|
|
Login |
[>]
[ScanDoc] предобработка сканов
habra.16
habrabot(difrex,1) — All
2016-02-29 13:30:03
Есть мнение, что система электронного документооборота полностью избавляет от работы с бумагами, но это не так. Для оцифровки бумажных экземпляров документов их обычно пропускают через сканер. Когда поток документов и требования к качеству сканов превышают некоторый порог возникает ряд вопросов, которые необходимо решать программно. Какие проблемы приходится решать:
* Корректировать угол наклона изображения, т.к. фидер сканера неизбежно наклоняет документ при протяжке. Неряшливость в важных документах недопустима.
* Выделять полезную часть на скане, остальное — удалять, так как это не информативно и занимает дисковое пространство впустую.
* Находить и удалять пустые страницы, которые обязательно будут при дуплекс-сканировании.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/278073/#habracut
habra.16
habrabot(difrex,1) — All
2016-02-29 13:30:03
Есть мнение, что система электронного документооборота полностью избавляет от работы с бумагами, но это не так. Для оцифровки бумажных экземпляров документов их обычно пропускают через сканер. Когда поток документов и требования к качеству сканов превышают некоторый порог возникает ряд вопросов, которые необходимо решать программно. Какие проблемы приходится решать:
* Корректировать угол наклона изображения, т.к. фидер сканера неизбежно наклоняет документ при протяжке. Неряшливость в важных документах недопустима.
* Выделять полезную часть на скане, остальное — удалять, так как это не информативно и занимает дисковое пространство впустую.
* Находить и удалять пустые страницы, которые обязательно будут при дуплекс-сканировании.
[Читать дальше →][1]
[1]: https://habrahabr.ru/post/278073/#habracut
[>]
История бесконечного города. На Three.js
habra.16
habrabot(difrex,1) — All
2016-02-29 14:30:03
WebGL — одна из самых интересных новых технологий, которая способна удивительным образом преобразовать интернет. На базе этой технологии уже создано несколько движков, которые позволяют без лишних усилий создавать удивительные вещи, и наиболее известный из них Three.js. Познакомится с ним было моим давним желанием, и лучший способ сделать это — создать что-нибудь интересное. Первой идей было набросать “воодушевляющую” сцену на Three.js содержащую как большое количество полигонов, источников освещения и частиц, так и имеющую, при этом, какой-то осмысленный контекст. Вскоре, эта идея превратилась в желание создать бесконечный город в который можно было бы погрузиться сквозь браузер. Стоит сказать, что статья просвещена не всему построению целиком, а лишь решению наиболее интересных проблем, с которыми пришлось столкнуться по мере создания сцены. ![image][1] [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/2c3/ba8/547/2c3ba85478b6b255f45dad1233d98bf9.png
[2]: https://habrahabr.ru/post/278043/#habracut
habra.16
habrabot(difrex,1) — All
2016-02-29 14:30:03
WebGL — одна из самых интересных новых технологий, которая способна удивительным образом преобразовать интернет. На базе этой технологии уже создано несколько движков, которые позволяют без лишних усилий создавать удивительные вещи, и наиболее известный из них Three.js. Познакомится с ним было моим давним желанием, и лучший способ сделать это — создать что-нибудь интересное. Первой идей было набросать “воодушевляющую” сцену на Three.js содержащую как большое количество полигонов, источников освещения и частиц, так и имеющую, при этом, какой-то осмысленный контекст. Вскоре, эта идея превратилась в желание создать бесконечный город в который можно было бы погрузиться сквозь браузер. Стоит сказать, что статья просвещена не всему построению целиком, а лишь решению наиболее интересных проблем, с которыми пришлось столкнуться по мере создания сцены. ![image][1] [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/2c3/ba8/547/2c3ba85478b6b255f45dad1233d98bf9.png
{kind=link}
[2]: https://habrahabr.ru/post/278043/#habracut
[>]
Лучшие инструменты для JavaScript-разработчика
habra.16
habrabot(difrex,1) — All
2016-02-29 15:00:03
![][1] Регулярно появляется какая-нибудь JS-библиотека, которую начинают шумно обсуждать на всевозможных форумах. Сначала постепенно нарастает энтузиазм, а затем сообщество быстро делится на противоборствующие лагери, по-разному относящиеся к новинке. Было бы просто невероятным подвигом рассмотреть все распространённые JS-фреймворки и библиотеки, поэтому хотим предложить вам список самых популярных и оказавших наибольшее влияние инструментов для фронтенд-разработки. А заодно дадим некоторые рекомендации по их использованию. Но прежде чем перейти к делу, хотим уточнить:
* Не нужно ломать копий, если в этот список не попали какие-то из ваших любимых фреймворков или библиотек.
* Следите за обновлениями используемых вами инструментов. В последнее время начала активно внедряться кроссбраузерная и кроссаппаратная (cross-device) поддержка. Например, можно воспользоваться [сканером][2], который подскажет, совместимы ли более старые версии с большинством устройств.
[Читать дальше →][3]
[1]: https://habrastorage.org/files/14b/fa8/ae2/14bfa8ae2ca34d9ba92c6c3464381641.jpg
[2]: https://dev.windows.com/en-us/microsoft-edge/tools/staticscan/
[3]: https://habrahabr.ru/post/277869/#habracut
habra.16
habrabot(difrex,1) — All
2016-02-29 15:00:03
![][1] Регулярно появляется какая-нибудь JS-библиотека, которую начинают шумно обсуждать на всевозможных форумах. Сначала постепенно нарастает энтузиазм, а затем сообщество быстро делится на противоборствующие лагери, по-разному относящиеся к новинке. Было бы просто невероятным подвигом рассмотреть все распространённые JS-фреймворки и библиотеки, поэтому хотим предложить вам список самых популярных и оказавших наибольшее влияние инструментов для фронтенд-разработки. А заодно дадим некоторые рекомендации по их использованию. Но прежде чем перейти к делу, хотим уточнить:
* Не нужно ломать копий, если в этот список не попали какие-то из ваших любимых фреймворков или библиотек.
* Следите за обновлениями используемых вами инструментов. В последнее время начала активно внедряться кроссбраузерная и кроссаппаратная (cross-device) поддержка. Например, можно воспользоваться [сканером][2], который подскажет, совместимы ли более старые версии с большинством устройств.
[Читать дальше →][3]
[1]: https://habrastorage.org/files/14b/fa8/ae2/14bfa8ae2ca34d9ba92c6c3464381641.jpg
{kind=link}
[2]: https://dev.windows.com/en-us/microsoft-edge/tools/staticscan/
[3]: https://habrahabr.ru/post/277869/#habracut
[>]
Вариант развёртывания Linux систем на базе Puppet 4. Часть III: установка Puppet Server (cfpuppetserver)
habra.16
habrabot(difrex,1) — All
2016-02-29 16:00:04
# Вкратце:
> 1. **[cfpuppetserver][1]** — модуль автоматической настройки Puppet Server + PuppetDB + PostgreSQL + r10k + librarian-puppet
> 2. Краткое введение в Puppet
> 3. Описывается изначальное развёртывание с нуля
>
>
[Читать дальше →][2]
[1]: https://forge.puppetlabs.com/codingfuture/cfpuppetserver
[2]: https://habrahabr.ru/post/278163/#habracut
habra.16
habrabot(difrex,1) — All
2016-02-29 16:00:04
# Вкратце:
> 1. **[cfpuppetserver][1]** — модуль автоматической настройки Puppet Server + PuppetDB + PostgreSQL + r10k + librarian-puppet
> 2. Краткое введение в Puppet
> 3. Описывается изначальное развёртывание с нуля
>
>
[Читать дальше →][2]
[1]: https://forge.puppetlabs.com/codingfuture/cfpuppetserver
[2]: https://habrahabr.ru/post/278163/#habracut
[>]
[Из песочницы] CMake — создание динамических библиотек
habra.16
habrabot(difrex,1) — All
2016-02-29 20:00:07
#### Введение
[CMake ][1](от англ. cross platform make) — это кроссплатформенная система автоматизации сборки программного обеспечения из исходного кода. CMake не занимается непосредственно сборкой, a лишь генерирует файлы управления сборкой из файлов CMakeLists.txt.
#### Динамические библиотеки. Теория
Создание динамических библиотек со статической линковкой в ОС Windows отличается от ОС Linux. На ОС Windows для этого требуется связка .dll (dynamic link library) + .lib (library) файлов. На ОС Linux для этого нужен всего лишь один .so (shared object) файл. [Читать дальше →][2]
[1]: https://cmake.org/
[2]: https://habrahabr.ru/post/278207/#habracut
habra.16
habrabot(difrex,1) — All
2016-02-29 20:00:07
#### Введение
[CMake ][1](от англ. cross platform make) — это кроссплатформенная система автоматизации сборки программного обеспечения из исходного кода. CMake не занимается непосредственно сборкой, a лишь генерирует файлы управления сборкой из файлов CMakeLists.txt.
#### Динамические библиотеки. Теория
Создание динамических библиотек со статической линковкой в ОС Windows отличается от ОС Linux. На ОС Windows для этого требуется связка .dll (dynamic link library) + .lib (library) файлов. На ОС Linux для этого нужен всего лишь один .so (shared object) файл. [Читать дальше →][2]
[1]: https://cmake.org/
[2]: https://habrahabr.ru/post/278207/#habracut
[>]
0 марта. Сеймур Пейперт и обучение программированию через тело (и бессознательное)
habra.16
habrabot(difrex,1) — All
2016-02-29 23:00:03
Привет, Хабр! Вместе с компанией [Edison][1] стартуем весенний марафон публикаций. Я постараюсь докопаться до первоисточников IT-технологий, разобраться, как мыслили и какие концепции были в головах у первопроходцев, о чем они мечтали, каким видели мир будущего. Для чего задумывались «компьютер», «сеть», «гипертекст», «усилители интеллекта», «система коллективного решения задач», какой смысл они вкладывали в эти понятия, какими инструментами хотели добиться результата. Надеюсь, что эти материалы послужат вдохновением для тех, кто задается вопросом, как перейти [«от Нуля к Единице»][2] (создать что-то, чего раньше и в помине не было). Хочется, чтобы IT и «программирование» перестали быть просто «кодингом ради бабла», и напомнить, что они задумывались как рычаг, чтобы изменить образование, способ совместной деятельности, мышления и коммуникации, как попытка решить мировые проблемы и ответить на вызовы, вставшие перед человечеством. Как-то так.
----
Сегодня справляет свой 22 день рождения человек, который родился в 1928 году (88 астрономических лет). [Сеймур Пейперт][3] — выдающийся математик, программист, психолог и педагог. Один из основоположников теории искусственного интеллекта, создатель языка Logo. ![][4] У меня есть правило. Если о что-нибудь дает о себе знать из трех независимых авторитетных для меня источников, то на это стоит обратить пристальное внимание. Первый раз про [Сеймура Пейперта][5] я услышал год назад в хакспейсе от [shamrin][6], он читал его книгу на английском и меня заинтересовали его мысли про жонглирование и программирование, а так же как в мозгу детей образуются базовые логические концепты. Чуть позже я пришел в гости к [FISCHERTECHNIK][7], и разглядел у них на полке эту книгу, выпросил ее почитать на месяцок. Читал взахлеб и понял, что обязан себе купить такую же. Пол года назад я присутствовал на [выступлении Дэвида Яна][8], где он, отвечая на вопрос из зала, есть ли у [его школы][9] спонсоры не из Армении, упомянул Сеймура Пейперта (похоже, только Ян и я в зале знали, кто это такой). Сегодня самое время написать об авторе, о книге и о сильных идеях. А так же объяснить, при чем тут жонглирование, ходули и слэклайн. _(а если вы программировали на LOGO, тогда вам обязательно под кат)_ [Читать дальше →][10]
[1]: http://www.edsd.ru/
[2]: https://megamozg.ru/post/2408/
[3]: https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D0%B9%D0%BF%D0%B5%D1%80%D1%82,_%D0%A1%D0%B5%D0%B9%D0%BC%D1%83%D1%80
[4]: https://habrastorage.org/files/df7/642/f9f/df7642f9f72c41ccb4014237a49b3fed.jpg
[5]: https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D0%B9%D0%BF%D0%B5%D1%80%D1%82,_%D0%A1%D0%B5%D0%B9%D0%BC%D1%83%D1%80
[6]: https://habrahabr.ru/users/shamrin/
[7]: http://habrahabr.ru/company/neuronspace/blog/243929/
[8]: http://www.youtube.com/watch?v=IvrW9lsjByE
[9]: http://www.rb.ru/article/top-menedjer-abbyy-ostavlyaet-svoy-post-chtoby-vozglavit-shkolu-v-armenii/7345497.html
[10]: https://habrahabr.ru/post/277799/#habracut
habra.16
habrabot(difrex,1) — All
2016-02-29 23:00:03
Привет, Хабр! Вместе с компанией [Edison][1] стартуем весенний марафон публикаций. Я постараюсь докопаться до первоисточников IT-технологий, разобраться, как мыслили и какие концепции были в головах у первопроходцев, о чем они мечтали, каким видели мир будущего. Для чего задумывались «компьютер», «сеть», «гипертекст», «усилители интеллекта», «система коллективного решения задач», какой смысл они вкладывали в эти понятия, какими инструментами хотели добиться результата. Надеюсь, что эти материалы послужат вдохновением для тех, кто задается вопросом, как перейти [«от Нуля к Единице»][2] (создать что-то, чего раньше и в помине не было). Хочется, чтобы IT и «программирование» перестали быть просто «кодингом ради бабла», и напомнить, что они задумывались как рычаг, чтобы изменить образование, способ совместной деятельности, мышления и коммуникации, как попытка решить мировые проблемы и ответить на вызовы, вставшие перед человечеством. Как-то так.
