2/9a467d9f2b2142da9cb1e31e556e1f6b.png
[4]: https://habrahabr.ru/post/324788/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 18:00:04
Светлана Шаповалова, редактор [«Нетологии»][1], перевела [статью][2] Тайлера МакГинниса, в которой он перечислил основные моменты озарения, которые возникают при изучении React.
![image][3]
Одна из моих главных преподавательских задач — сделать так, чтобы у людей чаще случались моменты озарения. «Эврика!» — это момент внезапного прояснения, когда ранее непонятные факты вдруг обретают смысл. Такое случалось с каждым. Я знаком со многими преподавателями и лучшие из них умеют так преподносить урок, чтобы озарение у учеников возникало намного чаще.
[Читать дальше →][4]
[1]: http://netology.ru/development/programs?utm_source=blog&utm_medium=747&utm_campaign=habr
[2]: https://medium.freecodecamp.com/react-aha-moments-4b92bd36cc4e#.x98mxxjvb
[3]: https://habrastorage.org/files/9a4/67d/9f2/9a467d9f2b2142da9cb1e31e556e1f6b.png
{kind=link}
[4]: https://habrahabr.ru/post/324788/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[recovery mode] Умнеющие города
habra.16
habrabot(difrex,1) — All
2017-03-24 18:30:04
Мы все наслышаны о тех социальных и экологических проблемах, которые возникают на фоне постоянной глобальной урбанизации. Однако, технологии умного города, кажется, способны дать ответы на многие из поставленных вопросов, и не только решить проблемы климатических изменений, перенаселения или чрезмерного потребления ресурсов – умные технологии способны сделать наши жизни еще удобнее и комфортнее. О каких технологиях идет речь?
[Читать дальше: Как города умнеют][1]
[1]: https://habrahabr.ru/post/324410/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 18:30:04
Мы все наслышаны о тех социальных и экологических проблемах, которые возникают на фоне постоянной глобальной урбанизации. Однако, технологии умного города, кажется, способны дать ответы на многие из поставленных вопросов, и не только решить проблемы климатических изменений, перенаселения или чрезмерного потребления ресурсов – умные технологии способны сделать наши жизни еще удобнее и комфортнее. О каких технологиях идет речь?
[Читать дальше: Как города умнеют][1]
[1]: https://habrahabr.ru/post/324410/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Security Week 12: опасная фича в Windows, китайские хакеры сломали все вокруг, инспектировать HTTPS надо с умом
habra.16
habrabot(difrex,1) — All
2017-03-24 22:30:03
Порой плохую фичу сложно отличить от хорошего бага. В каком-то смысле она даже хуже бага – фиксить-то ее не будут. Вот и Microsoft уже шестой год знает о симпатичной возможности перехвата сессии любого пользователя локальным администратором. Погодите, это же админ, ему все можно! Однако давайте разберемся что здесь не так.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324820/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-24 22:30:03
Порой плохую фичу сложно отличить от хорошего бага. В каком-то смысле она даже хуже бага – фиксить-то ее не будут. Вот и Microsoft уже шестой год знает о симпатичной возможности перехвата сессии любого пользователя локальным администратором. Погодите, это же админ, ему все можно! Однако давайте разберемся что здесь не так.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324820/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
«Новая эра Web»: Университет ИТМО начинает подготовку IT-специалистов в области нейротехнологий
habra.16
habrabot(difrex,1) — All
2017-03-25 00:30:04
Мировая наука уже длительное время ломает голову над пониманием устройства и принципов работы человеческого мозга. Этот чрезвычайно сложный орган является объектом изучения во многих исследованиях.
Примерами могут быть [Brain Initiative][1] и [Human Brain Project][2], которые стоят на пересечении таких областей, как медицина, биология и нейроинформатика.
На сегодняшний день рынок нейротехнологий оценивается в 180 миллиардов долларов, и эксперты [прогнозируют][3], что эта цифра вырастет до 1 триллиона к 2035 году.
[![][4]][5] [Читать дальше →][6]
[1]: https://braininitiative.nih.gov/
[2]: https://www.humanbrainproject.eu/
[3]: https://ria.ru/economy/20161002/1478311692.html
[4]: https://habrastorage.org/files/e39/83d/e42/e3983de42fc6424cae948556ef12cc4d.jpg
[5]: https://habrahabr.ru/company/spbifmo/blog/324780/
[6]: https://habrahabr.ru/post/324780/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-25 00:30:04
Мировая наука уже длительное время ломает голову над пониманием устройства и принципов работы человеческого мозга. Этот чрезвычайно сложный орган является объектом изучения во многих исследованиях.
Примерами могут быть [Brain Initiative][1] и [Human Brain Project][2], которые стоят на пересечении таких областей, как медицина, биология и нейроинформатика.
На сегодняшний день рынок нейротехнологий оценивается в 180 миллиардов долларов, и эксперты [прогнозируют][3], что эта цифра вырастет до 1 триллиона к 2035 году.
[![][4]][5] [Читать дальше →][6]
[1]: https://braininitiative.nih.gov/
[2]: https://www.humanbrainproject.eu/
[3]: https://ria.ru/economy/20161002/1478311692.html
[4]: https://habrastorage.org/files/e39/83d/e42/e3983de42fc6424cae948556ef12cc4d.jpg
{kind=link}
[5]: https://habrahabr.ru/company/spbifmo/blog/324780/
[6]: https://habrahabr.ru/post/324780/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Бесплатная пицца] Взлом сайта доставки пиццы, взлом mobidel.ru
habra.16
habrabot(difrex,1) — All
2017-03-25 02:00:03
Я часто заказываю пиццу в Одессе, больше всего люблю доставку [pizza.od.ua][1], там не жалеют начинки и можно создать пиццу из своих ингредиентов, в других же службах доставки можно выбрать только ту пиццу, которую тебе предлагают, добавить еще ингредиентов или выбрать другие нельзя. Месяца два назад я подсел на суши в pizza.od.ua. С недавних пор суши временно не доставляют, тогда я нашёл другую доставку суши и пиццы.
Я решил проверить её на уязвимости.
**Первая уязвимость** — самая популярная на таких сайтах — это отсутствие проверки суммы платежа за товар(**iDOR**). [Читать дальше →][2]
[1]: http://pizza.od.ua/
[2]: https://habrahabr.ru/post/321116/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-25 02:00:03
Я часто заказываю пиццу в Одессе, больше всего люблю доставку [pizza.od.ua][1], там не жалеют начинки и можно создать пиццу из своих ингредиентов, в других же службах доставки можно выбрать только ту пиццу, которую тебе предлагают, добавить еще ингредиентов или выбрать другие нельзя. Месяца два назад я подсел на суши в pizza.od.ua. С недавних пор суши временно не доставляют, тогда я нашёл другую доставку суши и пиццы.
Я решил проверить её на уязвимости.
**Первая уязвимость** — самая популярная на таких сайтах — это отсутствие проверки суммы платежа за товар(**iDOR**). [Читать дальше →][2]
[1]: http://pizza.od.ua/
[2]: https://habrahabr.ru/post/321116/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Соревнование mlbootcamp от mail.ru, кратко о рецепте второго места
habra.16
habrabot(difrex,1) — All
2017-03-25 12:00:05
Добрый день, читатель! Данная статья расскажет о пути получения второго места на соревновании MLBootCamp III. Для тех, кто не в курсе — это соревнование по машинному обучению и анализу данных от Mail.Ru Group, проходило с 15 февраля по 15 марта.
В статье будет коротко про историю построения решения, немного советов про то, на чем набил шишек и благодарности) Итак, поехали.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324732/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-25 12:00:05
Добрый день, читатель! Данная статья расскажет о пути получения второго места на соревновании MLBootCamp III. Для тех, кто не в курсе — это соревнование по машинному обучению и анализу данных от Mail.Ru Group, проходило с 15 февраля по 15 марта.
В статье будет коротко про историю построения решения, немного советов про то, на чем набил шишек и благодарности) Итак, поехали.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324732/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Соревнование mlbootcamp от mail.ru. Кратко о рецепте второго места
habra.16
habrabot(difrex,1) — All
2017-03-25 17:00:03
Добрый день, читатель! Данная статья расскажет о пути получения второго места на соревновании MLBootCamp III. Для тех, кто не в курсе — это соревнование по машинному обучению и анализу данных от Mail.Ru Group, проходило с 15 февраля по 15 марта.
В статье будет коротко про историю построения решения, немного советов про то, на чем набил шишек и благодарности.
Итак, поехали.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324732/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-25 17:00:03
Добрый день, читатель! Данная статья расскажет о пути получения второго места на соревновании MLBootCamp III. Для тех, кто не в курсе — это соревнование по машинному обучению и анализу данных от Mail.Ru Group, проходило с 15 февраля по 15 марта.
В статье будет коротко про историю построения решения, немного советов про то, на чем набил шишек и благодарности.
Итак, поехали.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324732/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Java-конференция JBreak 2017, или Зачем Charles Nutter едет в Новосибирск из Миннеаполиса
habra.16
habrabot(difrex,1) — All
2017-03-26 15:30:04
[Charles Nutter][1] — JVM-разработчик из Red Hat, работающий на OpenJDK, мейнтейнер проекта JRuby, Java Champion и Ruby Hero, первоклассный специалист и спикер многих Java-конференций. Впервые в Россию он приехал в прошлом году на Joker 2016, где выступил с двумя [хардкорными докладами][2], после чего признался в том, что не ожидал такого теплого приема и решил во что бы то ни стало вернуться в Россию:
> The Russian people are warm, friendly, and intelligent. They welcomed me to their country to teach and learn. We must strive to be friends.
>
> — Charles Nutter (@headius) [October 17, 2016][3]
Все сложилось удачно, и Charles запланировал визиты в Новосибирск (JBreak, 4 апреля) и в Москву (JPoint, 7-8 апреля). [Обзор программы JPoint 2017][4] мы уже делали, вот руки дошли и до JBreak 2017. Под катом – длиннопост про всех, кто будет выступать в Новосибе, и про все, что они будут рассказывать.
[Читать дальше →][5]
[1]: https://twitter.com/headius
[2]: http://2016.jokerconf.com/speakers/charles-nutter/
[3]: https://twitter.com/headius/status/788079926159216640
[4]: https://habrahabr.ru/company/jugru/blog/323040/
[5]: https://habrahabr.ru/post/324668/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-26 15:30:04
[Charles Nutter][1] — JVM-разработчик из Red Hat, работающий на OpenJDK, мейнтейнер проекта JRuby, Java Champion и Ruby Hero, первоклассный специалист и спикер многих Java-конференций. Впервые в Россию он приехал в прошлом году на Joker 2016, где выступил с двумя [хардкорными докладами][2], после чего признался в том, что не ожидал такого теплого приема и решил во что бы то ни стало вернуться в Россию:
> The Russian people are warm, friendly, and intelligent. They welcomed me to their country to teach and learn. We must strive to be friends.