----
Сегодня справляет свой 22 день рождения человек, который родился в 1928 году (88 астрономических лет). [Сеймур Пейперт][3] — выдающийся математик, программист, психолог и педагог. Один из основоположников теории искусственного интеллекта, создатель языка Logo. ![][4] У меня есть правило. Если о что-нибудь дает о себе знать из трех независимых авторитетных для меня источников, то на это стоит обратить пристальное внимание. Первый раз про [Сеймура Пейперта][5] я услышал год назад в хакспейсе от [shamrin][6], он читал его книгу на английском и меня заинтересовали его мысли про жонглирование и программирование, а так же как в мозгу детей образуются базовые логические концепты. Чуть позже я пришел в гости к [FISCHERTECHNIK][7], и разглядел у них на полке эту книгу, выпросил ее почитать на месяцок. Читал взахлеб и понял, что обязан себе купить такую же. Пол года назад я присутствовал на [выступлении Дэвида Яна][8], где он, отвечая на вопрос из зала, есть ли у [его школы][9] спонсоры не из Армении, упомянул Сеймура Пейперта (похоже, только Ян и я в зале знали, кто это такой). Сегодня самое время написать об авторе, о книге и о сильных идеях. А так же объяснить, при чем тут жонглирование, ходули и слэклайн. _(а если вы программировали на LOGO, тогда вам обязательно под кат)_ [Читать дальше →][10]
[1]: http://www.edsd.ru/
[2]: https://megamozg.ru/post/2408/
[3]: https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D0%B9%D0%BF%D0%B5%D1%80%D1%82,_%D0%A1%D0%B5%D0%B9%D0%BC%D1%83%D1%80
[4]: https://habrastorage.org/files/df7/642/f9f/df7642f9f72c41ccb4014237a49b3fed.jpg
{kind=link}
[5]: https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D0%B9%D0%BF%D0%B5%D1%80%D1%82,_%D0%A1%D0%B5%D0%B9%D0%BC%D1%83%D1%80
[6]: https://habrahabr.ru/users/shamrin/
[7]: http://habrahabr.ru/company/neuronspace/blog/243929/
[8]: http://www.youtube.com/watch?v=IvrW9lsjByE
[9]: http://www.rb.ru/article/top-menedjer-abbyy-ostavlyaet-svoy-post-chtoby-vozglavit-shkolu-v-armenii/7345497.html
[10]: https://habrahabr.ru/post/277799/#habracut
[>]
RISC'овый Debian под QEMU
habra.16
habrabot(difrex,1) — All
2016-03-01 02:00:03
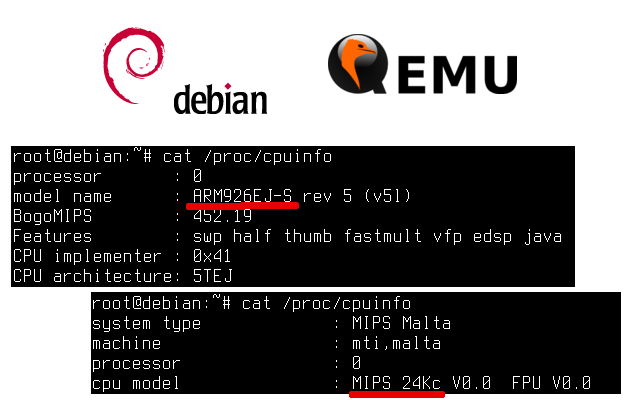
![][1] Для встраиваемых систем на базе процессоров с архитектурами MIPS и ARM нередко используются специализированные генераторы дистрибутивов ОС GNU/Linux: buildroot, openwrt и прочие Yocto. Но иногда интересно запустить на такой системе универсальную ОС Debian. Установить Debian на ЭВМ с процессором архитектуры x86/amd64 — дело несложное, а вот со встраиваемыми системами, _поверьте, у нас не всё так однозначно..._ В данной публикации я расскажу как можно при помощи debootstrap установить, а затем как при помощи QEMU запустить ОС Debian для ЭВМ с процессорами MIPS и ARM. [Читать дальше →][2]
[1]: https://habrastorage.org/files/4de/acf/fff/4deacfffff854b80b56b11d567bf4e91.png
[2]: https://habrahabr.ru/post/278159/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 02:00:03
![][1] Для встраиваемых систем на базе процессоров с архитектурами MIPS и ARM нередко используются специализированные генераторы дистрибутивов ОС GNU/Linux: buildroot, openwrt и прочие Yocto. Но иногда интересно запустить на такой системе универсальную ОС Debian. Установить Debian на ЭВМ с процессором архитектуры x86/amd64 — дело несложное, а вот со встраиваемыми системами, _поверьте, у нас не всё так однозначно..._ В данной публикации я расскажу как можно при помощи debootstrap установить, а затем как при помощи QEMU запустить ОС Debian для ЭВМ с процессорами MIPS и ARM. [Читать дальше →][2]
[1]: https://habrastorage.org/files/4de/acf/fff/4deacfffff854b80b56b11d567bf4e91.png
{kind=link}
[2]: https://habrahabr.ru/post/278159/#habracut
[>]
ORegex: От символов к объектам
habra.16
habrabot(difrex,1) — All
2016-03-01 08:30:03
Добрый вечер, хаброжители! Сегодня я хочу поделиться с вами таким еще молодым проектом, как ORegex или Object Regular Expressions. Я уже довольно долго работаю в компьютерной лингвистике и хоть я не лингвист, но все же вижу в языках какие-то устоявшиеся конструкции, шаблоны. Для тех кому интересно, как я решил их выделять — под кат. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278219/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 08:30:03
Добрый вечер, хаброжители! Сегодня я хочу поделиться с вами таким еще молодым проектом, как ORegex или Object Regular Expressions. Я уже довольно долго работаю в компьютерной лингвистике и хоть я не лингвист, но все же вижу в языках какие-то устоявшиеся конструкции, шаблоны. Для тех кому интересно, как я решил их выделять — под кат. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278219/#habracut
[>]
Хакер опубликовал данные SIM-карт и счетов 3 млн абонентов крупного африканского оператора
habra.16
habrabot(difrex,1) — All
2016-03-01 10:00:03
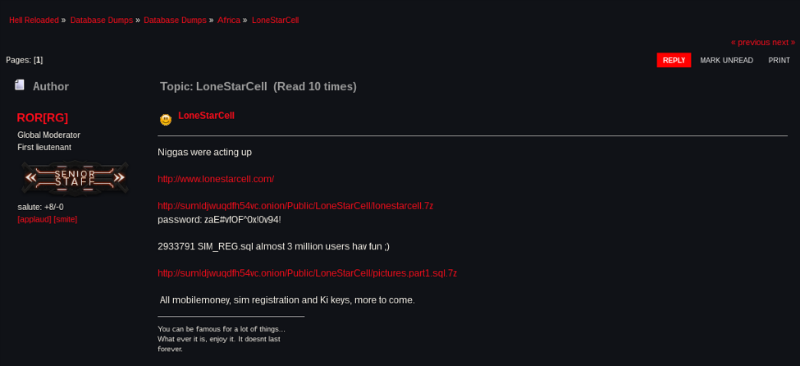
![][1] В сети Tor опубликована ссылка на [архив][2], содержащий регистрационные данные и финансовую информацию 3 млн абонентов крупнейшего телекоммуникационного оператора Либерии Lonestar Cell. Хакер под ником ROR[RG] [выложил][3] на одном из форумов ссылку и пароль для доступа к архиву — по его словам с помощью этих данных можно получить доступ к мобильным счетам пользователей оператора, а также их индивидуальные ключи идентификации и учетные данные сим-карт. ROR[RG] уточнил, что архив содержит не всю информацию, которую ему удалось похитить из сети оператора. [Читать дальше →][4]
[1]: https://habrastorage.org/files/a9a/44d/fef/a9a44dfef7104a7790053ea576369812.png
[2]: http://sumldjwuqdfh54vc.onion/Public/LoneStarCell/
[3]: https://i.imgur.com/2KgMRNn.png
[4]: https://habrahabr.ru/post/278221/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 10:00:03
![][1] В сети Tor опубликована ссылка на [архив][2], содержащий регистрационные данные и финансовую информацию 3 млн абонентов крупнейшего телекоммуникационного оператора Либерии Lonestar Cell. Хакер под ником ROR[RG] [выложил][3] на одном из форумов ссылку и пароль для доступа к архиву — по его словам с помощью этих данных можно получить доступ к мобильным счетам пользователей оператора, а также их индивидуальные ключи идентификации и учетные данные сим-карт. ROR[RG] уточнил, что архив содержит не всю информацию, которую ему удалось похитить из сети оператора. [Читать дальше →][4]
[1]: https://habrastorage.org/files/a9a/44d/fef/a9a44dfef7104a7790053ea576369812.png
{kind=link}
[2]: http://sumldjwuqdfh54vc.onion/Public/LoneStarCell/
[3]: https://i.imgur.com/2KgMRNn.png
{kind=link}
[4]: https://habrahabr.ru/post/278221/#habracut
[>]
Примеры реализации Pub-Sub: Azure Topics, EventHub, ZeroMQ, microServiceBus, etc
habra.16
habrabot(difrex,1) — All
2016-03-01 11:00:03
Основная идея [Pub-Sub][1] довольно простая: "**publish–subscribe** is a [messaging pattern][2] where senders of [messages][3], called publishers, do not program the messages to be sent directly to specific receivers, called subscribers, but instead characterize published messages into classes without knowledge of which subscribers, if any, there may be. Similarly, subscribers express interest in one or more classes and only receive messages that are of interest, without knowledge of which publishers, if any, there are." В [свободном переводе][4] это может звучать так: "**Издатель-подписчик** ([англ.][5] _publisher-subscriber_ или [англ.][6] _pub/sub_) — [поведенческий][7] [шаблон проектирования][8] передачи сообщений, в котором отправители сообщений, именуемые издателями ([англ.][9] _publishers_), напрямую не привязаны программным кодом отправки сообщений к подписчикам ([англ.][10] _subscribers_). Вместо этого сообщения делятся на классы и не содержат сведений о своих подписчиках, если таковые есть. Аналогичным образом подписчики имеют дело с одним или несколькими классами сообщений, абстрагируясь от конкретных издателей." [Читать дальше →][11]
[1]: https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern
[2]: https://en.wikipedia.org/wiki/Messaging_pattern
[3]: https://en.wikipedia.org/wiki/Message_passing
[4]: https://ru.wikipedia.org/wiki/%D0%98%D0%B7%D0%B4%D0%B0%D1%82%D0%B5%D0%BB%D1%8C-%D0%BF%D0%BE%D0%B4%D0%BF%D0%B8%D1%81%D1%87%D0%B8%D0%BA_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)
[5]: https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA
[6]: https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA
[7]: https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5_%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD%D1%8B_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F
[8]: https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F
[9]: https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA
[10]: https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA
[11]: https://habrahabr.ru/post/278237/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 11:00:03
Основная идея [Pub-Sub][1] довольно простая: "**publish–subscribe** is a [messaging pattern][2] where senders of [messages][3], called publishers, do not program the messages to be sent directly to specific receivers, called subscribers, but instead characterize published messages into classes without knowledge of which subscribers, if any, there may be. Similarly, subscribers express interest in one or more classes and only receive messages that are of interest, without knowledge of which publishers, if any, there are." В [свободном переводе][4] это может звучать так: "**Издатель-подписчик** ([англ.][5] _publisher-subscriber_ или [англ.][6] _pub/sub_) — [поведенческий][7] [шаблон проектирования][8] передачи сообщений, в котором отправители сообщений, именуемые издателями ([англ.][9] _publishers_), напрямую не привязаны программным кодом отправки сообщений к подписчикам ([англ.][10] _subscribers_). Вместо этого сообщения делятся на классы и не содержат сведений о своих подписчиках, если таковые есть. Аналогичным образом подписчики имеют дело с одним или несколькими классами сообщений, абстрагируясь от конкретных издателей." [Читать дальше →][11]
[1]: https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern
[2]: https://en.wikipedia.org/wiki/Messaging_pattern
[3]: https://en.wikipedia.org/wiki/Message_passing
[4]: https://ru.wikipedia.org/wiki/%D0%98%D0%B7%D0%B4%D0%B0%D1%82%D0%B5%D0%BB%D1%8C-%D0%BF%D0%BE%D0%B4%D0%BF%D0%B8%D1%81%D1%87%D0%B8%D0%BA_(%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)
[5]: https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA
[6]: https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA
[7]: https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5_%D1%88%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD%D1%8B_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F
[8]: https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F
[9]: https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA
[10]: https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA
[11]: https://habrahabr.ru/post/278237/#habracut
[>]
Представляем драйвер Intel RealSense для Linux & OS X
habra.16
habrabot(difrex,1) — All
2016-03-01 13:00:02
![][1] До недавнего времени возможности технологии [Intel RealSense][2] были доступны только пользователям Windows, поддержка других операционных систем отсутствовала полностью, что, конечно, огорчало людей, их использовавших. Теперь эта несправедливость исправлена, по крайней мере, частично. В рамках своей open source программы Intel опубликовала [драйвер RealSense для Linux & OS X][3], обеспечивающий:
* получение изображения со всех моделей камер RealSense (F200, SR300, and R200), в том числе из нескольких источников сразу;
* доступ к сырым потокам RGB, глубины и ИК;
* доступ к синтетическим потокам (глубина, выравненная по цвету и т.д.);
* доступ к внутренней и внешней калибровочной информации;
* реализацию большей части hardware-specific функциональности (UVC XU).
Драйвер разрабатывался и тестировался на ОС Ubuntu 14.04.03 x64 с обновленным ядром 4.4 и GCC 4.9, а также OS X 10.8. с тулчейном Clang. librealsense обеспечивает совместимость с Robotic Operating System (ROS), OpenCV, Point Cloud Library (PCL) и многими другими рантаймами и фреймворками. Основные возможности библиотеки ускорены с помощью инструкций SSE3. librealsense общается с камерами напрямую через UVC и USB без привлечения рантаймов RealSense SDK. Большая часть кода платформо-независима, однако имеется небольшой слой абстракции, опирающийся на UVC-компоненты ОС. Внешних зависимостей у библиотеки две: GLFW3 (на всех платформах) и libusb-1.0 (Mac/Linux), [][4]
[1]: https://habrastorage.org/files/cc0/7c3/21f/cc07c321f71f4de08e19cf8ba8ae90f0.png
[2]: https://software.intel.com/ru-ru/RealSense/Home
[3]: https://github.com/IntelRealSense/librealsense
[4]: https://habrahabr.ru/post/277397/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 13:00:02
![][1] До недавнего времени возможности технологии [Intel RealSense][2] были доступны только пользователям Windows, поддержка других операционных систем отсутствовала полностью, что, конечно, огорчало людей, их использовавших. Теперь эта несправедливость исправлена, по крайней мере, частично. В рамках своей open source программы Intel опубликовала [драйвер RealSense для Linux & OS X][3], обеспечивающий:
* получение изображения со всех моделей камер RealSense (F200, SR300, and R200), в том числе из нескольких источников сразу;
* доступ к сырым потокам RGB, глубины и ИК;
* доступ к синтетическим потокам (глубина, выравненная по цвету и т.д.);
* доступ к внутренней и внешней калибровочной информации;
* реализацию большей части hardware-specific функциональности (UVC XU).
Драйвер разрабатывался и тестировался на ОС Ubuntu 14.04.03 x64 с обновленным ядром 4.4 и GCC 4.9, а также OS X 10.8. с тулчейном Clang. librealsense обеспечивает совместимость с Robotic Operating System (ROS), OpenCV, Point Cloud Library (PCL) и многими другими рантаймами и фреймворками. Основные возможности библиотеки ускорены с помощью инструкций SSE3. librealsense общается с камерами напрямую через UVC и USB без привлечения рантаймов RealSense SDK. Большая часть кода платформо-независима, однако имеется небольшой слой абстракции, опирающийся на UVC-компоненты ОС. Внешних зависимостей у библиотеки две: GLFW3 (на всех платформах) и libusb-1.0 (Mac/Linux), [][4]
[1]: https://habrastorage.org/files/cc0/7c3/21f/cc07c321f71f4de08e19cf8ba8ae90f0.png
{kind=link}
[2]: https://software.intel.com/ru-ru/RealSense/Home
[3]: https://github.com/IntelRealSense/librealsense
[4]: https://habrahabr.ru/post/277397/#habracut
[>]
Паспортный сканер своими руками
habra.16
habrabot(difrex,1) — All
2016-03-01 14:00:03
![][1] Привет, Хабр! В предыдущих статьях мы уже рассказывали вам про то, как нам удалось превратить [ввод паспортных данных на мобильных устройствах][2] из рутины в простую и быструю процедуру. Следующим закономерным шагом мы превратили наш **Smart PassportReader SDK** в серверную компоненту, облегчив тем самым крупным финансовым организациям работу с документами в бэк-офисах. Наконец, проявив изобретательскую смекалку и инженерный подход, нам удалось разработать программно-аппаратный комплекс (забегая вперед, представим его название — **Smart PassportBox**), позволяющий оптимизировать работу фронт-офисов и СКУД-решения. Поэтому, если вам интересно сколько директоров, программистов, паяльников, лобзиков и отверток требуется для создания полноценного ПАК, добро пожаловать под кат. [Читать дальше →][3]
[1]: https://habrastorage.org/files/067/eec/5d1/067eec5d124d4619aa62f04c37704f6f.jpg
[2]: https://habrahabr.ru/company/smartengines/blog/252703/
[3]: https://habrahabr.ru/post/278257/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 14:00:03
![][1] Привет, Хабр! В предыдущих статьях мы уже рассказывали вам про то, как нам удалось превратить [ввод паспортных данных на мобильных устройствах][2] из рутины в простую и быструю процедуру. Следующим закономерным шагом мы превратили наш **Smart PassportReader SDK** в серверную компоненту, облегчив тем самым крупным финансовым организациям работу с документами в бэк-офисах. Наконец, проявив изобретательскую смекалку и инженерный подход, нам удалось разработать программно-аппаратный комплекс (забегая вперед, представим его название — **Smart PassportBox**), позволяющий оптимизировать работу фронт-офисов и СКУД-решения. Поэтому, если вам интересно сколько директоров, программистов, паяльников, лобзиков и отверток требуется для создания полноценного ПАК, добро пожаловать под кат. [Читать дальше →][3]
[1]: https://habrastorage.org/files/067/eec/5d1/067eec5d124d4619aa62f04c37704f6f.jpg
{kind=link}
[2]: https://habrahabr.ru/company/smartengines/blog/252703/
[3]: https://habrahabr.ru/post/278257/#habracut
[>]
[Из песочницы] Возражения против принятия Coroutines с await в C++17
habra.16
habrabot(difrex,1) — All
2016-03-01 15:30:03
Недавно Россию посетила группа экспертов С++, участвующих в работе комитета по стандартизации. 25 февраля они участвовали в Q&A сессии, организованной Яндексом, а после выступали на конференции С++ Russia 2016. Одним из них был Гор Нишанов, автор предложения о включении C#-подобных сопрограмм (те которые async/await) в стандарт С++17. Ранее Гор выступал на CppCon 2015 с докладом "[С++ Сопрограммы — Абстракция с отрицательным оверхедом][1]". Такая возможность структурировать асинхронный код выглядит привлекательно, Гор в докладе убедительно показывает, что количество кода сокращается, а скорость работы возрастает по сравнению с «рукописными» State Machine. Кроме того, это одно из самых больших потенциальных изменений в следующем стандарте и привлекает к себе внимание. Судя по публикациям, proposal получил значительное одобрение и комитет склоняется к включению в стандарт. После этого я был весьма удивлен, когда загуглив упомянутый [proposal P0057][2], получил в выдаче встречный документ "[Coroutines belong in a TS][3]", который подвергает предлагаемую реализацию сопрограмм жесткой и весьма эмоциональной критике и требует не включать в С++17, а отложить для «обкатки» в Technical Specification. Отмечу, что не являюсь сторонником этих возражений, а приглашаю интересующихся к обсуждению, насколько обоснованны перечисленные претензии и все ли так плохо. Под катом «выжимка» из документа с небольшими комментариями. [Читать дальше →][4]
[1]: https://www.youtube.com/watch?v=_fu0gx-xseY
[2]: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0057r2.pdf
[3]: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2015/p0158r0.html
[4]: https://habrahabr.ru/post/278267/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 15:30:03
Недавно Россию посетила группа экспертов С++, участвующих в работе комитета по стандартизации. 25 февраля они участвовали в Q&A сессии, организованной Яндексом, а после выступали на конференции С++ Russia 2016. Одним из них был Гор Нишанов, автор предложения о включении C#-подобных сопрограмм (те которые async/await) в стандарт С++17. Ранее Гор выступал на CppCon 2015 с докладом "[С++ Сопрограммы — Абстракция с отрицательным оверхедом][1]". Такая возможность структурировать асинхронный код выглядит привлекательно, Гор в докладе убедительно показывает, что количество кода сокращается, а скорость работы возрастает по сравнению с «рукописными» State Machine. Кроме того, это одно из самых больших потенциальных изменений в следующем стандарте и привлекает к себе внимание. Судя по публикациям, proposal получил значительное одобрение и комитет склоняется к включению в стандарт. После этого я был весьма удивлен, когда загуглив упомянутый [proposal P0057][2], получил в выдаче встречный документ "[Coroutines belong in a TS][3]", который подвергает предлагаемую реализацию сопрограмм жесткой и весьма эмоциональной критике и требует не включать в С++17, а отложить для «обкатки» в Technical Specification. Отмечу, что не являюсь сторонником этих возражений, а приглашаю интересующихся к обсуждению, насколько обоснованны перечисленные претензии и все ли так плохо. Под катом «выжимка» из документа с небольшими комментариями. [Читать дальше →][4]
[1]: https://www.youtube.com/watch?v=_fu0gx-xseY
[2]: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0057r2.pdf
[3]: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2015/p0158r0.html
[4]: https://habrahabr.ru/post/278267/#habracut
[>]
[Из песочницы] Евклидов алгоритм генерации традиционных музыкальных ритмов
habra.16
habrabot(difrex,1) — All
2016-03-01 16:30:03
_Перевод статьи [Godfried Toussaint][1] [The Euclidean Algorithm Generates Traditional Musical Rhythms][2]._
# От переводчика
В [Sonic Pi][3] есть функция spread, которая принимает два числовых параметра и возвращает набор значений для генерации ритма. В описании этой функции есть ссылка на работу «The Euclidean Algorithm Generates Traditional Musical Rhythms». Эта блестящая статья, вышедшая аж в 2005 году, похоже, так и не была переведена на русский язык. Не будучи специалистом по переводам, я попытался, тем не менее, восполнить этот пробел.
# Конспект
_Евклидов_ алгоритм (дошедший до нас из «_Начал_» Евклида) подсчитывает наибольший общий делитель двух целых чисел. Настоящая работа демонстрирует, что структура евклидова алгоритма может быть использована для того, чтобы очень эффективно генерировать большое семейство ритмов, используемых в качестве пульсаций (_остинато_), в частности в музыке тропической Африки, и в традиционной музыке вообще. Эти ритмы, называемые здесь _евклидовыми_ ритмами, имеют то свойство, что их ударные рисунки распределяются насколько возможно равномерно. _Евклидовы_ ритмы также находят приложение в ускорителях в атомной физике и в компьютерных науках, и тесно связаны с несколькими семействами слов и последовательностями, изучаемыми комбинаторикой слов, такими как евклидовы строки, с которыми сравнивают _евклидовы_ ритмы. [Читать дальше →][4]
[1]: https://en.wikipedia.org/wiki/Godfried_Toussaint
[2]: http://cgm.cs.mcgill.ca/~godfried/publications/banff.pdf
[3]: http://sonic-pi.net/
[4]: https://habrahabr.ru/post/278265/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 16:30:03
_Перевод статьи [Godfried Toussaint][1] [The Euclidean Algorithm Generates Traditional Musical Rhythms][2]._
# От переводчика
В [Sonic Pi][3] есть функция spread, которая принимает два числовых параметра и возвращает набор значений для генерации ритма. В описании этой функции есть ссылка на работу «The Euclidean Algorithm Generates Traditional Musical Rhythms». Эта блестящая статья, вышедшая аж в 2005 году, похоже, так и не была переведена на русский язык. Не будучи специалистом по переводам, я попытался, тем не менее, восполнить этот пробел.
# Конспект
_Евклидов_ алгоритм (дошедший до нас из «_Начал_» Евклида) подсчитывает наибольший общий делитель двух целых чисел. Настоящая работа демонстрирует, что структура евклидова алгоритма может быть использована для того, чтобы очень эффективно генерировать большое семейство ритмов, используемых в качестве пульсаций (_остинато_), в частности в музыке тропической Африки, и в традиционной музыке вообще. Эти ритмы, называемые здесь _евклидовыми_ ритмами, имеют то свойство, что их ударные рисунки распределяются насколько возможно равномерно. _Евклидовы_ ритмы также находят приложение в ускорителях в атомной физике и в компьютерных науках, и тесно связаны с несколькими семействами слов и последовательностями, изучаемыми комбинаторикой слов, такими как евклидовы строки, с которыми сравнивают _евклидовы_ ритмы. [Читать дальше →][4]
[1]: https://en.wikipedia.org/wiki/Godfried_Toussaint
[2]: http://cgm.cs.mcgill.ca/~godfried/publications/banff.pdf
[3]: http://sonic-pi.net/
[4]: https://habrahabr.ru/post/278265/#habracut
[>]
Отчёт со встречи Perl-программистов Moscow.pm 4 февраля
habra.16
habrabot(difrex,1) — All
2016-03-01 17:30:02
![image][1] В начале февраля в офисе Mail.Ru Group прошла очередная встреча Moscow.pm, организованная сообществом Perl-программистов. Выступления, прозвучавшие на встрече, были посвящены теории и практическим задачам, возникающим в ходе разработки. Под катом вы найдёте видеозаписи и презентации докладов. [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/707/723/436/70772343650f66c353ad80a06d5272ca.jpg
[2]: https://habrahabr.ru/post/278275/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 17:30:02
![image][1] В начале февраля в офисе Mail.Ru Group прошла очередная встреча Moscow.pm, организованная сообществом Perl-программистов. Выступления, прозвучавшие на встрече, были посвящены теории и практическим задачам, возникающим в ходе разработки. Под катом вы найдёте видеозаписи и презентации докладов. [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/707/723/436/70772343650f66c353ad80a06d5272ca.jpg
{kind=link}
[2]: https://habrahabr.ru/post/278275/#habracut
[>]
Прячем фактическое место, где стоит сервер компании: практические методы и вопрос
habra.16
habrabot(difrex,1) — All
2016-03-01 18:30:02
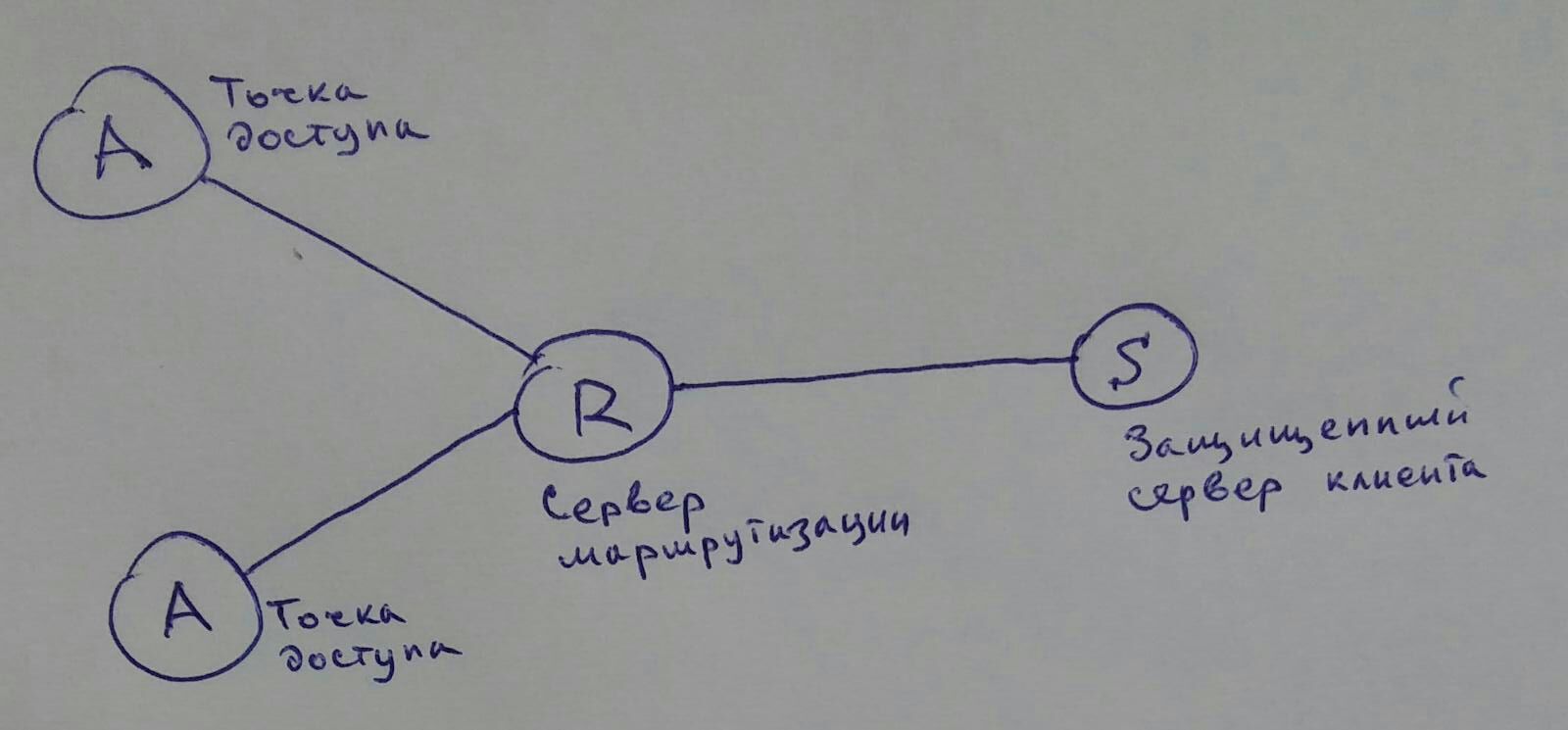
Привет! Я руковожу небольшим ИТ-аутсорсингом, и к нам в прошлом году обратилось сразу несколько клиентов с похожими задачами — **сделать так, чтобы никто не узнал, где именно стоят сервера компании.** В первом случае это был строительный бизнес, у них одна из особенностей сферы в том, что на машинах не должно быть даже следов переписки, особенно перед тендерами. Поэтому у них RDP-ферма, а в офисе терминалы. Прятать надо было ядро. Во втором случае — сервисная компания, работающая с известными личностями (у них это просто слой безопасности, который они не считают лишним). В третьем — производство для нефтяной сферы, у которых по сфере нереальная недобросовестная конкуренция с забросом инсайдеров в чужие офисы. Мы придумали вот такую схему: ![][1] В центре — ядро, вокруг ядра — релей-серверы периметра (дешёвые машины-прокси, на каждой — свой сервис), дальше — терминалы конечных пользователей. Покритикуйте, пожалуйста, ну или попробуйте вычислить IP сервера ядра на примере в конце. [Читать дальше →][2]
[1]: https://habrastorage.org/files/5a4/d89/6e5/5a4d896e57f6420bab05d55f74211849.jpg
[2]: https://habrahabr.ru/post/278271/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 18:30:02
Привет! Я руковожу небольшим ИТ-аутсорсингом, и к нам в прошлом году обратилось сразу несколько клиентов с похожими задачами — **сделать так, чтобы никто не узнал, где именно стоят сервера компании.** В первом случае это был строительный бизнес, у них одна из особенностей сферы в том, что на машинах не должно быть даже следов переписки, особенно перед тендерами. Поэтому у них RDP-ферма, а в офисе терминалы. Прятать надо было ядро. Во втором случае — сервисная компания, работающая с известными личностями (у них это просто слой безопасности, который они не считают лишним). В третьем — производство для нефтяной сферы, у которых по сфере нереальная недобросовестная конкуренция с забросом инсайдеров в чужие офисы. Мы придумали вот такую схему: ![][1] В центре — ядро, вокруг ядра — релей-серверы периметра (дешёвые машины-прокси, на каждой — свой сервис), дальше — терминалы конечных пользователей. Покритикуйте, пожалуйста, ну или попробуйте вычислить IP сервера ядра на примере в конце. [Читать дальше →][2]
[1]: https://habrastorage.org/files/5a4/d89/6e5/5a4d896e57f6420bab05d55f74211849.jpg
{kind=link}
[2]: https://habrahabr.ru/post/278271/#habracut
[>]
Эрик Кровавый Топор (Крис Гогганс): “Information wants to be free”
habra.16
habrabot(difrex,1) — All
2016-03-01 19:00:02
_«Все, что ты видишь, является частью головоломки»_ ![image][1] **Эрик Кровавый Топор** [Крис Гогганс][2] (Erik Bloodaxe, в честь короля викингов [Эрика I Норвежского][3]) — участник-основатель группы [«Legion of Doom»][4], и бывший редактор журнала "[Phrack][5]". [Лойд Бланкеншип][6], также известный как Ментор (The Mentor), описал Гогганса как _«лучшего хакера, которого я встречал»_. Секретная Служба США устраивала облаву на Гогганса 1 марта 1990 года, но не смогла его поймать. [Читать дальше →][7]
[1]: https://habrastorage.org/getpro/habr/post_images/ab4/2e2/6ff/ab42e26ffbee2c3b4c06ed80e42bc69a.jpg
[2]: https://en.wikipedia.org/wiki/Erik_Bloodaxe_(hacker)
[3]: https://en.wikipedia.org/wiki/Eric_I_of_Norway
[4]: https://en.wikipedia.org/wiki/Legion_of_Doom_%28hacking%29
[5]: https://en.wikipedia.org/wiki/Phrack
[6]: https://en.wikipedia.org/wiki/Loyd_Blankenship
[7]: https://habrahabr.ru/post/278291/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 19:00:02
_«Все, что ты видишь, является частью головоломки»_ ![image][1] **Эрик Кровавый Топор** [Крис Гогганс][2] (Erik Bloodaxe, в честь короля викингов [Эрика I Норвежского][3]) — участник-основатель группы [«Legion of Doom»][4], и бывший редактор журнала "[Phrack][5]". [Лойд Бланкеншип][6], также известный как Ментор (The Mentor), описал Гогганса как _«лучшего хакера, которого я встречал»_. Секретная Служба США устраивала облаву на Гогганса 1 марта 1990 года, но не смогла его поймать. [Читать дальше →][7]
[1]: https://habrastorage.org/getpro/habr/post_images/ab4/2e2/6ff/ab42e26ffbee2c3b4c06ed80e42bc69a.jpg
{kind=link}
[2]: https://en.wikipedia.org/wiki/Erik_Bloodaxe_(hacker)
[3]: https://en.wikipedia.org/wiki/Eric_I_of_Norway
[4]: https://en.wikipedia.org/wiki/Legion_of_Doom_%28hacking%29
[5]: https://en.wikipedia.org/wiki/Phrack
[6]: https://en.wikipedia.org/wiki/Loyd_Blankenship
[7]: https://habrahabr.ru/post/278291/#habracut
[>]
Эрик Кровавый Топор (Крис Гогганс): «Information wants to be free»
habra.16
habrabot(difrex,1) — All
2016-03-01 19:30:03
_«Все, что ты видишь, является частью головоломки»_ ![image][1] **Эрик Кровавый Топор** [Крис Гогганс][2] (Erik Bloodaxe, в честь короля викингов [Эрика I Норвежского][3]) — участник-основатель группы [«Legion of Doom»][4], и бывший редактор журнала "[Phrack][5]". [Лойд Бланкеншип][6], также известный как Ментор (The Mentor), описал Гогганса как _«лучшего хакера, которого я встречал»_. Секретная Служба США устраивала облаву на Гогганса 1 марта 1990 года, но не смогла его поймать. [Читать дальше →][7]
[1]: https://habrastorage.org/getpro/habr/post_images/ab4/2e2/6ff/ab42e26ffbee2c3b4c06ed80e42bc69a.jpg
[2]: https://en.wikipedia.org/wiki/Erik_Bloodaxe_(hacker)
[3]: https://en.wikipedia.org/wiki/Eric_I_of_Norway
[4]: https://en.wikipedia.org/wiki/Legion_of_Doom_%28hacking%29
[5]: https://en.wikipedia.org/wiki/Phrack
[6]: https://en.wikipedia.org/wiki/Loyd_Blankenship
[7]: https://habrahabr.ru/post/278291/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 19:30:03
_«Все, что ты видишь, является частью головоломки»_ ![image][1] **Эрик Кровавый Топор** [Крис Гогганс][2] (Erik Bloodaxe, в честь короля викингов [Эрика I Норвежского][3]) — участник-основатель группы [«Legion of Doom»][4], и бывший редактор журнала "[Phrack][5]". [Лойд Бланкеншип][6], также известный как Ментор (The Mentor), описал Гогганса как _«лучшего хакера, которого я встречал»_. Секретная Служба США устраивала облаву на Гогганса 1 марта 1990 года, но не смогла его поймать. [Читать дальше →][7]
[1]: https://habrastorage.org/getpro/habr/post_images/ab4/2e2/6ff/ab42e26ffbee2c3b4c06ed80e42bc69a.jpg
[2]: https://en.wikipedia.org/wiki/Erik_Bloodaxe_(hacker)
[3]: https://en.wikipedia.org/wiki/Eric_I_of_Norway
[4]: https://en.wikipedia.org/wiki/Legion_of_Doom_%28hacking%29
[5]: https://en.wikipedia.org/wiki/Phrack
[6]: https://en.wikipedia.org/wiki/Loyd_Blankenship
[7]: https://habrahabr.ru/post/278291/#habracut
[>]
Краткий курс компьютерной графики, аддендум: лечим по фотографии
habra.16
habrabot(difrex,1) — All
2016-03-01 21:00:03
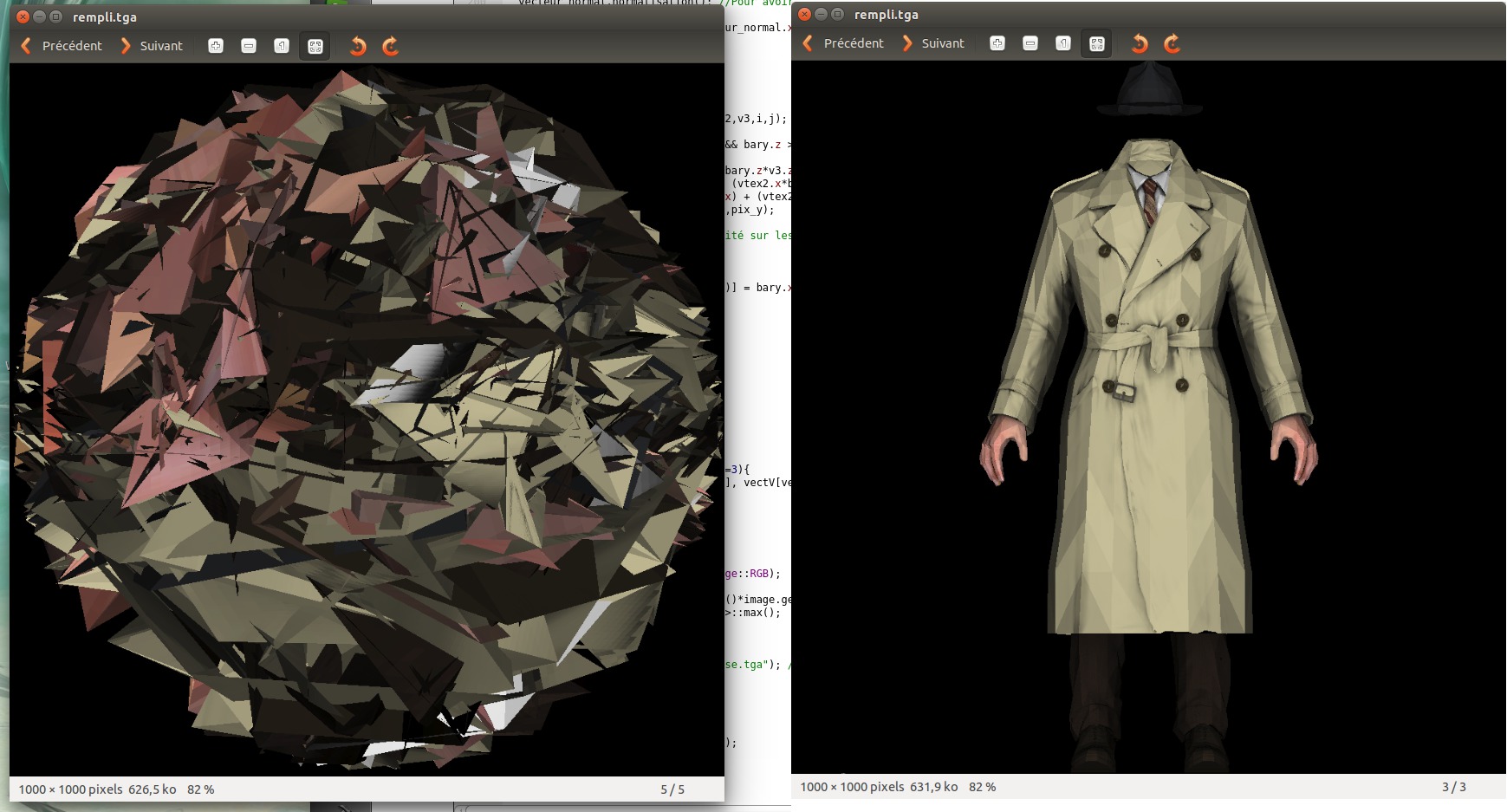
Год назад я опубликовал [цикл статей,][1] имевший целью популяризацию графического программирования. Много воды утекло с тех пор, появилась [англоязычная версия][2] цикла, прошедшая некоторую полировку по сравнению с оригинальным. За этот год мне написало несколько сотен человек, причём многие просили помочь отладить их код. Я предлагаю вам поиграть в игру: я даю только картинку, на которой видна проблема, попробуйте понять, в каком месте кода нужно искать баг, что именно сломано. Я в эту игру играю ежедневно, досконально смотреть сотни версий рендера у меня нет никакой возможности, поэтому я, как заправский экстрасенс, лечу по фотографии. Зачастую успешно. Абсолютно все картинки сгенерированы не мной, я лишь собрал самые типичные баги. Настоящая людская боль перед вашими глазами, ко мне, понятно, обращаются (особенно по почте) только после того, как не могут сами найти баг в разумное время. Вот первый баг для затравки, слева битый рендер, справа то, что ожидалось: ![][3] [Играть!][4]
[1]: https://habrahabr.ru/post/248963/
[2]: https://github.com/ssloy/tinyrenderer/wiki
[3]: https://habrastorage.org/getpro/habr/post_images/d3e/ccd/e4f/d3eccde4f31474b9ade4b264477e8579.jpg
[4]: https://habrahabr.ru/post/278309/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 21:00:03