>
> — Charles Nutter (@headius) [October 17, 2016][3]
Все сложилось удачно, и Charles запланировал визиты в Новосибирск (JBreak, 4 апреля) и в Москву (JPoint, 7-8 апреля). [Обзор программы JPoint 2017][4] мы уже делали, вот руки дошли и до JBreak 2017. Под катом – длиннопост про всех, кто будет выступать в Новосибе, и про все, что они будут рассказывать.
[Читать дальше →][5]
[1]: https://twitter.com/headius
[2]: http://2016.jokerconf.com/speakers/charles-nutter/
[3]: https://twitter.com/headius/status/788079926159216640
[4]: https://habrahabr.ru/company/jugru/blog/323040/
[5]: https://habrahabr.ru/post/324668/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Из песочницы] Как я SQLAlchemy удобной сделал
habra.16
habrabot(difrex,1) — All
2017-03-26 19:00:04
Не секрет, что [SQLAlchemy][1] — самая популярная ORM на Python. Она позволяет писать куда более продвинутые вещи, чем большинство Active Record собратьев. Но плата за это — более сложный код, и в простых задачах вроде CRUD это напрягает.
О том, как я сделал Алхимию удобной, воспользовавшись опытом лучших Active Record ORM, читайте под катом.
[Читать дальше →][2]
[1]: https://www.sqlalchemy.org/
[2]: https://habrahabr.ru/post/324876/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-26 19:00:04
Не секрет, что [SQLAlchemy][1] — самая популярная ORM на Python. Она позволяет писать куда более продвинутые вещи, чем большинство Active Record собратьев. Но плата за это — более сложный код, и в простых задачах вроде CRUD это напрягает.
О том, как я сделал Алхимию удобной, воспользовавшись опытом лучших Active Record ORM, читайте под катом.
[Читать дальше →][2]
[1]: https://www.sqlalchemy.org/
[2]: https://habrahabr.ru/post/324876/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Элементы, универсумы и регистры правил
habra.16
habrabot(difrex,1) — All
2017-03-27 00:00:04
_"Дуэли запрещены в субботу, воскресенье и остальные дни недели."_
Речь в статье пойдет о некоторых нюансах операции выборки данных. Эта довольно востребованная в информационных системах операция сводится фактически к определению принадлежности значений (элементов) множествам. Табличная функция, содержащая значения-множества, называется регистром правил. При наличии нескольких множеств, которым принадлежит элемент, возникает вопрос определения наиболее релевантного из них. Вопросам оценки релевантности выборки данных посвящена первая часть работы.
![][1]
Забегая вперед, укажем, что основным результатом (многолетних наблюдений) является то, что в реляционных отношениях следует учитывать род атрибутов — являются ли значения атрибута отношения конкретными (элементами) или абстрактными (множествами). При этом в операции выборки данных атрибуты входной таблицы и таблицы, к которой обращаются, должны быть _разных родов_. Более подробно об этом — во 2-й части.
И еще одна оговорка. Там, где приходилось выбирать между простотой (понятностью) описания и его строгостью, автор старался выбирать простоту (хотя слов, в том числе не всегда понятных, все равно набралось много).
[Читать дальше →][2]
[1]: https://habrastorage.org/files/7ac/9c8/ee1/7ac9c8ee10a542e88f8c387c75118032.png
[2]: https://habrahabr.ru/post/324710/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 00:00:04
_"Дуэли запрещены в субботу, воскресенье и остальные дни недели."_
Речь в статье пойдет о некоторых нюансах операции выборки данных. Эта довольно востребованная в информационных системах операция сводится фактически к определению принадлежности значений (элементов) множествам. Табличная функция, содержащая значения-множества, называется регистром правил. При наличии нескольких множеств, которым принадлежит элемент, возникает вопрос определения наиболее релевантного из них. Вопросам оценки релевантности выборки данных посвящена первая часть работы.
![][1]
Забегая вперед, укажем, что основным результатом (многолетних наблюдений) является то, что в реляционных отношениях следует учитывать род атрибутов — являются ли значения атрибута отношения конкретными (элементами) или абстрактными (множествами). При этом в операции выборки данных атрибуты входной таблицы и таблицы, к которой обращаются, должны быть _разных родов_. Более подробно об этом — во 2-й части.
И еще одна оговорка. Там, где приходилось выбирать между простотой (понятностью) описания и его строгостью, автор старался выбирать простоту (хотя слов, в том числе не всегда понятных, все равно набралось много).
[Читать дальше →][2]
[1]: https://habrastorage.org/files/7ac/9c8/ee1/7ac9c8ee10a542e88f8c387c75118032.png
{kind=link}
[2]: https://habrahabr.ru/post/324710/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Проект выходного дня сотрудника IBM и его сына: виртуальный помощник по кибербезопасности Havyn
habra.16
habrabot(difrex,1) — All
2017-03-27 06:30:04
![][1]
Эван Спайсек — 11 летний сын сотрудника IBM Майка Спайсека. Однажды сыну и отцу пришла в голову идея сделать что-то вместе на выходных. Но они не стали создавать очередной скворечник. Вместо этого было решено разработать голосового помощника типа Джарвиса из «Железного человека». Новая разработка получила название Havyn. По принципу работы он больше похож на голосового ассистента корпорации Amazon, Alexa.
Но Havyn не подключается по запросу к облаку с музыкой, вместо этого он занимается защитой своего владельца от различных киберугроз. Функции этого помощника довольно специфичны, но именно таков был выбор Майка и Эвана Спайсеков. Изначально Havyn умел только отвечать на текстовые запросы, введенные с клавиатуры. Чуть позже его обучили распознавать и голосовые запросы.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/754/ca4/879/754ca48791034d0fb552953b40ea84e3.jpg
[2]: https://habrahabr.ru/post/324826/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 06:30:04
![][1]
Эван Спайсек — 11 летний сын сотрудника IBM Майка Спайсека. Однажды сыну и отцу пришла в голову идея сделать что-то вместе на выходных. Но они не стали создавать очередной скворечник. Вместо этого было решено разработать голосового помощника типа Джарвиса из «Железного человека». Новая разработка получила название Havyn. По принципу работы он больше похож на голосового ассистента корпорации Amazon, Alexa.
Но Havyn не подключается по запросу к облаку с музыкой, вместо этого он занимается защитой своего владельца от различных киберугроз. Функции этого помощника довольно специфичны, но именно таков был выбор Майка и Эвана Спайсеков. Изначально Havyn умел только отвечать на текстовые запросы, введенные с клавиатуры. Чуть позже его обучили распознавать и голосовые запросы.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/754/ca4/879/754ca48791034d0fb552953b40ea84e3.jpg
{kind=link}
[2]: https://habrahabr.ru/post/324826/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Как Discord индексирует миллиарды сообщений
habra.16
habrabot(difrex,1) — All
2017-03-27 13:30:04
![][1]
[Миллионы пользователей ежемесячно отправляют миллиарды сообщений в Discord][2]. Поиск в этих сообщениях стал [одной из самых востребованных функций][3], какие мы сделали. _Да будет поиск!_
# Требования
* **Экономически эффективный:** Основное взаимодействие пользователя с Discord — это наш текстовый и голосовой чат. Поиск — вспомогательная функция, и стоимость инфраструктуры должна отражать это. В идеале это значит, что поиск не должен стоить дороже, чем фактическое хранение сообщений.
* **Быстрый и интуитивно понятный:** Все создаваемые нами функции должны быть быстрыми и интуитивными, в том числе поиск. Он должен выглядеть и ощущаться по высшему стандарту.
* **Самовосстановление:** У нас нет отдела DevOps (пока), так что поиск должен выдерживать сбои с минимальным человеческим вмешательством или вообще без него.
* **Линейно масштабируемый:** Как и с хранением сообщений, увеличение ёмкости поисковой инфраструктуры [должно предусматривать добавление нодов][4].
* **Ленивая индексация:** Не все пользуются поиском — мы не должны индексировать сообщения, пока кто-то не попытается хотя бы раз их найти. Вдобавок, после сбоя индекса должна быть возможность переиндексации серверов на лету.[Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/d88/dd7/f7d/d88dd7f7d1ef3c461a37c1d14998685d.png
[2]: https://habrahabr.ru/post/323694/
[3]: https://feedback.discordapp.com/forums/326712-discord-dream-land/suggestions/10313166-add-a-search-function-ctrl-f
[4]: https://blog.discordapp.com/how-discord-stores-billions-of-messages-7fa6ec7ee4c7#805e
[5]: https://habrahabr.ru/post/324902/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 13:30:04
![][1]
[Миллионы пользователей ежемесячно отправляют миллиарды сообщений в Discord][2]. Поиск в этих сообщениях стал [одной из самых востребованных функций][3], какие мы сделали. _Да будет поиск!_
# Требования
* **Экономически эффективный:** Основное взаимодействие пользователя с Discord — это наш текстовый и голосовой чат. Поиск — вспомогательная функция, и стоимость инфраструктуры должна отражать это. В идеале это значит, что поиск не должен стоить дороже, чем фактическое хранение сообщений.
* **Быстрый и интуитивно понятный:** Все создаваемые нами функции должны быть быстрыми и интуитивными, в том числе поиск. Он должен выглядеть и ощущаться по высшему стандарту.
* **Самовосстановление:** У нас нет отдела DevOps (пока), так что поиск должен выдерживать сбои с минимальным человеческим вмешательством или вообще без него.
* **Линейно масштабируемый:** Как и с хранением сообщений, увеличение ёмкости поисковой инфраструктуры [должно предусматривать добавление нодов][4].
* **Ленивая индексация:** Не все пользуются поиском — мы не должны индексировать сообщения, пока кто-то не попытается хотя бы раз их найти. Вдобавок, после сбоя индекса должна быть возможность переиндексации серверов на лету.[Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/d88/dd7/f7d/d88dd7f7d1ef3c461a37c1d14998685d.png
{kind=link}
[2]: https://habrahabr.ru/post/323694/
[3]: https://feedback.discordapp.com/forums/326712-discord-dream-land/suggestions/10313166-add-a-search-function-ctrl-f
[4]: https://blog.discordapp.com/how-discord-stores-billions-of-messages-7fa6ec7ee4c7#805e
[5]: https://habrahabr.ru/post/324902/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Из песочницы] Варим ML Boot Camp III: Starter Kit
habra.16
habrabot(difrex,1) — All
2017-03-27 14:00:04
![][1]
16 марта закончилось соревнование по машинному обучению [ML Boot Camp III][2]. Я не настоящий сварщик, но, тем не менее, смог добиться 7го места в финальной таблице результатов. В данной статье я хотел бы поделиться тем, как начать участвовать в такого рода чемпионатах, на что стоит обратить внимание в первый раз при решении задачи и рассказать о своем подходе.