Год назад я опубликовал [цикл статей,][1] имевший целью популяризацию графического программирования. Много воды утекло с тех пор, появилась [англоязычная версия][2] цикла, прошедшая некоторую полировку по сравнению с оригинальным. За этот год мне написало несколько сотен человек, причём многие просили помочь отладить их код. Я предлагаю вам поиграть в игру: я даю только картинку, на которой видна проблема, попробуйте понять, в каком месте кода нужно искать баг, что именно сломано. Я в эту игру играю ежедневно, досконально смотреть сотни версий рендера у меня нет никакой возможности, поэтому я, как заправский экстрасенс, лечу по фотографии. Зачастую успешно. Абсолютно все картинки сгенерированы не мной, я лишь собрал самые типичные баги. Настоящая людская боль перед вашими глазами, ко мне, понятно, обращаются (особенно по почте) только после того, как не могут сами найти баг в разумное время. Вот первый баг для затравки, слева битый рендер, справа то, что ожидалось: ![][3] [Играть!][4]
[1]: https://habrahabr.ru/post/248963/
[2]: https://github.com/ssloy/tinyrenderer/wiki
[3]: https://habrastorage.org/getpro/habr/post_images/d3e/ccd/e4f/d3eccde4f31474b9ade4b264477e8579.jpg
{kind=link}
[4]: https://habrahabr.ru/post/278309/#habracut
[>]
Получаем доступ к облаку XenServer через доступ к одной виртуальной машине
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
![][1] Совсем скоро, 11 марта, стартует online-этап ежегодного соревнования по кибербезопасности [NeoQUEST-2016][2]! В преддверии этого публикуем разбор одного из заданий «очной ставки» NeoQUEST-2015. Это задание под названием «Истина где-то рядом» было направлено на получение доступа ко всему облаку XenServer, имея доступ только лишь к одной виртуалке! Такой хак осуществим с помощью специального апплета, ранее используемого XenServer, позволяющего получить доступ по VNC к виртуальной машине. Под катом опишем исходные данные для задания и расскажем, как можно было пройти это задание двумя способами:
* используя XenAPI
* используя Web
[Читать дальше →][3]
[1]: https://habrastorage.org/files/db1/9c6/7c5/db19c67c51b04c94a548e49767217cc9.png
[2]: http://neoquest.ru
[3]: https://habrahabr.ru/post/264555/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
![][1] Совсем скоро, 11 марта, стартует online-этап ежегодного соревнования по кибербезопасности [NeoQUEST-2016][2]! В преддверии этого публикуем разбор одного из заданий «очной ставки» NeoQUEST-2015. Это задание под названием «Истина где-то рядом» было направлено на получение доступа ко всему облаку XenServer, имея доступ только лишь к одной виртуалке! Такой хак осуществим с помощью специального апплета, ранее используемого XenServer, позволяющего получить доступ по VNC к виртуальной машине. Под катом опишем исходные данные для задания и расскажем, как можно было пройти это задание двумя способами:
* используя XenAPI
* используя Web
[Читать дальше →][3]
[1]: https://habrastorage.org/files/db1/9c6/7c5/db19c67c51b04c94a548e49767217cc9.png
{kind=link}
[2]: http://neoquest.ru
[3]: https://habrahabr.ru/post/264555/#habracut
[>]
Сравнение SSL сертификатов с верификацией домена
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
После открытия проекта [HTTPS.menu][1] я решил сделать небольшое сравнение сертификатов разных сертифицирующих центров с верификацией только по доменному имени. [![][2]][3] Верификация по домену выглядит довольно просто — на один из адресов электронной почты вида admin@domain.zone, administrator@domain.zone, hostmaster@domain.zone, postmaster@domain.zone, webmaster@domain.zone или e-mail адрес из whois приходит письмо с кодом верификации, а пользователь должен подтвердить владение доменом, кликнув по ссылке и указав секретный ключ, полученный в письме. После этого на почту приходит сам сертификат. Сегодня в обзоре речь пойдет о 5 различных сертификатах от 3 удостоверяющих центров: [Comodo PositiveSSL][4] [RapidSSL][5] [Comodo EssentialSSL][6] [Thawte SSL123][7] [GeoTrust QuickSSL premium][8] [Читать дальше →][9]
[1]: http://https.menu
[2]: https://habrastorage.org/files/061/cf2/39a/061cf239abf64678a3f5b825eae36a05.png
[3]: http://https.menu
[4]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a1
[5]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a2
[6]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a3
[7]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a4
[8]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a5
[9]: https://habrahabr.ru/post/278255/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
После открытия проекта [HTTPS.menu][1] я решил сделать небольшое сравнение сертификатов разных сертифицирующих центров с верификацией только по доменному имени. [![][2]][3] Верификация по домену выглядит довольно просто — на один из адресов электронной почты вида admin@domain.zone, administrator@domain.zone, hostmaster@domain.zone, postmaster@domain.zone, webmaster@domain.zone или e-mail адрес из whois приходит письмо с кодом верификации, а пользователь должен подтвердить владение доменом, кликнув по ссылке и указав секретный ключ, полученный в письме. После этого на почту приходит сам сертификат. Сегодня в обзоре речь пойдет о 5 различных сертификатах от 3 удостоверяющих центров: [Comodo PositiveSSL][4] [RapidSSL][5] [Comodo EssentialSSL][6] [Thawte SSL123][7] [GeoTrust QuickSSL premium][8] [Читать дальше →][9]
[1]: http://https.menu
[2]: https://habrastorage.org/files/061/cf2/39a/061cf239abf64678a3f5b825eae36a05.png
{kind=link}
[3]: http://https.menu
[4]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a1
[5]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a2
[6]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a3
[7]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a4
[8]: https://habrahabr.ru/company/hosting-cafe/blog/278255/#a5
[9]: https://habrahabr.ru/post/278255/#habracut
[>]
Как обезопасить процесс онлайн-покупок
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
_С повсеместным распространением банковских карт стандарта EMV риски оффлайн-мошенничества заметно сократились, но как при этом складывается ситуация с онлайн-мошенничеством? Какие меры могут предпринять магазины, банки и потребители, чтобы бороться с ним более эффективно?_ [Читать дальше - Статистика и практика обеспечения безопасности карточных платежей][1]
[1]: https://habrahabr.ru/post/278289/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
_С повсеместным распространением банковских карт стандарта EMV риски оффлайн-мошенничества заметно сократились, но как при этом складывается ситуация с онлайн-мошенничеством? Какие меры могут предпринять магазины, банки и потребители, чтобы бороться с ним более эффективно?_ [Читать дальше - Статистика и практика обеспечения безопасности карточных платежей][1]
[1]: https://habrahabr.ru/post/278289/#habracut
[>]
Простой пример визуализации результатов работы инструкции CPUID
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
Было время, когда много полезной информации о новых процессорах можно было выудить из документа «[Intel Processor Identification and the CPUID Instruction][1]». Сей мануал регулярно обновлялся и был полон описаниями инноваций, буквально переполнявших компанию Intel. К сожалению, с мая 2012 года описание инструкции CPUID перекочевало в многотомник «Intel 64 and IA-32 Architectures Software Developer’s Manual», а ссылка на указанный документ форвардится на один из томов ярбуха (конкретно – [Vol. 2A][2]). С этого момента уследить за новшествами стало сложнее. Возникла мысль с помощью несложной утилиты визуализировать результаты работы CPUID с тем, с тем чтобы мониторить внедрение новинок и быть в курсе. [Читать дальше →][3]
[1]: http://www.intel.com/content/www/us/en/processors/processor-identification-cpuid-instruction-note.html
[2]: http://www.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-software-developer-vol-2a-manual.html
[3]: https://habrahabr.ru/post/278281/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
Было время, когда много полезной информации о новых процессорах можно было выудить из документа «[Intel Processor Identification and the CPUID Instruction][1]». Сей мануал регулярно обновлялся и был полон описаниями инноваций, буквально переполнявших компанию Intel. К сожалению, с мая 2012 года описание инструкции CPUID перекочевало в многотомник «Intel 64 and IA-32 Architectures Software Developer’s Manual», а ссылка на указанный документ форвардится на один из томов ярбуха (конкретно – [Vol. 2A][2]). С этого момента уследить за новшествами стало сложнее. Возникла мысль с помощью несложной утилиты визуализировать результаты работы CPUID с тем, с тем чтобы мониторить внедрение новинок и быть в курсе. [Читать дальше →][3]
[1]: http://www.intel.com/content/www/us/en/processors/processor-identification-cpuid-instruction-note.html
[2]: http://www.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-software-developer-vol-2a-manual.html
[3]: https://habrahabr.ru/post/278281/#habracut
[>]
DROWN — еще одна уязвимость в OpenSSL
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
1 марта 2016 года в сети появилась информация о новой уязвимости в OpenSSL под названием DROWN Уязвимость позволяет провести Man-In-The-Middle на сайты, которые используют SSLv2. По [некоторым данным][1], уязвимости подвержены порядка 33% серверов использующих HTTPS, в том числе сайты таких крупных компаний, как Yahoo, Alibaba, Weibo, Buzzfeed, weather.com, Flickr и Samsung. При этом уязвимость достаточно легко эксплуатировать: для расшифровки HTTPS трафика достаточно отправить специально сформированный пакет на сервер. [Читать дальше →][2]
[1]: http://drownattack.com
[2]: https://habrahabr.ru/post/278301/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 21:30:02
1 марта 2016 года в сети появилась информация о новой уязвимости в OpenSSL под названием DROWN Уязвимость позволяет провести Man-In-The-Middle на сайты, которые используют SSLv2. По [некоторым данным][1], уязвимости подвержены порядка 33% серверов использующих HTTPS, в том числе сайты таких крупных компаний, как Yahoo, Alibaba, Weibo, Buzzfeed, weather.com, Flickr и Samsung. При этом уязвимость достаточно легко эксплуатировать: для расшифровки HTTPS трафика достаточно отправить специально сформированный пакет на сервер. [Читать дальше →][2]
[1]: http://drownattack.com
[2]: https://habrahabr.ru/post/278301/#habracut
[>]
Kotlin для начинающих
habra.16
habrabot(difrex,1) — All
2016-03-01 22:00:02
Уже не мало нашумел Kotlin в мире программирования, не мало профессиональных инженеров уже обратил на него внимание, но также есть и те кому он не симпатизирует. В данном топике я бы хотел обратить внимание тех начинающих программистов которые возможно только делают свой выбор языка программирования, которому бы хотели посвятить свою жизнь так сказать. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278277/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-01 22:00:02
Уже не мало нашумел Kotlin в мире программирования, не мало профессиональных инженеров уже обратил на него внимание, но также есть и те кому он не симпатизирует. В данном топике я бы хотел обратить внимание тех начинающих программистов которые возможно только делают свой выбор языка программирования, которому бы хотели посвятить свою жизнь так сказать. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278277/#habracut
[>]
Уязвимость DROWN в SSLv2 позволяет дешифровать TLS-трафик
habra.16
habrabot(difrex,1) — All
2016-03-02 13:30:02
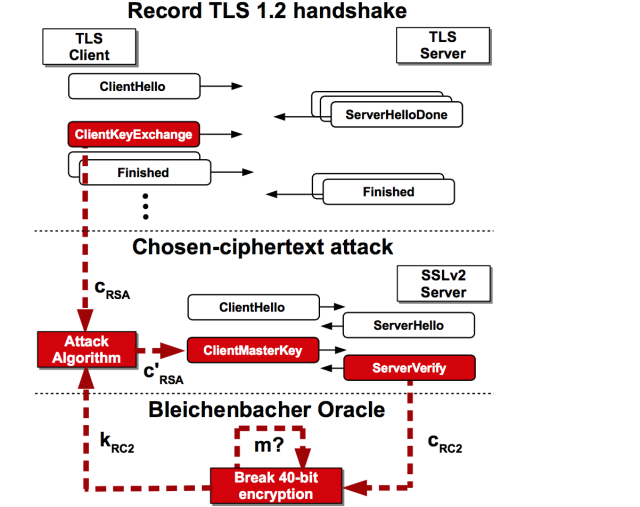
![image][1] SSLv2, протокол шифрования от Netscape, вышедший в 1995 году и потерявший актуальность уже в 1996, казалось бы, в 2016 году должен быть отключен во всем ПО, использующем SSL/TLS-шифрование, особенно после уязвимостей [POODLE][2] в SSLv3, позволяющей дешифровать 1 байт за 256 запросов, и [FREAK][3], связанной с ослабленными (экспортными) версиями шифров. И если клиентское ПО (например, браузеры) давно не поддерживает подключения по протоколу SSLv2, и, с недавнего времени, и SSLv3, то с серверным ПО не все так однозначно. Группа исследователей из Тель-Авивского университета, Мюнстенского университета прикладных наук, Рурского университета в Бохуме, Университета Пенсильвании, Мичиганского университета, Two Sigma, Google, проекта Hashcat и OpenSSL обнаружили уязвимость под названием DROWN — **D**ecrypting **R**SA using **O**bsolete and **W**eakened e**N**cryption, которая позволяет дешифровать TLS-трафик клиента, если на серверной стороне не отключена поддержка протокола SSLv2 во всех серверах, оперирующих одним и тем же приватным ключом. Согласно исследованию, 25% из миллиона самых посещаемых веб-сайтов подвержены этой уязвимости, или 22% из всех просканированных серверов, использующих сертификаты, выданные публичными центрами сертификации.