[Читать дальше →][3]
[1]: https://habrastorage.org/files/26e/678/ae8/26e678ae84194809860d400f066ec2bc.png
[2]: http://mlbootcamp.ru/championship/10/
[3]: https://habrahabr.ru/post/324924/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 14:00:04
![][1]
16 марта закончилось соревнование по машинному обучению [ML Boot Camp III][2]. Я не настоящий сварщик, но, тем не менее, смог добиться 7го места в финальной таблице результатов. В данной статье я хотел бы поделиться тем, как начать участвовать в такого рода чемпионатах, на что стоит обратить внимание в первый раз при решении задачи и рассказать о своем подходе.
[Читать дальше →][3]
[1]: https://habrastorage.org/files/26e/678/ae8/26e678ae84194809860d400f066ec2bc.png
{kind=link}
[2]: http://mlbootcamp.ru/championship/10/
[3]: https://habrahabr.ru/post/324924/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Pygest #6. Релизы, статьи, интересные проекты из мира Python [14 марта 2017 — 27 марта 2017]
habra.16
habrabot(difrex,1) — All
2017-03-27 14:30:03
![image][1] Всем привет! Это уже шестой выпуск дайджеста на Хабрахабр о новостях из мира Python. В сегодняшнем выпуске вы найдёте интересные материалы, касающиеся машинного обучения, профилирования и оптимизации Python-приложений, хороших практик при написании Python-кода и многого другого. Присылайте свои актуальные материалы, а также любые замечания и предложения, которые будут добавлены в ближайший дайджест.
А теперь к делу!
[Перейти к дайджесту][2]
[1]: https://habrastorage.org/files/aa2/815/f22/aa2815f2207940fab9ac72e85219fe3c.png
[2]: https://habrahabr.ru/post/324852/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 14:30:03
![image][1] Всем привет! Это уже шестой выпуск дайджеста на Хабрахабр о новостях из мира Python. В сегодняшнем выпуске вы найдёте интересные материалы, касающиеся машинного обучения, профилирования и оптимизации Python-приложений, хороших практик при написании Python-кода и многого другого. Присылайте свои актуальные материалы, а также любые замечания и предложения, которые будут добавлены в ближайший дайджест.
А теперь к делу!
[Перейти к дайджесту][2]
[1]: https://habrastorage.org/files/aa2/815/f22/aa2815f2207940fab9ac72e85219fe3c.png
{kind=link}
[2]: https://habrahabr.ru/post/324852/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Расширения Intel SGX, учебное руководство. Предисловие и полное содержание курса
habra.16
habrabot(difrex,1) — All
2017-03-27 15:30:04
![][1]
В течение последних месяцев в блоге Intel публиковался русский перевод цикла обучающих статей с ресурса [Intel Developer Zone][2], посвященный использованию расширений [Intel Software Guard Extensions][3] в программировании — [Intel SGX Tutorial][4]. Публикация растянулась во времени, поэтому для тех, кто решил методично изучать данный вопрос, мы сделали общий индекс статей как на языке оригинала, так и на русском. После выхода новых постов (а автор обещает продолжение) и их перевода они также будут сюда добавлены.
Под катом вы также найдете требования к ПО и «железу» для изучения курса.
[Читать дальше →][5]
[1]: https://habrastorage.org/files/dd7/7b8/ea2/dd77b8ea29d9464d9b12690afcb03ea6.jpg
[2]: https://software.intel.com/en-us/
[3]: https://software.intel.com/en-us/sgx
[4]: https://software.intel.com/en-us/articles/introducing-the-intel-software-guard-extensions-tutorial-series
[5]: https://habrahabr.ru/post/324674/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 15:30:04
![][1]
В течение последних месяцев в блоге Intel публиковался русский перевод цикла обучающих статей с ресурса [Intel Developer Zone][2], посвященный использованию расширений [Intel Software Guard Extensions][3] в программировании — [Intel SGX Tutorial][4]. Публикация растянулась во времени, поэтому для тех, кто решил методично изучать данный вопрос, мы сделали общий индекс статей как на языке оригинала, так и на русском. После выхода новых постов (а автор обещает продолжение) и их перевода они также будут сюда добавлены.
Под катом вы также найдете требования к ПО и «железу» для изучения курса.
[Читать дальше →][5]
[1]: https://habrastorage.org/files/dd7/7b8/ea2/dd77b8ea29d9464d9b12690afcb03ea6.jpg
{kind=link}
[2]: https://software.intel.com/en-us/
[3]: https://software.intel.com/en-us/sgx
[4]: https://software.intel.com/en-us/articles/introducing-the-intel-software-guard-extensions-tutorial-series
[5]: https://habrahabr.ru/post/324674/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Открытый курс машинного обучения. Тема 5. Композиции: бэггинг, случайный лес
habra.16
habrabot(difrex,1) — All
2017-03-27 16:00:04
Привет всем, кто дожил до пятой темы нашего курса!
Курс собрал уже более 1000 участников, из них первые 3 домашних задания сделали 520, 450 и 360 человек соответственно. Около 200 участников пока идут с максимальным баллом. Отток намного ниже, чем в MOOC-ах, даже несмотря на большой объем наших статей.
Данное занятие мы посвятим простым методам композиции: бэггингу и случайному лесу. Вы узнаете, как можно получить распределение среднего по генеральной совокупности, если у нас есть информация только о небольшой ее части; посмотрим, как с помощью композиции алгоритмов уменьшить дисперсию, и таким образом улучшим точность модели; разберём, что такое случайный лес, какие его параметры нужно «подкручивать» и как найти самый важный признак. Сконцентрируемся на практике, добавив «щепотку» математики.
**Список статей серии**
1. [Первичный анализ данных с Pandas][1]
2. [Визуальный анализ данных c Python][2]
3. [Классификация, деревья решений и метод ближайших соседей][3]
4. [Линейные модели классификации и регрессии][4]
5. [Композиции: бэггинг, случайный лес][5]
6. Обучение без учителя: PCA, кластеризация, поиск аномалий
7. Искусство построения и отбора признаков. Приложения в задачах обработки текста, изображений и гео-данных
[Читать дальше →][6]
[1]: https://habrahabr.ru/company/ods/blog/322626/
[2]: https://habrahabr.ru/company/ods/blog/323210/
[3]: https://habrahabr.ru/company/ods/blog/322534/
[4]: https://habrahabr.ru/company/ods/blog/323890/
[5]: https://habrahabr.ru/company/ods/blog/324402/
[6]: https://habrahabr.ru/post/324402/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 16:00:04
Привет всем, кто дожил до пятой темы нашего курса!
Курс собрал уже более 1000 участников, из них первые 3 домашних задания сделали 520, 450 и 360 человек соответственно. Около 200 участников пока идут с максимальным баллом. Отток намного ниже, чем в MOOC-ах, даже несмотря на большой объем наших статей.
Данное занятие мы посвятим простым методам композиции: бэггингу и случайному лесу. Вы узнаете, как можно получить распределение среднего по генеральной совокупности, если у нас есть информация только о небольшой ее части; посмотрим, как с помощью композиции алгоритмов уменьшить дисперсию, и таким образом улучшим точность модели; разберём, что такое случайный лес, какие его параметры нужно «подкручивать» и как найти самый важный признак. Сконцентрируемся на практике, добавив «щепотку» математики.
**Список статей серии**
1. [Первичный анализ данных с Pandas][1]
2. [Визуальный анализ данных c Python][2]
3. [Классификация, деревья решений и метод ближайших соседей][3]
4. [Линейные модели классификации и регрессии][4]
5. [Композиции: бэггинг, случайный лес][5]
6. Обучение без учителя: PCA, кластеризация, поиск аномалий
7. Искусство построения и отбора признаков. Приложения в задачах обработки текста, изображений и гео-данных
[Читать дальше →][6]
[1]: https://habrahabr.ru/company/ods/blog/322626/
[2]: https://habrahabr.ru/company/ods/blog/323210/
[3]: https://habrahabr.ru/company/ods/blog/322534/
[4]: https://habrahabr.ru/company/ods/blog/323890/
[5]: https://habrahabr.ru/company/ods/blog/324402/
[6]: https://habrahabr.ru/post/324402/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Ученые вылечили ИИ от забывчивости
habra.16
habrabot(difrex,1) — All
2017-03-27 16:00:04
Искусственные нейронные сети отличаются от биологических аналогов неспособностью «запомнить» прошлые навыки при обучении новой задаче. Искусственный интеллект, [натренированный][1] на распознавание собак, не сможет различать людей. Для этого его придется переобучить, однако при этом сеть «забудет» о существовании собак. То же касается и игр – ИИ, умеющий играть в покер, не выиграет в шахматы.
Эта особенность называется «катастрофической забывчивостью» (catastrophic forgetting). Однако ученые из компании DeepMind и Имперского колледжа Лондона разработали алгоритм обучения глубоких нейронных сетей, который способен приобретать новые навыки, сохраняя «память» о предыдущих задачах.
[ ![][2]][3] [Читать дальше →][4]
[1]: http://siliconangle.com/blog/2017/03/16/googles-deepmind-overcomes-rather-tricky-problem-forgetfulness/
[2]: https://habrastorage.org/files/998/56e/4ff/99856e4ffb35498fb734f1683f4e21d9.jpg
[3]: https://habrahabr.ru/company/it-grad/blog/323948/
[4]: https://habrahabr.ru/post/323948/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 16:00:04
Искусственные нейронные сети отличаются от биологических аналогов неспособностью «запомнить» прошлые навыки при обучении новой задаче. Искусственный интеллект, [натренированный][1] на распознавание собак, не сможет различать людей. Для этого его придется переобучить, однако при этом сеть «забудет» о существовании собак. То же касается и игр – ИИ, умеющий играть в покер, не выиграет в шахматы.
Эта особенность называется «катастрофической забывчивостью» (catastrophic forgetting). Однако ученые из компании DeepMind и Имперского колледжа Лондона разработали алгоритм обучения глубоких нейронных сетей, который способен приобретать новые навыки, сохраняя «память» о предыдущих задачах.