## Почему это возможно?
Несмотря на то, что у большинства веб-серверов протокол SSLv2 отключен по умолчанию, и его никто не будет включать намеренно, данная атака позволяет дешифровать TLS-трафик, имея доступ к любому серверу, поддерживающему SSLv2, и использующему такой же приватный ключ, что и веб-сервер. Часто можно встретить использование одного и того же сертификата для веб-сервера и почтового сервера, а также для FTPS. Общий вариант атаки эксплуатирует уязвимость в экспортных шифрах SSLv2, использующие 40-битные ключи RSA. [Читать дальше →][4]
[1]: https://habrastorage.org/getpro/habr/post_images/0b2/035/34e/0b203534e5c820ee1a89175ad5053968.png
[2]: https://habrahabr.ru/company/dsec/blog/240499/
[3]: https://habrahabr.ru/company/dsec/blog/252165/
[4]: https://habrahabr.ru/post/278335/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-02 13:30:02
![image][1] SSLv2, протокол шифрования от Netscape, вышедший в 1995 году и потерявший актуальность уже в 1996, казалось бы, в 2016 году должен быть отключен во всем ПО, использующем SSL/TLS-шифрование, особенно после уязвимостей [POODLE][2] в SSLv3, позволяющей дешифровать 1 байт за 256 запросов, и [FREAK][3], связанной с ослабленными (экспортными) версиями шифров. И если клиентское ПО (например, браузеры) давно не поддерживает подключения по протоколу SSLv2, и, с недавнего времени, и SSLv3, то с серверным ПО не все так однозначно. Группа исследователей из Тель-Авивского университета, Мюнстенского университета прикладных наук, Рурского университета в Бохуме, Университета Пенсильвании, Мичиганского университета, Two Sigma, Google, проекта Hashcat и OpenSSL обнаружили уязвимость под названием DROWN — **D**ecrypting **R**SA using **O**bsolete and **W**eakened e**N**cryption, которая позволяет дешифровать TLS-трафик клиента, если на серверной стороне не отключена поддержка протокола SSLv2 во всех серверах, оперирующих одним и тем же приватным ключом. Согласно исследованию, 25% из миллиона самых посещаемых веб-сайтов подвержены этой уязвимости, или 22% из всех просканированных серверов, использующих сертификаты, выданные публичными центрами сертификации.
## Почему это возможно?
Несмотря на то, что у большинства веб-серверов протокол SSLv2 отключен по умолчанию, и его никто не будет включать намеренно, данная атака позволяет дешифровать TLS-трафик, имея доступ к любому серверу, поддерживающему SSLv2, и использующему такой же приватный ключ, что и веб-сервер. Часто можно встретить использование одного и того же сертификата для веб-сервера и почтового сервера, а также для FTPS. Общий вариант атаки эксплуатирует уязвимость в экспортных шифрах SSLv2, использующие 40-битные ключи RSA. [Читать дальше →][4]
[1]: https://habrastorage.org/getpro/habr/post_images/0b2/035/34e/0b203534e5c820ee1a89175ad5053968.png
{kind=link}
[2]: https://habrahabr.ru/company/dsec/blog/240499/
[3]: https://habrahabr.ru/company/dsec/blog/252165/
[4]: https://habrahabr.ru/post/278335/#habracut
[>]
[Перевод] Управление приватными данными классов ES6
habra.16
habrabot(difrex,1) — All
2016-03-02 19:30:02
В этой статье рассматриваются 4 подхода к управлению приватными данными классов ES6: 1. Хранение данных в конструкторе класса. 2. Маркировка приватных свойств через соглашение об именовании (например, префиксное подчеркивание). 3. Хранение приватных данных в WeakMaps. 4. Использование символов в виде ключей для приватных свойств. Первый и второй подходы широко использовались в ES5, а третий и четвертый – появились только в ES6. Давайте поочередно рассмотрим каждый на одном примере. ![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/5f4/e8e/2ac/5f4e8e2acde940a28a896d09f6e56185.png
[2]: https://habrahabr.ru/post/278377/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-02 19:30:02
В этой статье рассматриваются 4 подхода к управлению приватными данными классов ES6: 1. Хранение данных в конструкторе класса. 2. Маркировка приватных свойств через соглашение об именовании (например, префиксное подчеркивание). 3. Хранение приватных данных в WeakMaps. 4. Использование символов в виде ключей для приватных свойств. Первый и второй подходы широко использовались в ES5, а третий и четвертый – появились только в ES6. Давайте поочередно рассмотрим каждый на одном примере. ![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/5f4/e8e/2ac/5f4e8e2acde940a28a896d09f6e56185.png
{kind=link}
[2]: https://habrahabr.ru/post/278377/#habracut
[>]
Доллар
habra.16
habrabot(difrex,1) — All
2016-03-03 07:30:03
![][1] Последние два года вся страна пристально следит за курсом доллара. Новостные выпуски пестрят громкими репортажами о долларе. Все говорят о долларе. А что, если мы на фоне горячего интереса, разберемся с тем, как формируется цена доллара, посмотрим кто и как торгует валютой?! Все результаты, представленные в данной статье, получены на основе официальных торговых данных full orders log (полный журнал заявок), купленные на [Московской Бирже][2]. Мы покажем реальные торги изнутри. Параллельно, познакомимся со стандартными методами анализа рынка. Такая аналитика стоит не малых денег и её могут позволить ограниченное число «компаний». Инструментом для анализа данных будет Java. Анализируемый биржевой инструмент — [USDRUB\_TOM][3]. Наша задача вытащить любопытные детали из имеющихся данных и попробовать сделать определенные выводы. [Читать дальше →][4]
[1]: https://habrastorage.org/files/c52/839/265/c5283926576b4f40b2e09673f8bc00d2.jpg
[2]: http://moex.com/ru/orders?historicaldata
[3]: http://moex.com/ru/issue/USD000UTSTOM/CETS
[4]: https://habrahabr.ru/post/278403/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 07:30:03
![][1] Последние два года вся страна пристально следит за курсом доллара. Новостные выпуски пестрят громкими репортажами о долларе. Все говорят о долларе. А что, если мы на фоне горячего интереса, разберемся с тем, как формируется цена доллара, посмотрим кто и как торгует валютой?! Все результаты, представленные в данной статье, получены на основе официальных торговых данных full orders log (полный журнал заявок), купленные на [Московской Бирже][2]. Мы покажем реальные торги изнутри. Параллельно, познакомимся со стандартными методами анализа рынка. Такая аналитика стоит не малых денег и её могут позволить ограниченное число «компаний». Инструментом для анализа данных будет Java. Анализируемый биржевой инструмент — [USDRUB\_TOM][3]. Наша задача вытащить любопытные детали из имеющихся данных и попробовать сделать определенные выводы. [Читать дальше →][4]
[1]: https://habrastorage.org/files/c52/839/265/c5283926576b4f40b2e09673f8bc00d2.jpg
{kind=link}
[2]: http://moex.com/ru/orders?historicaldata
[3]: http://moex.com/ru/issue/USD000UTSTOM/CETS
[4]: https://habrahabr.ru/post/278403/#habracut
[>]
Дайджест KolibriOS #11 все новости с последнего выпуска и Google Summer of Code 2016
habra.16
habrabot(difrex,1) — All
2016-03-03 10:30:03
![][1]Развитие Колибри продолжается. И в последнее время, было уделено больше усилий на то, чтобы сделать ее более дружелюбной и комфортабельной для простого пользователя. Для этого относительно недавно был внедрен новый системный шрифт, и сейчас ведется работа по переводу программ на его использования, а также улучшение их внешнего вида. Были также написаны некоторые программы для простых пользователей, чтобы упростить им работу и знакомство с ОС, и уверен что, это только начало. Ну и конечно добро пожаловать под кат, всем тем кто хочет узнать больше. [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/332/ac0/97c/332ac097cb7bfba245943a942c69f564.png
[2]: https://habrahabr.ru/post/278315/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 10:30:03
![][1]Развитие Колибри продолжается. И в последнее время, было уделено больше усилий на то, чтобы сделать ее более дружелюбной и комфортабельной для простого пользователя. Для этого относительно недавно был внедрен новый системный шрифт, и сейчас ведется работа по переводу программ на его использования, а также улучшение их внешнего вида. Были также написаны некоторые программы для простых пользователей, чтобы упростить им работу и знакомство с ОС, и уверен что, это только начало. Ну и конечно добро пожаловать под кат, всем тем кто хочет узнать больше. [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/332/ac0/97c/332ac097cb7bfba245943a942c69f564.png
{kind=link}
[2]: https://habrahabr.ru/post/278315/#habracut
[>]
[Из песочницы] Бинаризация изображений: алгоритм Брэдли
habra.16
habrabot(difrex,1) — All
2016-03-03 12:30:02
Этот пост я хочу посвятить приятному трофею, добытому в англоязычном интернете. Речь пойдет об одном из методов адаптивной бинаризации изображений, методе Брэдли (или Брэдли-Рота, поскольку авторов двое).
#### Немного теории
Процесс бинаризации – это перевод цветного (или в градациях серого) изображения в двухцветное черно-белое. Главным параметром такого преобразования является порог t – значение, с которым сравнивается яркость каждого пикселя. По результатам сравнения, пикселю присваивается значение 0 или 1. Существуют различные методы бинаризации, которые можно условно разделить на две группы – глобальные и локальные. В первом случае величина порога остается неизменной в течение всего процесса бинаризации. Во втором изображение разбивается на области, в каждой из которых вычисляется локальный порог. Главная цель бинаризации, это радикальное уменьшение количества информации, с которой приходится работать. Просто говоря, удачная бинаризация сильно упрощает последующую работу с изображением. С другой стороны, неудачи в процессе бинаризации могут привети к искажениям, таким, как разрывы в линиях, потеря значащих деталей, нарушение целостности объектов, появление шума и непредсказуемое искажение символов из-за неоднородностей фона. Различные методы бинаризации имеют свои слабые места: так, например, метод Оцу может приводить к утрате мелких деталей и „слипанию“ близлежащих символов, а метод Ниблэка грешит появлением ложных объектов в случае неоднородностей фона с низкой контрастностью. Отсюда следует, что каждый метод должен быть применен в своей области. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278435/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 12:30:02
Этот пост я хочу посвятить приятному трофею, добытому в англоязычном интернете. Речь пойдет об одном из методов адаптивной бинаризации изображений, методе Брэдли (или Брэдли-Рота, поскольку авторов двое).
#### Немного теории
Процесс бинаризации – это перевод цветного (или в градациях серого) изображения в двухцветное черно-белое. Главным параметром такого преобразования является порог t – значение, с которым сравнивается яркость каждого пикселя. По результатам сравнения, пикселю присваивается значение 0 или 1. Существуют различные методы бинаризации, которые можно условно разделить на две группы – глобальные и локальные. В первом случае величина порога остается неизменной в течение всего процесса бинаризации. Во втором изображение разбивается на области, в каждой из которых вычисляется локальный порог. Главная цель бинаризации, это радикальное уменьшение количества информации, с которой приходится работать. Просто говоря, удачная бинаризация сильно упрощает последующую работу с изображением. С другой стороны, неудачи в процессе бинаризации могут привети к искажениям, таким, как разрывы в линиях, потеря значащих деталей, нарушение целостности объектов, появление шума и непредсказуемое искажение символов из-за неоднородностей фона. Различные методы бинаризации имеют свои слабые места: так, например, метод Оцу может приводить к утрате мелких деталей и „слипанию“ близлежащих символов, а метод Ниблэка грешит появлением ложных объектов в случае неоднородностей фона с низкой контрастностью. Отсюда следует, что каждый метод должен быть применен в своей области. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278435/#habracut
[>]
[Из песочницы] Pomp — метафреймворк для парсинга сайтов
habra.16
habrabot(difrex,1) — All
2016-03-03 14:30:02
С поддержкой asyncio и вдохновленный [Scrapy][1].
#### Зачем еще один?
В первую очередь как инструмент для сбора данных, применяемый в моем хобби проекте, который не давил бы своей мощью, сложностью и наследием. И да, кто же будет сознательно начинать что-то новое на python2.x? В итоге появилось идея сделать простой фреймворк для современной экосистемы python3.x, но такой же элегантный как Scrapy. Под катом обзорная статья о [Pomp][2] в стиле FAQ. [Читать дальше →][3]
[1]: http://scrapy.org/
[2]: https://bitbucket.org/estin/pomp
[3]: https://habrahabr.ru/post/278445/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 14:30:02
С поддержкой asyncio и вдохновленный [Scrapy][1].
#### Зачем еще один?
В первую очередь как инструмент для сбора данных, применяемый в моем хобби проекте, который не давил бы своей мощью, сложностью и наследием. И да, кто же будет сознательно начинать что-то новое на python2.x? В итоге появилось идея сделать простой фреймворк для современной экосистемы python3.x, но такой же элегантный как Scrapy. Под катом обзорная статья о [Pomp][2] в стиле FAQ. [Читать дальше →][3]
[1]: http://scrapy.org/
[2]: https://bitbucket.org/estin/pomp
[3]: https://habrahabr.ru/post/278445/#habracut
[>]
Чем плохо быть full stack разработчиком
habra.16
habrabot(difrex,1) — All
2016-03-03 15:00:04
# Введение
Прежде всего определимся с терминами. Есть много разных представлений о том, кто же такой full stack разработчик, кто-то даже вполне обоснованно считает, что [такие разработчики — это миф][1], но в этой статье будет иметься в виду разработчик, который обладает знаниями и умениями, позволяющими с нуля написать некий софт и вывести его в продакшн. При этом софт может быть рассчитан на web платформу, мобильные приложения или десктопные. Идеальный full stack разработчик — это тот, кто владеет в какой-то мере всеми платформами и может разработать и установить на них свой софт. Но это действительно скорее миф.
Возможно, по заголовку кому-то покажется, что это жалобный пост, который говорит о том, как плохо живётся неквалифицированному школьнику, который похватал всего из разных статей в интернете. Нет, пост не жалобный, мы говорим про full stack, а не full slack, и в конце будет так же рассмотрен список плюсов. И мы будем рассматривать не школьника, а разработчика с опытом работы в пять и более лет. Просто посмотрим, какие минусы есть в таком развитии. [Читать дальше →][2]
[1]: https://habrahabr.ru/company/Voximplant/blog/275229/
[2]: https://habrahabr.ru/post/278467/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 15:00:04
# Введение
Прежде всего определимся с терминами. Есть много разных представлений о том, кто же такой full stack разработчик, кто-то даже вполне обоснованно считает, что [такие разработчики — это миф][1], но в этой статье будет иметься в виду разработчик, который обладает знаниями и умениями, позволяющими с нуля написать некий софт и вывести его в продакшн. При этом софт может быть рассчитан на web платформу, мобильные приложения или десктопные. Идеальный full stack разработчик — это тот, кто владеет в какой-то мере всеми платформами и может разработать и установить на них свой софт. Но это действительно скорее миф.
Возможно, по заголовку кому-то покажется, что это жалобный пост, который говорит о том, как плохо живётся неквалифицированному школьнику, который похватал всего из разных статей в интернете. Нет, пост не жалобный, мы говорим про full stack, а не full slack, и в конце будет так же рассмотрен список плюсов. И мы будем рассматривать не школьника, а разработчика с опытом работы в пять и более лет. Просто посмотрим, какие минусы есть в таком развитии. [Читать дальше →][2]
[1]: https://habrahabr.ru/company/Voximplant/blog/275229/
[2]: https://habrahabr.ru/post/278467/#habracut
[>]
Практическая подготовка в области ИБ: Корпоративные лаборатории 2016, перезагрузка
habra.16
habrabot(difrex,1) — All
2016-03-03 15:00:04
![][1] Начну с короткого анекдота, который довольно хорошо можно спроецировать на тему ИБ:
> — А объявления в газетах дают результаты?
>
>
>
> — Конечно! В понедельник вышло объявление о том, что мы ищем сторожа, а уже в среду нас обокрали.
_«Чтобы защититься от хакеров, нужно уметь думать и действовать, как хакер. Иначе невозможно понять, что является уязвимостью, которая сможет помочь злоумышленнику преодолеть ваши системы защиты, а что — нет»._ В середине 2014 года мы запустили первые «Корпоративные лаборатории», суть которых заключалась в предоставлении наиболее актуальных знаний в области практической информационной безопасности: методология, методы, инструменты поиска уязвимостей, а также выработка наиболее эффективных мер противодействия. За полтора года программа существенно обновилась и дополнилась «хардкорным» материалом в виде модуля «Эксперт». С новыми тарифами можно ознакомиться на [сайте][2]. Мы решили опубликовать часть устаревших записей «Корпоративных лабораторий» модуля «Стандарт» (модуль, по своей сути, представляет собой введение в программу). Обратите внимание, вебинары (теоретическая подготовка) составляют только 20% программы, остальные 80% — практическая подготовка в лабораториях, максимально приближенных по своему составу к корпоративным сетям реальных компаний. [Читать дальше →][3]
[1]: https://habrastorage.org/files/be6/8c7/908/be68c79085b1445a83682af75ebfe2ef.png
[2]: https://www.pentestit.ru/labs/corp-lab
[3]: https://habrahabr.ru/post/278231/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 15:00:04
![][1] Начну с короткого анекдота, который довольно хорошо можно спроецировать на тему ИБ:
> — А объявления в газетах дают результаты?
>
>
>
> — Конечно! В понедельник вышло объявление о том, что мы ищем сторожа, а уже в среду нас обокрали.
_«Чтобы защититься от хакеров, нужно уметь думать и действовать, как хакер. Иначе невозможно понять, что является уязвимостью, которая сможет помочь злоумышленнику преодолеть ваши системы защиты, а что — нет»._ В середине 2014 года мы запустили первые «Корпоративные лаборатории», суть которых заключалась в предоставлении наиболее актуальных знаний в области практической информационной безопасности: методология, методы, инструменты поиска уязвимостей, а также выработка наиболее эффективных мер противодействия. За полтора года программа существенно обновилась и дополнилась «хардкорным» материалом в виде модуля «Эксперт». С новыми тарифами можно ознакомиться на [сайте][2]. Мы решили опубликовать часть устаревших записей «Корпоративных лабораторий» модуля «Стандарт» (модуль, по своей сути, представляет собой введение в программу). Обратите внимание, вебинары (теоретическая подготовка) составляют только 20% программы, остальные 80% — практическая подготовка в лабораториях, максимально приближенных по своему составу к корпоративным сетям реальных компаний. [Читать дальше →][3]
[1]: https://habrastorage.org/files/be6/8c7/908/be68c79085b1445a83682af75ebfe2ef.png
{kind=link}
[2]: https://www.pentestit.ru/labs/corp-lab
[3]: https://habrahabr.ru/post/278231/#habracut
[>]
Грэйс «бабуля COBOL» Хоппер
habra.16
habrabot(difrex,1) — All
2016-03-03 17:00:03
_«Она истинный морпех, но если копнуть глубже, мы найдем пирата.»_ [![][1]][2] Грейс Хоппер ([Grace Hopper][3]) — американская учёная и контр-адмирал флота США. Программист гарвардского компьютера Марк I.
* В детстве разобрала 7 будильников, чтобы понять, как все устроено.
* Боролась за идею машинонезависимого языка программирования.
* Разработала первый компилятор.
* Приложила руку к распространению мема «дебаггинг» (выловив настоящего жука из Mark 2).
* Могла объяснить сообразительным военным, что такое «наносекунда» и «пикосекунда». На пальцах.
* В её честь назвали [эсминец USS Hopper (DDG-70)][4].
* И суперкомпьютер Cray XE6 «Hopper».
* И в ее честь [именная премия][5] Ассоциациеи вычислительной техники ([ACM][6]) — присуждается молодому (до 35 лет) специалисту, сделавшему значительный вклад в области вычислительной техники.
Построив успешную карьеру математика в Йеле (защитив докторскую и став профессором), Грэйс Хоппер в 1943 (37 лет) пошла добровольцем во Флот. Но у нее был недобор по весу 6 кг, поэтому пришлось сесть «за клавиатуру» Гарвардского Mark 1. [![][7]][8] [Читать дальше →][9]
[1]: https://habrastorage.org/files/a8e/d50/b91/a8ed50b91bbc43bbbcd2f4dc18851396.jpg
[2]: https://habrahabr.ru/post/278399/
[3]: https://en.wikipedia.org/wiki/Grace_Hopper
[4]: https://en.wikipedia.org/wiki/USS_Hopper_(DDG-70)
[5]: https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%BC%D0%B8%D1%8F_%D0%B8%D0%BC%D0%B5%D0%BD%D0%B8_%D0%93%D1%80%D0%B5%D0%B9%D1%81_%D0%9C%D1%8E%D1%80%D1%80%D0%B5%D0%B9_%D0%A5%D0%BE%D0%BF%D0%BF%D0%B5%D1%80
[6]: https://ru.wikipedia.org/wiki/ACM
[7]: https://habrastorage.org/files/51e/8d5/41d/51e8d541de0b475c9ea076c4532d765a.jpg
[8]: https://habrahabr.ru/post/278399/
[9]: https://habrahabr.ru/post/278399/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 17:00:03
_«Она истинный морпех, но если копнуть глубже, мы найдем пирата.»_ [![][1]][2] Грейс Хоппер ([Grace Hopper][3]) — американская учёная и контр-адмирал флота США. Программист гарвардского компьютера Марк I.
* В детстве разобрала 7 будильников, чтобы понять, как все устроено.
* Боролась за идею машинонезависимого языка программирования.
* Разработала первый компилятор.
* Приложила руку к распространению мема «дебаггинг» (выловив настоящего жука из Mark 2).
* Могла объяснить сообразительным военным, что такое «наносекунда» и «пикосекунда». На пальцах.
* В её честь назвали [эсминец USS Hopper (DDG-70)][4].
* И суперкомпьютер Cray XE6 «Hopper».
* И в ее честь [именная премия][5] Ассоциациеи вычислительной техники ([ACM][6]) — присуждается молодому (до 35 лет) специалисту, сделавшему значительный вклад в области вычислительной техники.
Построив успешную карьеру математика в Йеле (защитив докторскую и став профессором), Грэйс Хоппер в 1943 (37 лет) пошла добровольцем во Флот. Но у нее был недобор по весу 6 кг, поэтому пришлось сесть «за клавиатуру» Гарвардского Mark 1. [![][7]][8] [Читать дальше →][9]
[1]: https://habrastorage.org/files/a8e/d50/b91/a8ed50b91bbc43bbbcd2f4dc18851396.jpg
{kind=link}
[2]: https://habrahabr.ru/post/278399/
[3]: https://en.wikipedia.org/wiki/Grace_Hopper
[4]: https://en.wikipedia.org/wiki/USS_Hopper_(DDG-70)
[5]: https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%BC%D0%B8%D1%8F_%D0%B8%D0%BC%D0%B5%D0%BD%D0%B8_%D0%93%D1%80%D0%B5%D0%B9%D1%81_%D0%9C%D1%8E%D1%80%D1%80%D0%B5%D0%B9_%D0%A5%D0%BE%D0%BF%D0%BF%D0%B5%D1%80
[6]: https://ru.wikipedia.org/wiki/ACM
[7]: https://habrastorage.org/files/51e/8d5/41d/51e8d541de0b475c9ea076c4532d765a.jpg
{kind=link}
[8]: https://habrahabr.ru/post/278399/
[9]: https://habrahabr.ru/post/278399/#habracut
[>]
Теория и практика парсинга исходников с помощью ANTLR и Roslyn
habra.16
habrabot(difrex,1) — All
2016-03-03 19:00:05
В нашем проекте [PT Application Inspector][1] реализовано несколько подходов к анализу исходного кода на различных языках программирования:
* поиск по сигнатурам;
* исследование свойств математических моделей, полученных в результате статической абстрактной интерпретации кода;
* динамический анализ развернутого приложения и верификация на нем результатов статического анализа.
Наш цикл статей посвящен структуре и принципам работы модуля сигнатурного поиска (PM, pattern matching). Преимущества такого анализатора — скорость работы, простота описания шаблонов и масштабируемость на другие языки. Среди недостатков можно выделить то, что модуль не в состоянии анализировать сложные уязвимости, требующие построения высокоуровневых моделей выполнения кода. [![][2]][3] К разрабатываемому модулю были, в числе прочих, сформулированы следующие требования:
* поддержка нескольких языков программирования и простое добавление новых;
* поддержка анализа кода, содержащего синтаксические и семантические ошибки;
* возможность описания шаблонов на универсальном языке (DSL, domain specific language).
В нашем случае все шаблоны описывают какие-либо уязвимости или недостатки в исходном коде. Весь процесс анализа кода может быть разбит на следующие этапы:
1. парсинг в зависимое от языка представление (abstract syntax tree, AST);
2. преобразование AST в независимый от языка унифицированный формат;
3. непосредственное сопоставление с шаблонами, описанными на DSL.
Данная статья посвящена первому этапу, а именно: парсингу, сравнению функциональных возможностей и особенностей различных парсеров, применению теории на практике на примере грамматик Java, PHP, PLSQL, TSQL и даже C#. Остальные этапы будут рассмотрены в следующих публикациях. [Читать дальше →][4]
[1]: http://www.ptsecurity.ru/appsecurity/application-inspector/
[2]: https://habrastorage.org/files/879/56c/123/87956c123b5248f58393586831153cd4.png
[3]: https://habrahabr.ru/post/210772/
[4]: https://habrahabr.ru/post/210772/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 19:00:05
В нашем проекте [PT Application Inspector][1] реализовано несколько подходов к анализу исходного кода на различных языках программирования:
* поиск по сигнатурам;
* исследование свойств математических моделей, полученных в результате статической абстрактной интерпретации кода;
* динамический анализ развернутого приложения и верификация на нем результатов статического анализа.
Наш цикл статей посвящен структуре и принципам работы модуля сигнатурного поиска (PM, pattern matching). Преимущества такого анализатора — скорость работы, простота описания шаблонов и масштабируемость на другие языки. Среди недостатков можно выделить то, что модуль не в состоянии анализировать сложные уязвимости, требующие построения высокоуровневых моделей выполнения кода. [![][2]][3] К разрабатываемому модулю были, в числе прочих, сформулированы следующие требования:
* поддержка нескольких языков программирования и простое добавление новых;
* поддержка анализа кода, содержащего синтаксические и семантические ошибки;
* возможность описания шаблонов на универсальном языке (DSL, domain specific language).
В нашем случае все шаблоны описывают какие-либо уязвимости или недостатки в исходном коде. Весь процесс анализа кода может быть разбит на следующие этапы:
1. парсинг в зависимое от языка представление (abstract syntax tree, AST);
2. преобразование AST в независимый от языка унифицированный формат;
3. непосредственное сопоставление с шаблонами, описанными на DSL.