[ ![][2]][3] [Читать дальше →][4]
[1]: http://siliconangle.com/blog/2017/03/16/googles-deepmind-overcomes-rather-tricky-problem-forgetfulness/
[2]: https://habrastorage.org/files/998/56e/4ff/99856e4ffb35498fb734f1683f4e21d9.jpg
{kind=link}
[3]: https://habrahabr.ru/company/it-grad/blog/323948/
[4]: https://habrahabr.ru/post/323948/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
FLIF – идеальный формат для изображений?
habra.16
habrabot(difrex,1) — All
2017-03-27 18:30:04
![FLIF][1]
Как формат JPEG произвел в свое время революцию среди форматов изображений, так и новый формат FLIF обещает такого же масштаба событие для дизайнеров и веб-разработчиков.
[FLIF (Free Lossless Image Format)][2] – новый формат файлов для изображений, обеспечивающий беспрецедентное сжатие без потерь. Файлы получаются:
* На 14% меньше, чем WebP, без потерь
* На 22% меньше, чем BPG, без потерь
* На 33% меньше, чем сжатый через ZopfliPNG PNG-файл
* На 43% меньше, чем обычные PNG-файлы
* На 46% меньше, чем оптимизированные по Adam7 чересстрочные PNG-файлы
* На 53% меньше, чем JPEG 2000, без потерь
* На 74% меньше, чем JPEG XR, без потерь
На Хабре [уже опубликовано][3] [пару статей][4] на тему FLIF. Но мы пойдем дальше: какую еще практическую пользу несет формат, кроме меньшего размера для любого типа изображений?
[Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/bb0/7df/665/bb07df665c2b23f5f3ebb0ff4631ade2.png
[2]: http://flif.info
[3]: https://habrahabr.ru/post/278745/
[4]: https://habrahabr.ru/post/306210/
[5]: https://habrahabr.ru/post/324952/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 18:30:04
![FLIF][1]
Как формат JPEG произвел в свое время революцию среди форматов изображений, так и новый формат FLIF обещает такого же масштаба событие для дизайнеров и веб-разработчиков.
[FLIF (Free Lossless Image Format)][2] – новый формат файлов для изображений, обеспечивающий беспрецедентное сжатие без потерь. Файлы получаются:
* На 14% меньше, чем WebP, без потерь
* На 22% меньше, чем BPG, без потерь
* На 33% меньше, чем сжатый через ZopfliPNG PNG-файл
* На 43% меньше, чем обычные PNG-файлы
* На 46% меньше, чем оптимизированные по Adam7 чересстрочные PNG-файлы
* На 53% меньше, чем JPEG 2000, без потерь
* На 74% меньше, чем JPEG XR, без потерь
На Хабре [уже опубликовано][3] [пару статей][4] на тему FLIF. Но мы пойдем дальше: какую еще практическую пользу несет формат, кроме меньшего размера для любого типа изображений?
[Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/bb0/7df/665/bb07df665c2b23f5f3ebb0ff4631ade2.png
{kind=link}
[2]: http://flif.info
[3]: https://habrahabr.ru/post/278745/
[4]: https://habrahabr.ru/post/306210/
[5]: https://habrahabr.ru/post/324952/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Глубинное обучение по особенностям заголовка и содержимого статьи для преодоления кликбейта
habra.16
habrabot(difrex,1) — All
2017-03-27 19:30:03
![][1]
_Облако слов для кликбейта_
**TL;DR:** Я добился точности распознавания кликбейта 99,2% на тестовых данных по особенностям заголовка и контента. Код доступен в [репозитории GitHub][2].
Когда-то в прошлом я написал [статью][3] о выявлении кликбейта. Та статья получила хорошие отклики, а также много критики. Некоторые сказали, что нужно учитывать содержимое сайта, другие просили больше примеров из разных источников, а некоторые предложили попробовать методы глубинного обучения.
В этой статье я постараюсь решить эти вопросы и вывести выявление кликбейта на новый уровень.
[Читать дальше →][4]
[1]: https://habrastorage.org/getpro/habr/post_images/06f/e33/dbf/06fe33dbfece2b73856a992675adb1f9.png
[2]: http://github.com/abhishekkrthakur/clickbaits_revisited
[3]: http://www.linkedin.com/pulse/identifying-clickbaits-using-machine-learning-abhishek-thakur
[4]: https://habrahabr.ru/post/324960/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 19:30:03
![][1]
_Облако слов для кликбейта_
**TL;DR:** Я добился точности распознавания кликбейта 99,2% на тестовых данных по особенностям заголовка и контента. Код доступен в [репозитории GitHub][2].
Когда-то в прошлом я написал [статью][3] о выявлении кликбейта. Та статья получила хорошие отклики, а также много критики. Некоторые сказали, что нужно учитывать содержимое сайта, другие просили больше примеров из разных источников, а некоторые предложили попробовать методы глубинного обучения.
В этой статье я постараюсь решить эти вопросы и вывести выявление кликбейта на новый уровень.
[Читать дальше →][4]
[1]: https://habrastorage.org/getpro/habr/post_images/06f/e33/dbf/06fe33dbfece2b73856a992675adb1f9.png
{kind=link}
[2]: http://github.com/abhishekkrthakur/clickbaits_revisited
[3]: http://www.linkedin.com/pulse/identifying-clickbaits-using-machine-learning-abhishek-thakur
[4]: https://habrahabr.ru/post/324960/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Из песочницы] learnopengl. Урок 1.8 — Системы координат
habra.16
habrabot(difrex,1) — All
2017-03-27 19:30:03
В предыдущем уроке мы узнали о том, какую пользу можно получить от преобразования вершин матрицами трансформаций. OpenGL предполагает, что все вершины, которые мы хотим увидеть, после запуска шейдера будут в нормализованных координатах устройства (NDC — normalized device coordinates). Это означает, что x, y и z координаты каждой вершины должны быть между -1.0 и 1.0; координаты вне этого диапазона видны не будут. Обычно мы указываем координаты в диапазоне, который настраиваем самостоятельно, а в вершинном шейдере преобразовываем эти координаты в NDC. Затем, эти NDC передаются растеризатору для преобразования их в двумерные координаты/пикселы вашего экрана.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324968/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 19:30:03
В предыдущем уроке мы узнали о том, какую пользу можно получить от преобразования вершин матрицами трансформаций. OpenGL предполагает, что все вершины, которые мы хотим увидеть, после запуска шейдера будут в нормализованных координатах устройства (NDC — normalized device coordinates). Это означает, что x, y и z координаты каждой вершины должны быть между -1.0 и 1.0; координаты вне этого диапазона видны не будут. Обычно мы указываем координаты в диапазоне, который настраиваем самостоятельно, а в вершинном шейдере преобразовываем эти координаты в NDC. Затем, эти NDC передаются растеризатору для преобразования их в двумерные координаты/пикселы вашего экрана.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324968/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Готовимся к собеседованию по PHP: Всё об итерации и немного про псевдотип «iterable»
habra.16
habrabot(difrex,1) — All
2017-03-27 20:30:04
Не секрет, что на собеседованиях любят задавать каверзные вопросы. Не всегда адекватные, не всегда имеющие отношение к реальности, но факт остается фактом — задают. Конечно, вопрос вопросу рознь, и иногда вопрос, на первый взгляд кажущийся вам дурацким, на самом деле направлен на проверку того, насколько хорошо вы знаете язык, на котором пишете.
И, разумеется, какими бы вам странными и некорректными ни казались вопросы на собеседовании, приходить нужно всё-таки подготовленным, зная тот язык, за программирование на котором вам собираются платить.
![image][1]
Третья часть серии статей посвящена одному из самых объемных понятий в современном PHP — итерации, итераторам и итерируемым сущностям. Я постарался свести в один текст некий минимум знаний об этом вопросе, пригодный для самоподготовки к собеседованию на позицию разработчика на PHP.
Две предыдущие части:
* [Готовимся к собеседованию по PHP: ключевое слово «static»][2]
* [Готовимся к собеседованию по PHP: псевдотип «callable»][3]
[Добро пожаловать под кат!][4]
[1]: https://habrastorage.org/files/9b9/288/4f0/9b92884f0c7c49599d874f02890c19d3.jpg
[2]: https://habrahabr.ru/post/259627/
[3]: https://habrahabr.ru/post/259991/
[4]: https://habrahabr.ru/post/324934/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-27 20:30:04
Не секрет, что на собеседованиях любят задавать каверзные вопросы. Не всегда адекватные, не всегда имеющие отношение к реальности, но факт остается фактом — задают. Конечно, вопрос вопросу рознь, и иногда вопрос, на первый взгляд кажущийся вам дурацким, на самом деле направлен на проверку того, насколько хорошо вы знаете язык, на котором пишете.
И, разумеется, какими бы вам странными и некорректными ни казались вопросы на собеседовании, приходить нужно всё-таки подготовленным, зная тот язык, за программирование на котором вам собираются платить.
![image][1]
Третья часть серии статей посвящена одному из самых объемных понятий в современном PHP — итерации, итераторам и итерируемым сущностям. Я постарался свести в один текст некий минимум знаний об этом вопросе, пригодный для самоподготовки к собеседованию на позицию разработчика на PHP.
Две предыдущие части:
* [Готовимся к собеседованию по PHP: ключевое слово «static»][2]
* [Готовимся к собеседованию по PHP: псевдотип «callable»][3]
[Добро пожаловать под кат!][4]
[1]: https://habrastorage.org/files/9b9/288/4f0/9b92884f0c7c49599d874f02890c19d3.jpg
{kind=link}
[2]: https://habrahabr.ru/post/259627/
[3]: https://habrahabr.ru/post/259991/
[4]: https://habrahabr.ru/post/324934/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Threat Horizon 2017-2019 от International Security Forum (выдержка для руководителей)
habra.16
habrabot(difrex,1) — All
2017-03-28 09:30:03
Привет, коллеги,
в конце прошлой недели International Security Forum опубликовал очередной ежегодный отчёт о грядущих трендах ИТ-угроз бизнесу Threat Horizon 2019. Отчёт содержит подробные описания девяти основных угроз, а также информацию об их воздействии на бизнес и рекомендуемые действия.
Я также добавил перевод результатов прошлогоднего отчёта (2018). Представленная информация должна помочь ИТ и риск-менеджерам, а так же руководителям бизнеса ознакомиться с набирающими силу рисками и оценить возможные последствия.
По [ссылке][1] вы можете скачать выдержку из отчёта на английском. [Прошлогодняя][2], [позапрошлогодняя][3], и [более ранние][4] выдержки находятся в открытом доступе. Тем же, кто хочет ознакомиться с переводом выводов и рекомендаций из отчётов последних трёх лет — прошу под кат.
В комментариях предлагаю описать актуальность приведённых выводов и рекомендаций для вашей организации.
[Читать дальше →][5]
[1]: https://www.securityforum.org/research/threat-horizon-2on-deterioration/
[2]: https://media.scmagazine.com/documents/217/isf_threat_horizon_2018_execut_54175.pdf
[3]: https://www.securityforum.org/uploads/2015/03/Threat-Horizon_2017_Executive-Summary.pdf
[4]: https://www.securityforum.org/uploads/2015/12/isf_threat-horizon_2016_es.pdf
[5]: https://habrahabr.ru/post/324922/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-28 09:30:03
Привет, коллеги,
в конце прошлой недели International Security Forum опубликовал очередной ежегодный отчёт о грядущих трендах ИТ-угроз бизнесу Threat Horizon 2019. Отчёт содержит подробные описания девяти основных угроз, а также информацию об их воздействии на бизнес и рекомендуемые действия.
Я также добавил перевод результатов прошлогоднего отчёта (2018). Представленная информация должна помочь ИТ и риск-менеджерам, а так же руководителям бизнеса ознакомиться с набирающими силу рисками и оценить возможные последствия.
По [ссылке][1] вы можете скачать выдержку из отчёта на английском. [Прошлогодняя][2], [позапрошлогодняя][3], и [более ранние][4] выдержки находятся в открытом доступе. Тем же, кто хочет ознакомиться с переводом выводов и рекомендаций из отчётов последних трёх лет — прошу под кат.
В комментариях предлагаю описать актуальность приведённых выводов и рекомендаций для вашей организации.
[Читать дальше →][5]
[1]: https://www.securityforum.org/research/threat-horizon-2on-deterioration/
[2]: https://media.scmagazine.com/documents/217/isf_threat_horizon_2018_execut_54175.pdf
[3]: https://www.securityforum.org/uploads/2015/03/Threat-Horizon_2017_Executive-Summary.pdf
[4]: https://www.securityforum.org/uploads/2015/12/isf_threat-horizon_2016_es.pdf
[5]: https://habrahabr.ru/post/324922/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Разрабатываем видеочат между браузером и мобильным приложением
habra.16
habrabot(difrex,1) — All
2017-03-28 09:30:03
![][1]
**Империи зла** нередко получают лучи ненависти со стороны конечных пользователей. Не смотря на это, Uber частично оплачивает наши поездки, хоть и временно, а Google придал значительное ускорение технологии **WebRTC**, которая бы так и оставалась проприетарной и сильно платной софтиной для узких целей b2b, если бы не **ИЗ**.
После появления WebRTC, видеочаты стало делать проще. Появились различные API и сервисы, серверы и фреймворки. В данной статье мы подробно опишем еще один способ разработки видеочата между **веб-браузером** и нативным **Android-приложением** [Читать дальше →][2]
[1]: https://habrastorage.org/files/18b/79f/c9a/18b79fc9a8944cf8a505ba68bda5a309.png
[2]: https://habrahabr.ru/post/324914/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-28 09:30:03
![][1]
**Империи зла** нередко получают лучи ненависти со стороны конечных пользователей. Не смотря на это, Uber частично оплачивает наши поездки, хоть и временно, а Google придал значительное ускорение технологии **WebRTC**, которая бы так и оставалась проприетарной и сильно платной софтиной для узких целей b2b, если бы не **ИЗ**.
После появления WebRTC, видеочаты стало делать проще. Появились различные API и сервисы, серверы и фреймворки. В данной статье мы подробно опишем еще один способ разработки видеочата между **веб-браузером** и нативным **Android-приложением** [Читать дальше →][2]
[1]: https://habrastorage.org/files/18b/79f/c9a/18b79fc9a8944cf8a505ba68bda5a309.png
{kind=link}
[2]: https://habrahabr.ru/post/324914/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Сможет ли Питон прожевать миллион запросов в секунду?
habra.16
habrabot(difrex,1) — All
2017-03-28 10:30:04
![][1]
Возможно ли с помощью Python обработать миллион запросов в секунду? До недавнего времени это было немыслимо.
Многие компании мигрируют с Python на другие языки программирования для повышения производительности и, соответственно, экономии на стоимости вычислительных ресурсов. На самом деле в этом нет необходимости. Поставленных целей можно добиться и с помощью Python.
Python-сообщество в последнее время уделяет много внимания производительности. С помощью CPython 3.6 за счет новой реализации словарей удалось повысить скорость работы интерпретатора. А благодаря новому соглашению о вызове (calling convention) и словарному кешу CPython 3.7 должен стать еще быстрее.
Для определенного класса задач хорошо подходит PyPy с его JIT-компиляцией. Также можно использовать NumPy, в котором улучшена поддержка расширений на Си. Ожидается, что в этом году PyPy достигнет совместимости с Python 3.5.
Эти замечательные решения вдохновили меня на создание нового в той области, где Python используется очень активно: в разработке веб- и микросервисов.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/c67/9fe/c7f/c679fec7f90a497087986bebeec8a330.jpeg
[2]: https://habrahabr.ru/post/323556/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-28 10:30:04
![][1]
Возможно ли с помощью Python обработать миллион запросов в секунду? До недавнего времени это было немыслимо.
Многие компании мигрируют с Python на другие языки программирования для повышения производительности и, соответственно, экономии на стоимости вычислительных ресурсов. На самом деле в этом нет необходимости. Поставленных целей можно добиться и с помощью Python.
Python-сообщество в последнее время уделяет много внимания производительности. С помощью CPython 3.6 за счет новой реализации словарей удалось повысить скорость работы интерпретатора. А благодаря новому соглашению о вызове (calling convention) и словарному кешу CPython 3.7 должен стать еще быстрее.
Для определенного класса задач хорошо подходит PyPy с его JIT-компиляцией. Также можно использовать NumPy, в котором улучшена поддержка расширений на Си. Ожидается, что в этом году PyPy достигнет совместимости с Python 3.5.
Эти замечательные решения вдохновили меня на создание нового в той области, где Python используется очень активно: в разработке веб- и микросервисов.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/c67/9fe/c7f/c679fec7f90a497087986bebeec8a330.jpeg
{kind=link}
[2]: https://habrahabr.ru/post/323556/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Всё, что вы хотели знать о стек-трейсах и хип-дампах. Часть 1
habra.16
habrabot(difrex,1) — All
2017-03-28 11:30:04
Практика показала, что хардкорные расшифровки с наших докладов хорошо заходят, так что мы решили продолжать. Сегодня у нас в меню смесь из подходов к поиску и анализу ошибок и крэшей, приправленная щепоткой полезных инструментов, подготовленная на основе доклада Андрея Паньгина (Одноклассники) на одном из JUG'ов (это была допиленная версия его доклада с JPoint 2016). В без семи минут двухчасовом докладе Андрей подробно рассказывает о стек-трейсах и хип-дампах.
Пост получился просто огромный, так что мы разбили его на две части. Сейчас вы читаете первую часть, завтра выйдет вторая.
Сегодня я буду рассказывать про стек-трейсы и хип-дампы — тему, с одной стороны, известную каждому, с другой — позволяющую постоянно открывать что-то новое (я даже багу нашел в JVM, пока готовил эту тему).
Когда я делал тренировочный прогон этого доклада у нас в офисе, один из коллег спросил: «Все это очень интересно, но на практике это кому-нибудь вообще полезно?» После этого разговора первым слайдом в свою презентацию я добавил страницу с вопросами по теме на StackOverflow. Так что это актуально.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324932/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-28 11:30:04
Практика показала, что хардкорные расшифровки с наших докладов хорошо заходят, так что мы решили продолжать. Сегодня у нас в меню смесь из подходов к поиску и анализу ошибок и крэшей, приправленная щепоткой полезных инструментов, подготовленная на основе доклада Андрея Паньгина (Одноклассники) на одном из JUG'ов (это была допиленная версия его доклада с JPoint 2016). В без семи минут двухчасовом докладе Андрей подробно рассказывает о стек-трейсах и хип-дампах.
Пост получился просто огромный, так что мы разбили его на две части. Сейчас вы читаете первую часть, завтра выйдет вторая.
Сегодня я буду рассказывать про стек-трейсы и хип-дампы — тему, с одной стороны, известную каждому, с другой — позволяющую постоянно открывать что-то новое (я даже багу нашел в JVM, пока готовил эту тему).
Когда я делал тренировочный прогон этого доклада у нас в офисе, один из коллег спросил: «Все это очень интересно, но на практике это кому-нибудь вообще полезно?» После этого разговора первым слайдом в свою презентацию я добавил страницу с вопросами по теме на StackOverflow. Так что это актуально.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324932/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Pentestit Security Conference: анонс
habra.16
habrabot(difrex,1) — All
2017-03-28 15:00:04
![][1]
Коллеги и друзья! 15 июля 2017 в Орле состоится Pentestit Security Conference — конференция, посвященная практической информационной безопасности: тестирование на проникновение современных сетей и систем, выявление уязвимостей телекоммуникационного оборудования, обход современных защитных средств, обнаружение и противодействие атакам, криминалистический анализ и расследование инцидентов.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/af5/4fa/227/af54fa227e234f548f8fd4cff2350562.jpg
[2]: https://habrahabr.ru/post/324886/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-28 15:00:04
![][1]
Коллеги и друзья! 15 июля 2017 в Орле состоится Pentestit Security Conference — конференция, посвященная практической информационной безопасности: тестирование на проникновение современных сетей и систем, выявление уязвимостей телекоммуникационного оборудования, обход современных защитных средств, обнаружение и противодействие атакам, криминалистический анализ и расследование инцидентов.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/af5/4fa/227/af54fa227e234f548f8fd4cff2350562.jpg
{kind=link}
[2]: https://habrahabr.ru/post/324886/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Pentestit Security Conference 2017: анонс
habra.16
habrabot(difrex,1) — All
2017-03-28 16:30:04
![][1]
Коллеги и друзья! 15 июля 2017 в Орле состоится Pentestit Security Conference — конференция, посвященная практической информационной безопасности: тестирование на проникновение современных сетей и систем, выявление уязвимостей телекоммуникационного оборудования, обход современных защитных средств, обнаружение и противодействие атакам, криминалистический анализ и расследование инцидентов.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/af5/4fa/227/af54fa227e234f548f8fd4cff2350562.jpg
[2]: https://habrahabr.ru/post/324886/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-28 16:30:04
![][1]
Коллеги и друзья! 15 июля 2017 в Орле состоится Pentestit Security Conference — конференция, посвященная практической информационной безопасности: тестирование на проникновение современных сетей и систем, выявление уязвимостей телекоммуникационного оборудования, обход современных защитных средств, обнаружение и противодействие атакам, криминалистический анализ и расследование инцидентов.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/af5/4fa/227/af54fa227e234f548f8fd4cff2350562.jpg
[2]: https://habrahabr.ru/post/324886/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Как ЦРУ вызывало дождь: использование Rain Maker для сбора сведений с закрытых объектов
habra.16
habrabot(difrex,1) — All
2017-03-28 20:00:05
Нашумевшая новость об утечке архива ЦРУ чаще всего преподносилась в контексте того, что спецслужба США могла подслушать, подсмотреть, узнать о нас с телефонов, компьютеров и даже телевизоров. Предлагаем вашему вниманию информацию об одном из их проектов с необычным названием Rain Maker. Он представляет собой набор утилит, направленный на скрытый сбор информации на исследуемом объекте, не подключенном к сети Интернет. Агент получает специальную флешку с музыкой и portable VLC-плеером, подключает ее к компьютеру жертвы и спокойно работает под современные хиты. Закончив работу, передает флешку со скрытыми на ней и зашифрованными данными координатору, который отправляет ее в центр на расшифровку. Как это реализовано технически?