Данная статья посвящена первому этапу, а именно: парсингу, сравнению функциональных возможностей и особенностей различных парсеров, применению теории на практике на примере грамматик Java, PHP, PLSQL, TSQL и даже C#. Остальные этапы будут рассмотрены в следующих публикациях. [Читать дальше →][4]
[1]: http://www.ptsecurity.ru/appsecurity/application-inspector/
[2]: https://habrastorage.org/files/879/56c/123/87956c123b5248f58393586831153cd4.png
{kind=link}
[3]: https://habrahabr.ru/post/210772/
[4]: https://habrahabr.ru/post/210772/#habracut
[>]
Снова про STL: контейнеры
habra.16
habrabot(difrex,1) — All
2016-03-03 19:00:05
В [предыдущей заметке][1] речь шла о массивах как прототипе и прародителе контейнеров. Теперь дошла очередь до собственно контейнерных классов и поддерживающих их библиотек. Под термином библиотека стандартных шаблонов (STL, **S**tandard **T**emplate **L**ibrary) понимают набор интерфейсов и компонентов, первоначально разработанных Александром Степановым, Менгом Ли и другими сотрудниками AT&T Bell Laboratories и Hewlett-Packard Research Laboratories в начале 90-х годов (хотя и позже ещё весьма многие приложили руку к тому, что стало на сегодня стандартным компонентом C++). Далее библиотека STL перешла в собственность компании SGI, а также была включена как компонент в набор библиотек Boost. И наконец библиотека STL вошла в стандарты C++ 1998 и 2003 годов (ISO/IEC 14882:1998 и ISO/IEC 14882:2003) и с тех пор считается одной из составных частей стандартной библиотек C++. Стандарт не называет эту часть библиотеки STL, но эту хронологию хорошо бы учитывать, разбираясь с какой версией компилятора, языка и литературы вы имеете дело — в процессе сокращения HP STL до размеров, подходящих для стандартизации, часть алгоритмов и функторов выпали из состава библиотеки, а кое-что, со временем, и добавляется (например, расширение набора переопределенных прототипов некоторых методов контейнеров). По тексту будет использоваться традиционное название STL только чтобы было ясно какую часть стандартной библиотеки C++ мы имеем в виду. [Читать дальше →][2]
[1]: https://habrahabr.ru/company/ua-hosting/blog/278039/
[2]: https://habrahabr.ru/post/278369/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 19:00:05
В [предыдущей заметке][1] речь шла о массивах как прототипе и прародителе контейнеров. Теперь дошла очередь до собственно контейнерных классов и поддерживающих их библиотек. Под термином библиотека стандартных шаблонов (STL, **S**tandard **T**emplate **L**ibrary) понимают набор интерфейсов и компонентов, первоначально разработанных Александром Степановым, Менгом Ли и другими сотрудниками AT&T Bell Laboratories и Hewlett-Packard Research Laboratories в начале 90-х годов (хотя и позже ещё весьма многие приложили руку к тому, что стало на сегодня стандартным компонентом C++). Далее библиотека STL перешла в собственность компании SGI, а также была включена как компонент в набор библиотек Boost. И наконец библиотека STL вошла в стандарты C++ 1998 и 2003 годов (ISO/IEC 14882:1998 и ISO/IEC 14882:2003) и с тех пор считается одной из составных частей стандартной библиотек C++. Стандарт не называет эту часть библиотеки STL, но эту хронологию хорошо бы учитывать, разбираясь с какой версией компилятора, языка и литературы вы имеете дело — в процессе сокращения HP STL до размеров, подходящих для стандартизации, часть алгоритмов и функторов выпали из состава библиотеки, а кое-что, со временем, и добавляется (например, расширение набора переопределенных прототипов некоторых методов контейнеров). По тексту будет использоваться традиционное название STL только чтобы было ясно какую часть стандартной библиотеки C++ мы имеем в виду. [Читать дальше →][2]
[1]: https://habrahabr.ru/company/ua-hosting/blog/278039/
[2]: https://habrahabr.ru/post/278369/#habracut
[>]
Защита на всех стадиях кибератак
habra.16
habrabot(difrex,1) — All
2016-03-03 19:00:05
Решения HPE позволяют выстроить комплексную систему обороны от кибератак, в том числе осуществляемых с использованием принципиально новых способов проникновения в корпоративные системы. [][1]
Кибератаки становятся все более массовыми и изощренными. Одной из ключевых причин массовости кибератак становится их ценовая доступность. Так, например, в опубликованном в октябре 2015 года отчете об исследовании _«2015 Cost of Cyber Crime Study: Global»_, проведенном компанией Ponemon Institute при спонсорской поддержке HPE, средняя стоимость одного киберпреступления в России оценивается всего в 100-150 руб., в долларовом исчислении она снизилась с 3,33 долл. в 2014 году до 2,37 долл. в 2015-м. [Читать дальше →][2]
[1]: https://habrahabr.ru/company/hpe/blog/278465/
[2]: https://habrahabr.ru/post/278465/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 19:00:05
Решения HPE позволяют выстроить комплексную систему обороны от кибератак, в том числе осуществляемых с использованием принципиально новых способов проникновения в корпоративные системы. [][1]
Кибератаки становятся все более массовыми и изощренными. Одной из ключевых причин массовости кибератак становится их ценовая доступность. Так, например, в опубликованном в октябре 2015 года отчете об исследовании _«2015 Cost of Cyber Crime Study: Global»_, проведенном компанией Ponemon Institute при спонсорской поддержке HPE, средняя стоимость одного киберпреступления в России оценивается всего в 100-150 руб., в долларовом исчислении она снизилась с 3,33 долл. в 2014 году до 2,37 долл. в 2015-м. [Читать дальше →][2]
[1]: https://habrahabr.ru/company/hpe/blog/278465/
[2]: https://habrahabr.ru/post/278465/#habracut
[>]
Антивирусный бот для Telegram
habra.16
habrabot(difrex,1) — All
2016-03-03 19:00:05
На прошлой неделе «Доктор Веб» выпустил антивирусного бота для Telegram. Я, как непосредственный участник этого проекта, хотел бы от лица всей команды рассказать о том, зачем мы сделали этого бота, как он работает и пора ли уже отказываться от настольного антивируса. ![][1] [Ссылка не содержит угроз][2]
[1]: https://habrastorage.org/files/238/a84/cdb/238a84cdb6924620952986ce333e6a75.png
[2]: https://habrahabr.ru/post/278497/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 19:00:05
На прошлой неделе «Доктор Веб» выпустил антивирусного бота для Telegram. Я, как непосредственный участник этого проекта, хотел бы от лица всей команды рассказать о том, зачем мы сделали этого бота, как он работает и пора ли уже отказываться от настольного антивируса. ![][1] [Ссылка не содержит угроз][2]
[1]: https://habrastorage.org/files/238/a84/cdb/238a84cdb6924620952986ce333e6a75.png
{kind=link}
[2]: https://habrahabr.ru/post/278497/#habracut
[>]
Шустрый потокобезопасный менеджер кучи и голый Си
habra.16
habrabot(difrex,1) — All
2016-03-03 21:00:02
При планировании любой задачи мы стремимся как можно точнее конкретизировать запросы, определить исходные данные и по возможности избавиться от любой неопределенности, мешающей просчитать конечный результат. Однако при разработке высокоуровневой логики не всегда уделяется внимание таким простым казалось бы вещам, как размещение данных в памяти, менеджмент потоков, обрабатывающих наш функционал, особенности реализации динамических массивов или бинарный интерфейс процедур. Когда написанная программа предельно лаконична и оптимизирована, но при этом работает не так быстро, как хотелось бы, закономерно возникает вопрос: «а что еще можно улучшить?» Насколько можно доверять низкоуровневому инструментарию, написанному профессиональными программистами, безусловно разбирающимися в своем деле, но при этом ни черта не понимающими в тех идеях, что вы хотите реализовать? Фрагментация, зацикленность, прерывания, события, объекты, уведомления, каждое новое знакомство с Си-шными или WinAPI-шными библиотеками подталкивает к очевидной мысли: «зачем такая громоздкая реализация?» Почему нельзя просто сделать менеджер кучи выделяющий память за строгое количество шагов? Использовать real-time статистику при работе с разделяемыми данными, вместо сложной системы семафоров и уведомлений? Наращивать динамические массивы без переразмещения и обращаться к случайной ячейке за одинаковое время после любого количества реформаций? Миссия не кажется невыполнимой. Осталось только попробовать. Предлагаю широкому вниманию процедурную реализацию менеджера кучи, способного выделять диапазоны памяти заказных размеров. Цикл поиска при этом не превышает нормированных пределов. Работа с памятью состоит всего из двух процедур: memAlloc и memRecycle, выполняющих связанные функции. Потокобезопасность поддерживается с помощью дополнительного инструментария, в свою очередь состоящего еще из нескольких процедур. О распараллеливании немного поподробнее: принцип базируется на ассоциированной блокировке разделяемых данных, схожих с блокировкой шины методами Interlocked, однако без блокировки шины. Весь процесс сводится к созданию позиционных стопоров, являющихся по сути диапазонами памяти, содержащими однобайтовые метки состояний каждого из потоков в доступном пуле. Размер выводится из этого соотношения. Поскольку я использую восьмипотоковый пул (а больше мне не нужно), то позиционные стопоры у меня занимают 8 байт (64 бита). Перед перезаписью разделяемой информации стопор блокируется исполняющим потоком, записывая метку в байт под смещением своего номера в пуле. Другие потоки не будут работать с разделяемыми данными пока стопор не обнулится, выполняя Sleep, либо откладывая задачу, либо считая овечек в цикле, на выбор программиста. Клоны Interlocked процедур — threadExchange, threadCompareExchange и threadIncrement выполняют те же функции, что и оригиналы. Однако при работе внутри потока из пула не блокируют шину. Вместо этого используется ассемблерная процедура, задача которой сводится к двухступенчатой проверке стопора и установке собственной метки (стоит отметить, что при работе вне пула, в потоке не имеющим номера, все же используется блокировка шины). Ее реализация ниже: [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278509/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 21:00:02
При планировании любой задачи мы стремимся как можно точнее конкретизировать запросы, определить исходные данные и по возможности избавиться от любой неопределенности, мешающей просчитать конечный результат. Однако при разработке высокоуровневой логики не всегда уделяется внимание таким простым казалось бы вещам, как размещение данных в памяти, менеджмент потоков, обрабатывающих наш функционал, особенности реализации динамических массивов или бинарный интерфейс процедур. Когда написанная программа предельно лаконична и оптимизирована, но при этом работает не так быстро, как хотелось бы, закономерно возникает вопрос: «а что еще можно улучшить?» Насколько можно доверять низкоуровневому инструментарию, написанному профессиональными программистами, безусловно разбирающимися в своем деле, но при этом ни черта не понимающими в тех идеях, что вы хотите реализовать? Фрагментация, зацикленность, прерывания, события, объекты, уведомления, каждое новое знакомство с Си-шными или WinAPI-шными библиотеками подталкивает к очевидной мысли: «зачем такая громоздкая реализация?» Почему нельзя просто сделать менеджер кучи выделяющий память за строгое количество шагов? Использовать real-time статистику при работе с разделяемыми данными, вместо сложной системы семафоров и уведомлений? Наращивать динамические массивы без переразмещения и обращаться к случайной ячейке за одинаковое время после любого количества реформаций? Миссия не кажется невыполнимой. Осталось только попробовать. Предлагаю широкому вниманию процедурную реализацию менеджера кучи, способного выделять диапазоны памяти заказных размеров. Цикл поиска при этом не превышает нормированных пределов. Работа с памятью состоит всего из двух процедур: memAlloc и memRecycle, выполняющих связанные функции. Потокобезопасность поддерживается с помощью дополнительного инструментария, в свою очередь состоящего еще из нескольких процедур. О распараллеливании немного поподробнее: принцип базируется на ассоциированной блокировке разделяемых данных, схожих с блокировкой шины методами Interlocked, однако без блокировки шины. Весь процесс сводится к созданию позиционных стопоров, являющихся по сути диапазонами памяти, содержащими однобайтовые метки состояний каждого из потоков в доступном пуле. Размер выводится из этого соотношения. Поскольку я использую восьмипотоковый пул (а больше мне не нужно), то позиционные стопоры у меня занимают 8 байт (64 бита). Перед перезаписью разделяемой информации стопор блокируется исполняющим потоком, записывая метку в байт под смещением своего номера в пуле. Другие потоки не будут работать с разделяемыми данными пока стопор не обнулится, выполняя Sleep, либо откладывая задачу, либо считая овечек в цикле, на выбор программиста. Клоны Interlocked процедур — threadExchange, threadCompareExchange и threadIncrement выполняют те же функции, что и оригиналы. Однако при работе внутри потока из пула не блокируют шину. Вместо этого используется ассемблерная процедура, задача которой сводится к двухступенчатой проверке стопора и установке собственной метки (стоит отметить, что при работе вне пула, в потоке не имеющим номера, все же используется блокировка шины). Ее реализация ниже: [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278509/#habracut
[>]
Обзор примитивов синхронизации
habra.16
habrabot(difrex,1) — All
2016-03-03 22:30:03
Синхронизация нужна в любой малтитредной программе. (Если, конечно, она не состоит из локлесс алгоритмов на 100%, что вряд ли). Будь то приложение или компонента ядра современной операционной системы. Меня всё нижесказанное, конечно, больше волнует с точки зрения разработки ядра ОС. Но почти всё применимо и к пользовательскому коду. Кстати, ядра старых ОС в примитивах синхронизации не нуждались, поскольку преемптивной мультизадачности внутри ядра в старые добрые времена не было. (Уж за Юникс 7-й версии я отвечаю. Не было.) Точнее, единственным методом синхронизации был запрет прерываний. Но об этом позже. Сначала перечислим героев. Мне известны следующие примитивы синхронизации: User/kernel mode: mutex+cond, sema, enter/leave critical section. Kernel only: spinlock, управление прерываниями. Зачем всё это нужно, читатель, наверное, знает, но всё же уточним. Если некоторая структура данных может быть доступна двум параллельно работающим нитям (или нити и прерыванию), и являет собой сущность, к которой нельзя обеспечить атомарный доступ, то работу с такой структурой нужно производить так, чтобы только одна нить одновременно выполняла сложные манипуляции состоянием структуры. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278413/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-03 22:30:03
Синхронизация нужна в любой малтитредной программе. (Если, конечно, она не состоит из локлесс алгоритмов на 100%, что вряд ли). Будь то приложение или компонента ядра современной операционной системы. Меня всё нижесказанное, конечно, больше волнует с точки зрения разработки ядра ОС. Но почти всё применимо и к пользовательскому коду. Кстати, ядра старых ОС в примитивах синхронизации не нуждались, поскольку преемптивной мультизадачности внутри ядра в старые добрые времена не было. (Уж за Юникс 7-й версии я отвечаю. Не было.) Точнее, единственным методом синхронизации был запрет прерываний. Но об этом позже. Сначала перечислим героев. Мне известны следующие примитивы синхронизации: User/kernel mode: mutex+cond, sema, enter/leave critical section. Kernel only: spinlock, управление прерываниями. Зачем всё это нужно, читатель, наверное, знает, но всё же уточним. Если некоторая структура данных может быть доступна двум параллельно работающим нитям (или нити и прерыванию), и являет собой сущность, к которой нельзя обеспечить атомарный доступ, то работу с такой структурой нужно производить так, чтобы только одна нить одновременно выполняла сложные манипуляции состоянием структуры. [Читать дальше →][1]
[1]: https://habrahabr.ru/post/278413/#habracut
[>]
Видеоаналитика 2.0 или при чём тут оставленные предметы. Часть 1
habra.16
habrabot(difrex,1) — All
2016-03-04 08:00:02
![image][1] Какие мысли у вас возникают, когда вы слышите понятие «Видеоаналитика 2.0»? Решение каких актуальных задач можно было бы поручить гипотетическим технологиям видеоанализа следующего поколения? Среди популярных ответов наверняка встретятся «некооперативное распознавание личности человека среди идущей толпы с вероятностью, близкой к 100%», «выявление злоумышленников среди посетителей», “межкамерное одновременное сопровождение множества объектов без срыва трекинга”, “распознавание и классификация без ошибок всего, что видно в кадре”. Инженер, связанный с инсталляциями систем безопасности пожелает максимальной автоматизации настройки детекторов за счет продвинутых алгоритмов самообучения, что позволит существенно снизить затраты на пуско-наладку и гарантийное обслуживание. А кто-то скажет, что видеоаналитика 2.0 возможна только при наличии искусственного интеллекта, что на текущем уровне развития технологий невозможно. Поэтому нам ничего не остается, кроме как наблюдать за лидерами рынка аналитики, которые и так выжимают максимально возможное из имеющихся вычислительных ресурсов и ждать массового внедрения квантовых компьютеров. Надеясь, что оно все же произойдет. [Читать дальше →][2]
[1]: https://habrastorage.org/files/406/0b1/55f/4060b155f7404cf783feb581c8a4993b.PNG
[2]: https://habrahabr.ru/post/278383/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 08:00:02
![image][1] Какие мысли у вас возникают, когда вы слышите понятие «Видеоаналитика 2.0»? Решение каких актуальных задач можно было бы поручить гипотетическим технологиям видеоанализа следующего поколения? Среди популярных ответов наверняка встретятся «некооперативное распознавание личности человека среди идущей толпы с вероятностью, близкой к 100%», «выявление злоумышленников среди посетителей», “межкамерное одновременное сопровождение множества объектов без срыва трекинга”, “распознавание и классификация без ошибок всего, что видно в кадре”. Инженер, связанный с инсталляциями систем безопасности пожелает максимальной автоматизации настройки детекторов за счет продвинутых алгоритмов самообучения, что позволит существенно снизить затраты на пуско-наладку и гарантийное обслуживание. А кто-то скажет, что видеоаналитика 2.0 возможна только при наличии искусственного интеллекта, что на текущем уровне развития технологий невозможно. Поэтому нам ничего не остается, кроме как наблюдать за лидерами рынка аналитики, которые и так выжимают максимально возможное из имеющихся вычислительных ресурсов и ждать массового внедрения квантовых компьютеров. Надеясь, что оно все же произойдет. [Читать дальше →][2]
[1]: https://habrastorage.org/files/406/0b1/55f/4060b155f7404cf783feb581c8a4993b.PNG
{kind=link}
[2]: https://habrahabr.ru/post/278383/#habracut
[>]
Первый хакатон 2ГИС
habra.16
habrabot(difrex,1) — All
2016-03-04 11:30:02
![][1] На прошлых выходных мы организовали в новосибирском офисе 2ГИС первый открытый хакатон. Не будем рассказывать, как было круто, какие классные проекты выиграли и вот это всё. Мы поделимся некоторыми советами для организаторов подобных мероприятий и зададим пару вопросов. [Как всё было][2]
[1]: https://habrastorage.org/files/7c4/6eb/92b/7c46eb92bcac4ecea040028280ef5776.jpg
[2]: https://habrahabr.ru/post/278431/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 11:30:02
![][1] На прошлых выходных мы организовали в новосибирском офисе 2ГИС первый открытый хакатон. Не будем рассказывать, как было круто, какие классные проекты выиграли и вот это всё. Мы поделимся некоторыми советами для организаторов подобных мероприятий и зададим пару вопросов. [Как всё было][2]
[1]: https://habrastorage.org/files/7c4/6eb/92b/7c46eb92bcac4ecea040028280ef5776.jpg
{kind=link}
[2]: https://habrahabr.ru/post/278431/#habracut
[>]
Безопасность прошивок на примере подсистемы Intel Management Engine
habra.16
habrabot(difrex,1) — All
2016-03-04 11:30:02
![][1] В [предыдущей статье][2] был описан ход исследования безопасности прошивок промышленных коммутаторов. Мы показали, что обнаруженные архитектурные недостатки позволяют легко подделывать образы прошивок, обновлять ими свитчи и исполнять свой код на них (а в некоторых случаях — и на подключающихся к свитчам клиентах). В дополнение, мы описали возможности закрепления внедряемого кода на устройствах. Подчеркнули низкое качество кода прошивок и отсутствие механизмов защиты от эксплуатации бинарных уязвимостей. Мы обещали привести реальный пример сильной модели безопасности прошивок, где модификация исполнимого кода является очень нетривиальной задачей для потенциального злоумышленника. Встречайте – **подсистема Intel Management Engine**, самая загадочная составляющая архитектуры современных x86-платформ. [Читать дальше →][3]
[1]: https://habrastorage.org/files/f91/dfa/3e8/f91dfa3e858848589dd9cd7e56afd868.png
[2]: https://habrahabr.ru/company/dsec/blog/276345/
[3]: https://habrahabr.ru/post/278549/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 11:30:02
![][1] В [предыдущей статье][2] был описан ход исследования безопасности прошивок промышленных коммутаторов. Мы показали, что обнаруженные архитектурные недостатки позволяют легко подделывать образы прошивок, обновлять ими свитчи и исполнять свой код на них (а в некоторых случаях — и на подключающихся к свитчам клиентах). В дополнение, мы описали возможности закрепления внедряемого кода на устройствах. Подчеркнули низкое качество кода прошивок и отсутствие механизмов защиты от эксплуатации бинарных уязвимостей. Мы обещали привести реальный пример сильной модели безопасности прошивок, где модификация исполнимого кода является очень нетривиальной задачей для потенциального злоумышленника. Встречайте – **подсистема Intel Management Engine**, самая загадочная составляющая архитектуры современных x86-платформ. [Читать дальше →][3]
[1]: https://habrastorage.org/files/f91/dfa/3e8/f91dfa3e858848589dd9cd7e56afd868.png
{kind=link}
[2]: https://habrahabr.ru/company/dsec/blog/276345/
[3]: https://habrahabr.ru/post/278549/#habracut
[>]
Создание системы расстановки объектов по уровню при помощи редактора blueprint. Часть 2: добавление окна пред просмотра
habra.16
habrabot(difrex,1) — All
2016-03-04 11:30:02
![image][1] Здравствуйте, меня зовут Дмитрий. Я занимаюсь созданием компьютерных игр на Unreal Engine в качестве хобби. Итак, сегодня я продолжу создание системы расстановки объектов. После того, как я её сделал я подумал, что добавление окна пред просмотра позволит ускорить процесс расстановки объектов. Об этом я сегодня и расскажу. [Читать дальше →][2]
[1]: https://habrastorage.org/files/a3f/fae/b5e/a3ffaeb5ea41434585ff1318ba68d4a1.png
[2]: https://habrahabr.ru/post/278491/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 11:30:02
![image][1] Здравствуйте, меня зовут Дмитрий. Я занимаюсь созданием компьютерных игр на Unreal Engine в качестве хобби. Итак, сегодня я продолжу создание системы расстановки объектов. После того, как я её сделал я подумал, что добавление окна пред просмотра позволит ускорить процесс расстановки объектов. Об этом я сегодня и расскажу. [Читать дальше →][2]
[1]: https://habrastorage.org/files/a3f/fae/b5e/a3ffaeb5ea41434585ff1318ba68d4a1.png
{kind=link}
[2]: https://habrahabr.ru/post/278491/#habracut
[>]
Игра «Wappo» на FBD или минутка доброты
habra.16
habrabot(difrex,1) — All
2016-03-04 11:30:02
Приветствую всех. Данный пост будет о том, как написать очередную простейшую игрушку на языке программирования FBD (конечно данная реализация языка программирования отходит от стандартов FBD, но большинство «особых фишек» не используется, поэтому написанная программа может быть легко перенесена на классический FBD в любой системе), загрузить программу в контроллер и предаться воспоминаниям о начале двухтысячных. Недавно с одним из коллег зашел разговор про начало двухтысячных, и почему-то вспомнились первые наши мобильные телефоны Siemens и игра Wappo. В итоге сама собой родилась идея написать эту игрушку использую средства проектирования ПТК «Квинт 7». Т.к. больших усилий и кучи времени на это не требовалось, то вот результат: ![][1] На все это дело затрачено две половинки обеденных перерывов (совместно с распитием кофе) и пара часов вечером на рисование картинок в MS Paint. [Подробное описание под катом][2]
[1]: https://habrastorage.org/files/c35/f58/512/c35f58512a0f45e7a1128d586393adba.png
[2]: https://habrahabr.ru/post/278285/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 11:30:02
Приветствую всех. Данный пост будет о том, как написать очередную простейшую игрушку на языке программирования FBD (конечно данная реализация языка программирования отходит от стандартов FBD, но большинство «особых фишек» не используется, поэтому написанная программа может быть легко перенесена на классический FBD в любой системе), загрузить программу в контроллер и предаться воспоминаниям о начале двухтысячных. Недавно с одним из коллег зашел разговор про начало двухтысячных, и почему-то вспомнились первые наши мобильные телефоны Siemens и игра Wappo. В итоге сама собой родилась идея написать эту игрушку использую средства проектирования ПТК «Квинт 7». Т.к. больших усилий и кучи времени на это не требовалось, то вот результат: ![][1] На все это дело затрачено две половинки обеденных перерывов (совместно с распитием кофе) и пара часов вечером на рисование картинок в MS Paint. [Подробное описание под катом][2]
[1]: https://habrastorage.org/files/c35/f58/512/c35f58512a0f45e7a1128d586393adba.png
{kind=link}
[2]: https://habrahabr.ru/post/278285/#habracut
[>]
8 марта, мамы и программирование
habra.16
habrabot(difrex,1) — All
2016-03-04 12:00:03
Привет, Хабр! Кажется, иногда могут быть посты-исключения, а не только посты с кусками кода? Сегодня в блоге у нас именно тот случай. Посмотрите наше небольшое видео (кстати, код есть на 3-й секунде). Не забудьте поздравить маму с 8 марта и сказать ей «спасибо»!
[][1]
[1]: https://habrahabr.ru/post/278519/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 12:00:03
Привет, Хабр! Кажется, иногда могут быть посты-исключения, а не только посты с кусками кода? Сегодня в блоге у нас именно тот случай. Посмотрите наше небольшое видео (кстати, код есть на 3-й секунде). Не забудьте поздравить маму с 8 марта и сказать ей «спасибо»!
[][1]
[1]: https://habrahabr.ru/post/278519/#habracut
[>]
[Перевод] Обзор физики в играх Sonic. Части 3 и 4: прыжки и вращение
habra.16
habrabot(difrex,1) — All
2016-03-04 14:30:03
_От переводчика: части обзора имеют небольшой размер, поэтому решил переводить сразу по две. [Часть первая][1], [часть вторая][2]._ [Читать дальше →][3]
[1]: https://habrahabr.ru/post/276669/
[2]: https://habrahabr.ru/post/276849/
[3]: https://habrahabr.ru/post/278373/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 14:30:03
_От переводчика: части обзора имеют небольшой размер, поэтому решил переводить сразу по две. [Часть первая][1], [часть вторая][2]._ [Читать дальше →][3]
[1]: https://habrahabr.ru/post/276669/
[2]: https://habrahabr.ru/post/276849/
[3]: https://habrahabr.ru/post/278373/#habracut
[>]
Критическая уязвимость коммутаторов Cisco Nexus 3000 Series и 3500 Platform позволяет получить к ним удаленный доступ
habra.16
habrabot(difrex,1) — All
2016-03-04 15:00:03
[![][1]][2] В программном обеспечении коммутаторов Cisco Nexus 3000 Series и 3500 Platform, использующихся для построении инфраструктуры ЦОД, обнаружена критическая уязвимость, которая позволяет злоумышленнику получить удаленный доступ к устройству и его консоли с привилегиями root-пользователя. [Читать дальше →][3]
[1]: https://habrastorage.org/files/b2d/88e/b10/b2d88eb10fcb45f8adc38b99da2f4f08.png
[2]: https://habrahabr.ru/company/pt/blog/278569/
[3]: https://habrahabr.ru/post/278569/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 15:00:03
[![][1]][2] В программном обеспечении коммутаторов Cisco Nexus 3000 Series и 3500 Platform, использующихся для построении инфраструктуры ЦОД, обнаружена критическая уязвимость, которая позволяет злоумышленнику получить удаленный доступ к устройству и его консоли с привилегиями root-пользователя. [Читать дальше →][3]
[1]: https://habrastorage.org/files/b2d/88e/b10/b2d88eb10fcb45f8adc38b99da2f4f08.png
{kind=link}
[2]: https://habrahabr.ru/company/pt/blog/278569/
[3]: https://habrahabr.ru/post/278569/#habracut
[>]
Использование кодовой базы проекта Chromium в качестве SDK для разработки кроссплатформенных приложений
habra.16
habrabot(difrex,1) — All
2016-03-04 17:00:03
Помимо вполне понятной официальной документации ([Chromium Wiki][1]), существуют и статьи о том, как получить исходный код и собрать проект Chromium ([например][2]). Я же хотел рассказать о том, как на основе этого кода можно создавать приложения на C++, способные компилироваться и выполняться на нескольких операционных системах и архитектурах. Конечно, для этой цели уже существуют библиотеки, такие как [Qt][3] и [boost][4]. Но именно поэтому данная статья относится к разделу 'ненормальное программирование', ведь никто всерьез не рассматривает код Chromium как основу для кроссплатформенного приложения. [Читать дальше →][5]
[1]: https://www.chromium.org/developers/how-tos
[2]: https://habrahabr.ru/post/165193/
[3]: http://www.qt.io
[4]: http://www.boost.org/
[5]: https://habrahabr.ru/post/278579/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 17:00:03
Помимо вполне понятной официальной документации ([Chromium Wiki][1]), существуют и статьи о том, как получить исходный код и собрать проект Chromium ([например][2]). Я же хотел рассказать о том, как на основе этого кода можно создавать приложения на C++, способные компилироваться и выполняться на нескольких операционных системах и архитектурах. Конечно, для этой цели уже существуют библиотеки, такие как [Qt][3] и [boost][4]. Но именно поэтому данная статья относится к разделу 'ненормальное программирование', ведь никто всерьез не рассматривает код Chromium как основу для кроссплатформенного приложения. [Читать дальше →][5]
[1]: https://www.chromium.org/developers/how-tos
[2]: https://habrahabr.ru/post/165193/
[3]: http://www.qt.io
[4]: http://www.boost.org/
[5]: https://habrahabr.ru/post/278579/#habracut
[>]
Маргарет Гамильтон: «Пацаны, я вас на Луну отправлю»
habra.16
habrabot(difrex,1) — All
2016-03-04 22:30:02
_«Когда я только начинала работать в этой сфере, все это было для нас как Дикий Запад — мы были первооткрывателями неизведанных земель. Никто нас ничему не учил»_ Маргарет Гамильтон. ![][1] Это [Маргарет][2]. Она пишет код хорошо. Делайте как Маргарет. А еще:
* программист-самоучка;
* написала код для навигационного компьютера программы «Аполлон»;
* когда американцы ступили на поверхность Луны ей был 31 год;
* Маргарет **НЕ** автор термина «software engineering»;
* часто брала на работу 4х-летнюю дочку;
* дочка помогла найти баг в программе.
Под руководством Маргарет Гамильтон писались программы для бортового компьютера КА Аполлон. В один из самых ответственных моментов миссии Аполлон 11 именно работа Маргарет и ее команды **предотвратила возможный срыв высадки на Луну**. За три минуты до прилунения сработало несколько аварийных сигнальных устройств. Компьютер был перегруженн входящими данными – в стыковочной радарной системе произошло непроизвольное обновление счетчика, что привело к запросу на выполнение компьютером большего числа операций, чем он был способен обработать. Благодаря устойчивой архитектуре компьютер продолжил свою работу: в разработке бортового ПО использовался подход асинхронного исполнения (asynchronous executive). Процессы с высоким приоритетом (критичные для прилунения) могли прервать низкоприоритетные процессы.
> _«После расстыковки командно-служебного и лунного модулей выключатель радара стыковки был поставлен в неправильное положение из-за ошибки в инструкции для астронавтов, радар посылал ошибочные сигналы бортовому компьютеру. Обработка ложных сигналов занимала 15% машинного времени. Бортовой компьютер (точнее, вшитое в него ПО) оказался достаточно разумным для того, чтобы распознать, что на выполнение запрашивается больше операций, чем должно. Далее он выслал оповещение, означавшее для астронавта следующее: «Я перегружен бОльшим количеством задач единовременно, чем предусмотрено, и я продолжу выполнять только наиболее важные, то есть те, что необходимы для прилунения...» По сути, компьютер был запрограммирован на большее, чем просто распознавание ошибочных состояний. В ПО был предусмотрен полный набор программ по восстановлению. В данном конкретном случае реакцией ПО было приостановить работу низкоприоритетных задач и перезапустить (re-establish) наиболее важные. Если бы компьютер не распознал эту проблему и не принял восстановительные меры, я не уверена, что Аполлон 11 совершил бы успешную посадку на Луну.»_
>
> Маргарет Гамильтон
> _«Девушка молоток! Но я бы не хотел себе такую жену, ибо смотрелся бы на ее фоне жалко, хоть и программист… LOL»_
>
>
>
> [Коммент][3]
>
> с GeekTimes
[Читать дальше →][4]
[1]: https://habrastorage.org/files/6d2/307/ed7/6d2307ed76054232bc1d3d17513047ae.jpg
[2]: https://en.wikipedia.org/wiki/Margaret_Hamilton_(scientist)
[3]: https://geektimes.ru/post/242925/#comment_8192555
[4]: https://habrahabr.ru/post/278585/#habracut
habra.16
habrabot(difrex,1) — All
2016-03-04 22:30:02
_«Когда я только начинала работать в этой сфере, все это было для нас как Дикий Запад — мы были первооткрывателями неизведанных земель. Никто нас ничему не учил»_ Маргарет Гамильтон. ![][1] Это [Маргарет][2]. Она пишет код хорошо. Делайте как Маргарет. А еще:
* программист-самоучка;
* написала код для навигационного компьютера программы «Аполлон»;
* когда американцы ступили на поверхность Луны ей был 31 год;
* Маргарет **НЕ** автор термина «software engineering»;
* часто брала на работу 4х-летнюю дочку;
* дочка помогла найти баг в программе.
Под руководством Маргарет Гамильтон писались программы для бортового компьютера КА Аполлон. В один из самых ответственных моментов миссии Аполлон 11 именно работа Маргарет и ее команды **предотвратила возможный срыв высадки на Луну**. За три минуты до прилунения сработало несколько аварийных сигнальных устройств. Компьютер был перегруженн входящими данными – в стыковочной радарной системе произошло непроизвольное обновление счетчика, что привело к запросу на выполнение компьютером большего числа операций, чем он был способен обработать. Благодаря устойчивой архитектуре компьютер продолжил свою работу: в разработке бортового ПО использовался подход асинхронного исполнения (asynchronous executive). Процессы с высоким приоритетом (критичные для прилунения) могли прервать низкоприоритетные процессы.
> _«После расстыковки командно-служебного и лунного модулей выключатель радара стыковки был поставлен в неправильное положение из-за ошибки в инструкции для астронавтов, радар посылал ошибочные сигналы бортовому компьютеру. Обработка ложных сигналов занимала 15% машинного времени. Бортовой компьютер (точнее, вшитое в него ПО) оказался достаточно разумным для того, чтобы распознать, что на выполнение запрашивается больше операций, чем должно. Далее он выслал оповещение, означавшее для астронавта следующее: «Я перегружен бОльшим количеством задач единовременно, чем предусмотрено, и я продолжу выполнять только наиболее важные, то есть те, что необходимы для прилунения...» По сути, компьютер был запрограммирован на большее, чем просто распознавание ошибочных состояний. В ПО был предусмотрен полный набор программ по восстановлению. В данном конкретном случае реакцией ПО было приостановить работу низкоприоритетных задач и перезапустить (re-establish) наиболее важные. Если бы компьютер не распознал эту проблему и не принял восстановительные меры, я не уверена, что Аполлон 11 совершил бы успешную посадку на Луну.»_
>
> Маргарет Гамильтон
> _«Девушка молоток! Но я бы не хотел себе такую жену, ибо смотрелся бы на ее фоне жалко, хоть и программист… LOL»_
>
>
>
> [Коммент][3]
>
> с GeekTimes
[Читать дальше →][4]
[1]: https://habrastorage.org/files/6d2/307/ed7/6d2307ed76054232bc1d3d17513047ae.jpg
{kind=link}
[2]: https://en.wikipedia.org/wiki/Margaret_Hamilton_(scientist)
[3]: https://geektimes.ru/post/242925/#comment_8192555
[4]: https://habrahabr.ru/post/278585/#habracut