![][1]
\* Из [архива ЦРУ][2] к этому проекту. У агентов тоже есть юмор!
[Читать дальше →][3]
[1]: https://habrastorage.org/files/438/0c6/1d8/4380c61d81464f17ad3865f009adb7f0.gif
[2]: https://wikileaks.org/ciav7p1/cms/page_15728775.html
[3]: https://habrahabr.ru/post/324920/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-28 20:00:05
Нашумевшая новость об утечке архива ЦРУ чаще всего преподносилась в контексте того, что спецслужба США могла подслушать, подсмотреть, узнать о нас с телефонов, компьютеров и даже телевизоров. Предлагаем вашему вниманию информацию об одном из их проектов с необычным названием Rain Maker. Он представляет собой набор утилит, направленный на скрытый сбор информации на исследуемом объекте, не подключенном к сети Интернет. Агент получает специальную флешку с музыкой и portable VLC-плеером, подключает ее к компьютеру жертвы и спокойно работает под современные хиты. Закончив работу, передает флешку со скрытыми на ней и зашифрованными данными координатору, который отправляет ее в центр на расшифровку. Как это реализовано технически?
![][1]
\* Из [архива ЦРУ][2] к этому проекту. У агентов тоже есть юмор!
[Читать дальше →][3]
[1]: https://habrastorage.org/files/438/0c6/1d8/4380c61d81464f17ad3865f009adb7f0.gif
{kind=link}
[2]: https://wikileaks.org/ciav7p1/cms/page_15728775.html
[3]: https://habrahabr.ru/post/324920/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Как создать интернет вещей из «кирпичиков» LEGO на базе платформы AWS IoT
habra.16
habrabot(difrex,1) — All
2017-03-29 10:30:03
![][1]
В одном из проектов мы проверили возможности облачной платформы AWS IoT, подключив к ней несколько устройств из набора Lego для программируемых роботов Mindstorms EV3.
На старте мы исследовали несколько крупных облачных сервисов для IoT, которые дали хороший толчок развитию всей концепции интернета вещей (IoT) — Microsoft Azure IoT Suite, AWS IoT и IBM Watson IoT — но в результате остановились именно на Amazon Web Services (AWS). [Читать дальше →][2]
[1]: https://habrastorage.org/files/908/6b7/612/9086b76126fa4d50bce4d93d098ac728.jpg
[2]: https://habrahabr.ru/post/324992/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 10:30:03
![][1]
В одном из проектов мы проверили возможности облачной платформы AWS IoT, подключив к ней несколько устройств из набора Lego для программируемых роботов Mindstorms EV3.
На старте мы исследовали несколько крупных облачных сервисов для IoT, которые дали хороший толчок развитию всей концепции интернета вещей (IoT) — Microsoft Azure IoT Suite, AWS IoT и IBM Watson IoT — но в результате остановились именно на Amazon Web Services (AWS). [Читать дальше →][2]
[1]: https://habrastorage.org/files/908/6b7/612/9086b76126fa4d50bce4d93d098ac728.jpg
{kind=link}
[2]: https://habrahabr.ru/post/324992/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Как собрать статистику с веб-сайта и не набить себе шишек
habra.16
habrabot(difrex,1) — All
2017-03-29 11:30:05
![enter image description here][1]
Привет, Хабр! Меня зовут Слава Волков, и я фронтенд-разработчик в Badoo. Сегодня я хотел бы немного рассказать про сбор статистики с фронтенда.
Мы знаем, что аналитика позволяет оценить эффективность работы любого веб-сайта, улучшить его работу, а значит, повысить уровень продаж и усовершенствовать взаимодействие пользователей с сайтом. Проще говоря, аналитика – это способ контроля над процессами, происходящими на веб-сайте. В большинстве случаев для обычных сайтов достаточно установить Google Analytics или «Яндекс.Метрику» – их возможностей вполне достаточно.
Но как быть, когда стандартных средств мониторинга недостаточно? Или когда собираемая статистика должна быть интегрирована в вашу собственную систему аналитики для отображения полноценной картины происходящего между разными компонентами? В таком случае, скорее всего, вам придется разработать свою систему. А вот как лучше отправлять статистику с ваших веб-сайтов, какие проблемы могут при этом возникнуть и как их избежать, я расскажу в этой статье. Заинтересовались? Добро пожаловать под кат.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/2cd/049/bcb/2cd049bcbe5348aaa2592e1faed7ac25.png
[2]: https://habrahabr.ru/post/325062/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 11:30:05
![enter image description here][1]
Привет, Хабр! Меня зовут Слава Волков, и я фронтенд-разработчик в Badoo. Сегодня я хотел бы немного рассказать про сбор статистики с фронтенда.
Мы знаем, что аналитика позволяет оценить эффективность работы любого веб-сайта, улучшить его работу, а значит, повысить уровень продаж и усовершенствовать взаимодействие пользователей с сайтом. Проще говоря, аналитика – это способ контроля над процессами, происходящими на веб-сайте. В большинстве случаев для обычных сайтов достаточно установить Google Analytics или «Яндекс.Метрику» – их возможностей вполне достаточно.
Но как быть, когда стандартных средств мониторинга недостаточно? Или когда собираемая статистика должна быть интегрирована в вашу собственную систему аналитики для отображения полноценной картины происходящего между разными компонентами? В таком случае, скорее всего, вам придется разработать свою систему. А вот как лучше отправлять статистику с ваших веб-сайтов, какие проблемы могут при этом возникнуть и как их избежать, я расскажу в этой статье. Заинтересовались? Добро пожаловать под кат.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/2cd/049/bcb/2cd049bcbe5348aaa2592e1faed7ac25.png
{kind=link}
[2]: https://habrahabr.ru/post/325062/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Шишки, набитые за 15 лет использования акторов в C++. Часть II
habra.16
habrabot(difrex,1) — All
2017-03-29 11:30:05
Завершаем рассказ, начатый [в первой части][1]. Сегодня рассмотрим еще несколько граблей, на которые довелось наступить за годы использования [SObjectizer][2]-а в повседневной работе.
# Продолжаем перечислять грабли
## Народ хочет синхронности...
Акторы в Модели Акторов и агенты у нас в SObjectizer общаются посредством асинхронных сообщений. И в этом кроется одна из причин привлекательности Модели Акторов для некоторых типов задач. Казалось бы, асинхронность — это один из краеугольных камней, один из бонусов, поэтому пользуйся себе на здоровье и получай удовольствие.
Ан нет. На практике быстро начались просьбы сделать в SObjectizer возможность синхронного взаимодействия агентов. Очень долго я этим просьбам сопротивлялся. Но в конце-концов сдался. Пришлось добавить в SObjectizer [возможность выполнить синхронный запрос от одного агента к другому][3].
Выглядит в коде это вот так:
[Читать дальше →][4]
[1]: https://habrahabr.ru/post/324420/
[2]: https://sourceforge.net/projects/sobjectizer/
[3]: https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20In-depth%20-%20Synchronous%20Interaction/
[4]: https://habrahabr.ru/post/324978/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 11:30:05
Завершаем рассказ, начатый [в первой части][1]. Сегодня рассмотрим еще несколько граблей, на которые довелось наступить за годы использования [SObjectizer][2]-а в повседневной работе.
# Продолжаем перечислять грабли
## Народ хочет синхронности...
Акторы в Модели Акторов и агенты у нас в SObjectizer общаются посредством асинхронных сообщений. И в этом кроется одна из причин привлекательности Модели Акторов для некоторых типов задач. Казалось бы, асинхронность — это один из краеугольных камней, один из бонусов, поэтому пользуйся себе на здоровье и получай удовольствие.
Ан нет. На практике быстро начались просьбы сделать в SObjectizer возможность синхронного взаимодействия агентов. Очень долго я этим просьбам сопротивлялся. Но в конце-концов сдался. Пришлось добавить в SObjectizer [возможность выполнить синхронный запрос от одного агента к другому][3].
Выглядит в коде это вот так:
[Читать дальше →][4]
[1]: https://habrahabr.ru/post/324420/
[2]: https://sourceforge.net/projects/sobjectizer/
[3]: https://sourceforge.net/p/sobjectizer/wiki/so-5.5%20In-depth%20-%20Synchronous%20Interaction/
[4]: https://habrahabr.ru/post/324978/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Всё, что вы хотели знать о стек-трейсах и хип-дампах. Часть 2
habra.16
habrabot(difrex,1) — All
2017-03-29 12:00:05
----
[Всё, что вы хотели знать о стек-трейсах и хип-дампах. Часть 1][1]
----
Перед вами вторая часть расшифровки доклада Андрея Паньгина aka [apangin][2] из Одноклассников с одного из JUG'ов (допиленная и расширенная версия его доклада с JPoint 2016). В этот раз мы закончим разговор о стек-трейсах, а также поговорим о дампах потоков и хип-дампах.
Итак, продолжаем…
[![][3]][4]
[Читать дальше →][5]
[1]: https://habrahabr.ru/company/jugru/blog/324932/
[2]: https://habrahabr.ru/users/apangin/
[3]: https://habrastorage.org/files/775/1fd/490/7751fd49013b4479be5eb4a9a4a78431.jpg
[4]: https://habrahabr.ru/company/jugru/blog/325064/
[5]: https://habrahabr.ru/post/325064/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 12:00:05
----
[Всё, что вы хотели знать о стек-трейсах и хип-дампах. Часть 1][1]
----
Перед вами вторая часть расшифровки доклада Андрея Паньгина aka [apangin][2] из Одноклассников с одного из JUG'ов (допиленная и расширенная версия его доклада с JPoint 2016). В этот раз мы закончим разговор о стек-трейсах, а также поговорим о дампах потоков и хип-дампах.
Итак, продолжаем…
[![][3]][4]
[Читать дальше →][5]
[1]: https://habrahabr.ru/company/jugru/blog/324932/
[2]: https://habrahabr.ru/users/apangin/
[3]: https://habrastorage.org/files/775/1fd/490/7751fd49013b4479be5eb4a9a4a78431.jpg
{kind=link}
[4]: https://habrahabr.ru/company/jugru/blog/325064/
[5]: https://habrahabr.ru/post/325064/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Масштабирование Git (и кое-какая предыстория)
habra.16
habrabot(difrex,1) — All
2017-03-29 14:00:04
![][1]
Несколько лет назад Microsoft приняла решение начать долгий процесс по восстановлению системы разработки во всей компании. Мы большая компания, с множеством коллективов — у каждого собственные продукты, приоритеты, процессы и инструменты. Есть некоторые «общие» инструменты, но их много разных — и ОЧЕНЬ БОЛЬШОЕ количество разработанных внутри компании инструментов одноразового использования (под коллективами я имею в виду подразделения — тысячи инженеров).
У этого есть отрицательные стороны:
1. Множество избыточных инвестиций в коллективы, которые разрабатывают похожие инструменты.
2. Невозможность финансировать какой-либо инструментарий до «критической массы».
3. Затруднения для сотрудников в перемещении по компании из-за разных инструментов и процесса.
4. Сложность в обмене кодом между организациями.
5. Разногласия с новичками в начале работы из-за чрезмерного изобилия инструментов «только для MS».
6. И так далее...[Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/81f/87c/c85/81f87cc857bf8d856482a6a8c9499374.jpg
[2]: https://habrahabr.ru/post/325116/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 14:00:04
![][1]
Несколько лет назад Microsoft приняла решение начать долгий процесс по восстановлению системы разработки во всей компании. Мы большая компания, с множеством коллективов — у каждого собственные продукты, приоритеты, процессы и инструменты. Есть некоторые «общие» инструменты, но их много разных — и ОЧЕНЬ БОЛЬШОЕ количество разработанных внутри компании инструментов одноразового использования (под коллективами я имею в виду подразделения — тысячи инженеров).
У этого есть отрицательные стороны:
1. Множество избыточных инвестиций в коллективы, которые разрабатывают похожие инструменты.
2. Невозможность финансировать какой-либо инструментарий до «критической массы».
3. Затруднения для сотрудников в перемещении по компании из-за разных инструментов и процесса.
4. Сложность в обмене кодом между организациями.
5. Разногласия с новичками в начале работы из-за чрезмерного изобилия инструментов «только для MS».
6. И так далее...[Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/81f/87c/c85/81f87cc857bf8d856482a6a8c9499374.jpg
{kind=link}
[2]: https://habrahabr.ru/post/325116/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Основные концепции библиотеки chrono (C++)
habra.16
habrabot(difrex,1) — All
2017-03-29 14:30:04
Работа со временем как с безразмерной величиной может приводить к недоразумениям и ошибкам конвертации временных единиц измерения:
> _– Слушай, ты не помнишь, мы в sleep передаем секунды или миллисекунды?_
>
> _– Блин, оказывается у меня в часе 360 секунд, ноль пропустил._
Для избежания таких ошибок предусмотрена библиотека chrono (namespace std::chrono). Она была добавлена в C++11 и дорабатывалась в поздних стандартах. Теперь все логично:
using namespace std::chrono;
int find_answer_to_the_ultimate_question_of_life()
{
//Поиск ответа
std::this_thread::sleep_for(5s); //5 секунд
return 42;
}
std::future f = std::async(find_answer_to_the_ultimate_question_of_life);
//Ждем максимум 2.5 секунд
if (f.wait_for(2500ms) == std::future_status::ready)
std::cout << "Answer is: " << f.get() << "\n";
else
std::cout << "Can't wait anymore\n";
Библиотека реализует следующие концепции:
* интервалы времени – `duration`;
* моменты времени – `time_point`;
* таймеры – `clock`.[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324984/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 14:30:04
Работа со временем как с безразмерной величиной может приводить к недоразумениям и ошибкам конвертации временных единиц измерения:
> _– Слушай, ты не помнишь, мы в sleep передаем секунды или миллисекунды?_
>
> _– Блин, оказывается у меня в часе 360 секунд, ноль пропустил._
Для избежания таких ошибок предусмотрена библиотека chrono (namespace std::chrono). Она была добавлена в C++11 и дорабатывалась в поздних стандартах. Теперь все логично:
using namespace std::chrono;
int find_answer_to_the_ultimate_question_of_life()
{
//Поиск ответа
std::this_thread::sleep_for(5s); //5 секунд
return 42;
}
std::future f = std::async(find_answer_to_the_ultimate_question_of_life);
//Ждем максимум 2.5 секунд
if (f.wait_for(2500ms) == std::future_status::ready)
std::cout << "Answer is: " << f.get() << "\n";
else
std::cout << "Can't wait anymore\n";
Библиотека реализует следующие концепции:
* интервалы времени – `duration`;
* моменты времени – `time_point`;
* таймеры – `clock`.[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324984/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Перевод] Поиск по регулярным выражениям с помощью суффиксного массива
habra.16
habrabot(difrex,1) — All
2017-03-29 15:30:04
![image][1]
Еще в январе 2012 Расс Кокс опубликовал [замечательный блог-пост][2], объясняющий работу Google Code Search с помощью триграммного индекса.
К этому времени уже вышли первые версии моей собственной системы поиска по исходному коду под названием [livegrep][3], с другим метод индексации; я писал эту систему независимо от Google, с помощью нескольких друзей. В этой статье я хотел бы представить немного запоздалое объяснение механизма ее работы.
[Читать дальше →][4]
[1]: https://habrastorage.org/getpro/habr/post_images/f49/bb2/620/f49bb262046eed26721865e934005e06.png
[2]: http://swtch.com/~rsc/regexp/regexp4.html
[3]: http://livegrep.com/
[4]: https://habrahabr.ru/post/325036/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 15:30:04
![image][1]
Еще в январе 2012 Расс Кокс опубликовал [замечательный блог-пост][2], объясняющий работу Google Code Search с помощью триграммного индекса.
К этому времени уже вышли первые версии моей собственной системы поиска по исходному коду под названием [livegrep][3], с другим метод индексации; я писал эту систему независимо от Google, с помощью нескольких друзей. В этой статье я хотел бы представить немного запоздалое объяснение механизма ее работы.
[Читать дальше →][4]
[1]: https://habrastorage.org/getpro/habr/post_images/f49/bb2/620/f49bb262046eed26721865e934005e06.png
{kind=link}
[2]: http://swtch.com/~rsc/regexp/regexp4.html
[3]: http://livegrep.com/
[4]: https://habrahabr.ru/post/325036/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
[Из песочницы] Сервер терминалов для 1С по протоколу RDP на linux: рекомендации по настройке с учетом опыта реальной эксплуатации
habra.16
habrabot(difrex,1) — All
2017-03-29 16:00:03
В статье рассматриваются нюансы установки и настройки терминального сервера по протоколу RDP для работы с базами 1с на платформе 8.3 на базе дистрибутива Xubuntu 14.04 с учетом возможностей последней версии сервера xrdp и опыта реальной эксплуатации.
Не так давно (в конце декабре 2016 года) вышел в свет очередной релиз сервера xrdp версии 0.9.1. Одновременно с этим была [выпущена][1] стабильная версия одного из «бекендов» xrdp — xorgxrdp v 0.2.0. Эти версии мы и будем использовать далее при установке.
[Читать дальше →][2]
[1]: https://github.com/neutrinolabs/xorgxrdp/releases
[2]: https://habrahabr.ru/post/325132/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 16:00:03
В статье рассматриваются нюансы установки и настройки терминального сервера по протоколу RDP для работы с базами 1с на платформе 8.3 на базе дистрибутива Xubuntu 14.04 с учетом возможностей последней версии сервера xrdp и опыта реальной эксплуатации.
Не так давно (в конце декабре 2016 года) вышел в свет очередной релиз сервера xrdp версии 0.9.1. Одновременно с этим была [выпущена][1] стабильная версия одного из «бекендов» xrdp — xorgxrdp v 0.2.0. Эти версии мы и будем использовать далее при установке.
[Читать дальше →][2]
[1]: https://github.com/neutrinolabs/xorgxrdp/releases
[2]: https://habrahabr.ru/post/325132/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
МИФИ организует олимпиаду по информационной безопасности для студентов
habra.16
habrabot(difrex,1) — All
2017-03-29 17:30:04
![][1]
Совсем скоро, 21-23 апреля 2017 года, состоится всероссийская студенческая олимпиада по информационной безопасности. Соревнование проходит на базе Национального исследовательского ядерного университета «МИФИ» при участии Positive Technologies. Принять участие в олимпиаде могут студенты в возрасте 18 до 25 лет. [Читать дальше →][2]
[1]: https://habrastorage.org/files/6fb/419/306/6fb419306bd543bd8bad4000b574c437.jpg
[2]: https://habrahabr.ru/post/325078/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 17:30:04
![][1]
Совсем скоро, 21-23 апреля 2017 года, состоится всероссийская студенческая олимпиада по информационной безопасности. Соревнование проходит на базе Национального исследовательского ядерного университета «МИФИ» при участии Positive Technologies. Принять участие в олимпиаде могут студенты в возрасте 18 до 25 лет. [Читать дальше →][2]
[1]: https://habrastorage.org/files/6fb/419/306/6fb419306bd543bd8bad4000b574c437.jpg
{kind=link}
[2]: https://habrahabr.ru/post/325078/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Техническая программа PHDays: чего ждать от трояна HummingBad, каким бывает вредоносное ПО для macOS и атаки на Java Car
habra.16
habrabot(difrex,1) — All
2017-03-29 17:30:04
[![image][1]][2]
Positive Hack Days неумолимо приближается: более 4000 экспертов по практической безопасности соберутся в Москве 23 и 24 мая 2017 года, чтобы обсудить самые острые вопросы информационной безопасности. Совсем недавно мы [анонсировали первую группу докладчиков][3], попавших в основную техническую программу. Если вы хотите выступить на одной трибуне вместе с именитыми экспертами по безопасности, у вас остался последний шанс — мы продлеваем Call For Papers до 30 марта. А пока вы готовите [заявки на участие][4], мы представляем новую порцию выступлений. [Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/8cf/fe7/b6d/8cffe7b6d168eaf0d5c5a42de184d7ed.jpg
[2]: https://habrahabr.ru/company/pt/blog/325144/
[3]: https://www.phdays.ru/press/news/187276/
[4]: http://cfp.phdays.com/en/phd7/cfp/session/new
[5]: https://habrahabr.ru/post/325144/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 17:30:04
[![image][1]][2]
Positive Hack Days неумолимо приближается: более 4000 экспертов по практической безопасности соберутся в Москве 23 и 24 мая 2017 года, чтобы обсудить самые острые вопросы информационной безопасности. Совсем недавно мы [анонсировали первую группу докладчиков][3], попавших в основную техническую программу. Если вы хотите выступить на одной трибуне вместе с именитыми экспертами по безопасности, у вас остался последний шанс — мы продлеваем Call For Papers до 30 марта. А пока вы готовите [заявки на участие][4], мы представляем новую порцию выступлений. [Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/8cf/fe7/b6d/8cffe7b6d168eaf0d5c5a42de184d7ed.jpg
{kind=link}
[2]: https://habrahabr.ru/company/pt/blog/325144/
[3]: https://www.phdays.ru/press/news/187276/
[4]: http://cfp.phdays.com/en/phd7/cfp/session/new
[5]: https://habrahabr.ru/post/325144/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Запускаем VMWare ESXi 6.5 под гипервизором QEMU
habra.16
habrabot(difrex,1) — All
2017-03-29 18:30:04
![][1]
На свете существует замечательный гипервизор ESXi от компании VMWare, и все в нем хорошо, но вот требования к “железу”, на котором он может работать, весьма нескромные. ESXi принципиально не поддерживает программные RAID’ы, 100-мегабитные и дешевые гигабитные сетевые карты, поэтому попробовать, каков он в работе, можно только закупившись соответствующим оборудованием.
Однако ESXi самые “вкусные” возможности ESXi открываются тогда, когда у нас есть не один, а несколько хостов ESXi — это кластеризация, живая миграция, распределенное хранилище VSAN, распределенный сетевой коммутатор и т.п. В этом случае затраты на тестовое оборудование уже могут составить приличную сумму. К счастью, ESXi поддерживает Nested Virtualization — то есть способность запускаться из-под уже работающего гипервизора. При этом и внешний гипервизор понимает, что его гостю нужен доступ к аппаратной виртуализации, и ESXi знает, что работает не на голом железе. Как правило, в качестве основного гипервизора также используется ESXi — такая конфигурация поддерживается VMWare уже довольно давно. Мы же попробуем запустить ESXi, использую гипервизор QEMU. В сети есть инструкции и на этот счет, но, как мы увидим ниже, они слегка устарели.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/aa8/cf0/947/aa8cf094742d49198edcbd6e74c8dda5.png
[2]: https://habrahabr.ru/post/325090/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-29 18:30:04
![][1]
На свете существует замечательный гипервизор ESXi от компании VMWare, и все в нем хорошо, но вот требования к “железу”, на котором он может работать, весьма нескромные. ESXi принципиально не поддерживает программные RAID’ы, 100-мегабитные и дешевые гигабитные сетевые карты, поэтому попробовать, каков он в работе, можно только закупившись соответствующим оборудованием.
Однако ESXi самые “вкусные” возможности ESXi открываются тогда, когда у нас есть не один, а несколько хостов ESXi — это кластеризация, живая миграция, распределенное хранилище VSAN, распределенный сетевой коммутатор и т.п. В этом случае затраты на тестовое оборудование уже могут составить приличную сумму. К счастью, ESXi поддерживает Nested Virtualization — то есть способность запускаться из-под уже работающего гипервизора. При этом и внешний гипервизор понимает, что его гостю нужен доступ к аппаратной виртуализации, и ESXi знает, что работает не на голом железе. Как правило, в качестве основного гипервизора также используется ESXi — такая конфигурация поддерживается VMWare уже довольно давно. Мы же попробуем запустить ESXi, использую гипервизор QEMU. В сети есть инструкции и на этот счет, но, как мы увидим ниже, они слегка устарели.
[Читать дальше →][2]
[1]: https://habrastorage.org/files/aa8/cf0/947/aa8cf094742d49198edcbd6e74c8dda5.png
{kind=link}
[2]: https://habrahabr.ru/post/325090/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Запускаем простой блог на Wagtail CMS (Django) — часть 3, заключительная
habra.16
habrabot(difrex,1) — All
2017-03-30 07:00:04
Третью часть про Wagtail CMS я решил посветить тем моментам, которые помогли мне снова полюбить Django. Благодаря большому сообществу, которое развивает эту CMS, любой найдет в ней что-то для себя.
В заключительной части будут затронуты следующие моменты:
* StreamField
* API + React
* Разработка для e-commerce
![image][1]
[Читать дальше →][2]
[1]: https://habrastorage.org/files/2a5/d59/240/2a5d592409df4b8e93bb180e254629b1.png
[2]: https://habrahabr.ru/post/325110/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-30 07:00:04
Третью часть про Wagtail CMS я решил посветить тем моментам, которые помогли мне снова полюбить Django. Благодаря большому сообществу, которое развивает эту CMS, любой найдет в ней что-то для себя.
В заключительной части будут затронуты следующие моменты:
* StreamField
* API + React
* Разработка для e-commerce
![image][1]
[Читать дальше →][2]
[1]: https://habrastorage.org/files/2a5/d59/240/2a5d592409df4b8e93bb180e254629b1.png
{kind=link}
[2]: https://habrahabr.ru/post/325110/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Неудобно редактировать ERb/EEx шаблоны? Попробуйте Slim/Slime
habra.16
habrabot(difrex,1) — All
2017-03-30 07:00:04
ERb — стандартный язык разметки в мире Ruby. Это html со вставками на Ruby. В мире Elixir ту же роль выполняет EEx. Такой же синтаксис, только вместо Ruby — Elixir. Вот как это выглядит:
Дополнительный текст.
**То же самое можно написать в 1.5 раза короче без потери читаемости.**
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324332/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-30 07:00:04
ERb — стандартный язык разметки в мире Ruby. Это html со вставками на Ruby. В мире Elixir ту же роль выполняет EEx. Такой же синтаксис, только вместо Ruby — Elixir. Вот как это выглядит:
Дополнительный текст.
**То же самое можно написать в 1.5 раза короче без потери читаемости.**
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/324332/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Техническая программа PHDays: разбор трояна HummingBad, каким бывает вредоносное ПО для macOS и атаки на Java Card
habra.16
habrabot(difrex,1) — All
2017-03-30 07:00:04
[![image][1]][2]
Positive Hack Days неумолимо приближается: более 4000 экспертов по практической безопасности соберутся в Москве 23 и 24 мая 2017 года, чтобы обсудить самые острые вопросы информационной безопасности. Совсем недавно мы [анонсировали первую группу докладчиков][3], попавших в основную техническую программу. Если вы хотите выступить на одной трибуне вместе с именитыми экспертами по безопасности, у вас остался последний шанс — мы продлеваем Call For Papers до 30 марта. А пока вы готовите [заявки на участие][4], мы представляем новую порцию выступлений. [Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/8cf/fe7/b6d/8cffe7b6d168eaf0d5c5a42de184d7ed.jpg
[2]: https://habrahabr.ru/company/pt/blog/325144/
[3]: https://www.phdays.ru/press/news/187276/
[4]: http://cfp.phdays.com/en/phd7/cfp/session/new
[5]: https://habrahabr.ru/post/325144/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-30 07:00:04
[![image][1]][2]
Positive Hack Days неумолимо приближается: более 4000 экспертов по практической безопасности соберутся в Москве 23 и 24 мая 2017 года, чтобы обсудить самые острые вопросы информационной безопасности. Совсем недавно мы [анонсировали первую группу докладчиков][3], попавших в основную техническую программу. Если вы хотите выступить на одной трибуне вместе с именитыми экспертами по безопасности, у вас остался последний шанс — мы продлеваем Call For Papers до 30 марта. А пока вы готовите [заявки на участие][4], мы представляем новую порцию выступлений. [Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/8cf/fe7/b6d/8cffe7b6d168eaf0d5c5a42de184d7ed.jpg
[2]: https://habrahabr.ru/company/pt/blog/325144/
[3]: https://www.phdays.ru/press/news/187276/
[4]: http://cfp.phdays.com/en/phd7/cfp/session/new
[5]: https://habrahabr.ru/post/325144/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
[>]
Как хакеры атакуют корпоративный WiFi: разбор атаки
habra.16
habrabot(difrex,1) — All
2017-03-30 08:00:03
[![][1]][2]
Изображение: [Manuel Iglesias][3], Flickr
Беспроводные сети являются неотъемлемой частью корпоративной инфраструктуры большинства современных компаний. Использование WiFi позволяет разворачивать сети без прокладки кабеля, а также обеспечивает сотрудников мобильностью – подключение возможно из любой точки офиса с целого ряда устройств. Определенное значение имеет и удобство клиентов компании, которым, например, необходимо использование высокоскоростного доступа в Интернет. Развернутая беспроводная сеть позволяет сделать это быстро и комфортно.
Однако небезопасное использование или администрирование беспроводных сетей внутри организации влечет за собой серьезные угрозы. В случае успешной реализации подобных атак на корпоративный Wi-Fi злоумышленники имеют возможность перехватывать чувствительные данные, атаковать пользователей беспроводной сети, а также получить доступ к внутренним ресурсам компании. [Читать дальше →][4]
[1]: https://habrastorage.org/files/b49/747/65e/b4974765eff74f0eb01bbf9c18ca4ecd.jpg
[2]: https://habrahabr.ru/company/pt/blog/325226/
[3]: https://www.flickr.com/photos/michperu/
[4]: https://habrahabr.ru/post/325226/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut
habra.16
habrabot(difrex,1) — All
2017-03-30 08:00:03
[![][1]][2]
Изображение: [Manuel Iglesias][3], Flickr
Беспроводные сети являются неотъемлемой частью корпоративной инфраструктуры большинства современных компаний. Использование WiFi позволяет разворачивать сети без прокладки кабеля, а также обеспечивает сотрудников мобильностью – подключение возможно из любой точки офиса с целого ряда устройств. Определенное значение имеет и удобство клиентов компании, которым, например, необходимо использование высокоскоростного доступа в Интернет. Развернутая беспроводная сеть позволяет сделать это быстро и комфортно.
Однако небезопасное использование или администрирование беспроводных сетей внутри организации влечет за собой серьезные угрозы. В случае успешной реализации подобных атак на корпоративный Wi-Fi злоумышленники имеют возможность перехватывать чувствительные данные, атаковать пользователей беспроводной сети, а также получить доступ к внутренним ресурсам компании. [Читать дальше →][4]
[1]: https://habrastorage.org/files/b49/747/65e/b4974765eff74f0eb01bbf9c18ca4ecd.jpg
{kind=link}
[2]: https://habrahabr.ru/company/pt/blog/325226/
[3]: https://www.flickr.com/photos/michperu/
[4]: https://habrahabr.ru/post/325226/?utm_source=habrahabr&utm_medium=rss&utm_campaign=feed_posts#habracut