|
|
Login |
[>]
Spring MVC/Security, REST, Hibernate, Liquibase запускаем в две строки
habra.15
habrabot(difrex,1) — All
2015-12-08 14:00:02
![][1] Современные системы сборки позволяют полностью автоматизировать процесс компиляции и запуска приложения из исходников. На целевой машине необходим лишь JDK, все остальное включая и сам сборщик загрузится налету. Надо лишь правильно построить процесс сборки и по запуску двух команд получить, например, следующее: запуск базы данных, выполнение SQL скриптов, компиляцию Java, Javascript и CSS файлов, запуск контейнера сервлетов. Реализуется это с помощью Gradle, HSQLDB, Liquibase, Google closure compile и Gretty. Подробнее в статье. [Читать дальше →][2]
[1]: https://habrastorage.org/files/200/413/9d3/2004139d3c1042a69ae608ca5422ee60.png
[2]: http://habrahabr.ru/post/271719/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 14:00:02
![][1] Современные системы сборки позволяют полностью автоматизировать процесс компиляции и запуска приложения из исходников. На целевой машине необходим лишь JDK, все остальное включая и сам сборщик загрузится налету. Надо лишь правильно построить процесс сборки и по запуску двух команд получить, например, следующее: запуск базы данных, выполнение SQL скриптов, компиляцию Java, Javascript и CSS файлов, запуск контейнера сервлетов. Реализуется это с помощью Gradle, HSQLDB, Liquibase, Google closure compile и Gretty. Подробнее в статье. [Читать дальше →][2]
[1]: https://habrastorage.org/files/200/413/9d3/2004139d3c1042a69ae608ca5422ee60.png
{kind=link}
[2]: http://habrahabr.ru/post/271719/#habracut
[>]
Java 8 в параллель. Учимся создавать подзадачи и контролировать их выполнение
habra.15
habrabot(difrex,1) — All
2015-12-08 14:00:02
Всем привет. Продолжаем цикл статей, посвященный обработке больших объемов данных в параллель (красивое слово, неправда?). В предыдущей [статье][1] мы познакомились и интересным инструментарием **Fork/Join Framework**, позволяющим разбить обработку на несколько частей и запустить параллельно выполнение отдельных задач. Что нового в этой статье – спросите Вы? Отвечу – более содержательные примеры и новые механизмы для качественной обработки информации. Параллельно :) я вам расскажу о ресурсных и прочих особенностях работы в этом режиме. ![][2] Всех заинтересованных приглашаю под кат: [Читать дальше →][3]
[1]: http://habrahabr.ru/post/270943/
[2]: https://habrastorage.org/files/1ed/637/257/1ed637257ec2460c97f0d98b7eade44d.png
[3]: http://habrahabr.ru/post/272479/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 14:00:02
Всем привет. Продолжаем цикл статей, посвященный обработке больших объемов данных в параллель (красивое слово, неправда?). В предыдущей [статье][1] мы познакомились и интересным инструментарием **Fork/Join Framework**, позволяющим разбить обработку на несколько частей и запустить параллельно выполнение отдельных задач. Что нового в этой статье – спросите Вы? Отвечу – более содержательные примеры и новые механизмы для качественной обработки информации. Параллельно :) я вам расскажу о ресурсных и прочих особенностях работы в этом режиме. ![][2] Всех заинтересованных приглашаю под кат: [Читать дальше →][3]
[1]: http://habrahabr.ru/post/270943/
[2]: https://habrastorage.org/files/1ed/637/257/1ed637257ec2460c97f0d98b7eade44d.png
{kind=link}
[3]: http://habrahabr.ru/post/272479/#habracut
[>]
[Из песочницы] Анонимное подключение к meterpreter/reverse_tcp через промежуточный сервер с помощью SSH-туннелей
habra.15
habrabot(difrex,1) — All
2015-12-08 14:00:02
Всем привет! Эта статья рассчитана скорее на новичков, которые только начинают своё знакомство с Metasploit Framework, но уже кое-что понимают. Если вы считаете себя опытным специалистом и вас заинтересовало название, можете сразу перейти к [TL;DR;][1] в конце. Речь в этой статье пойдет о том, как устроить анонимный доступ к meterpriter оболочке посредством reverse tcp с использованием промежуточного сервера и SSH туннелей. [Хочу всё знать][2]
[1]: http://habrahabr.ru/post/272547/#tldr
[2]: http://habrahabr.ru/post/272547/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 14:00:02
Всем привет! Эта статья рассчитана скорее на новичков, которые только начинают своё знакомство с Metasploit Framework, но уже кое-что понимают. Если вы считаете себя опытным специалистом и вас заинтересовало название, можете сразу перейти к [TL;DR;][1] в конце. Речь в этой статье пойдет о том, как устроить анонимный доступ к meterpriter оболочке посредством reverse tcp с использованием промежуточного сервера и SSH туннелей. [Хочу всё знать][2]
[1]: http://habrahabr.ru/post/272547/#tldr
[2]: http://habrahabr.ru/post/272547/#habracut
[>]
Вперед, на поиски палиндромов 2
habra.15
habrabot(difrex,1) — All
2015-12-08 14:00:02
Не так давно прочитал на хабре статью [grey\_wolfs][1] [«Вперед, на поиски палиндромов»][2] о решении и оптимизации любопытной конкурсной задачки с весьма лаконичной формулировкой:
> «The decimal number 585 is 1001001001 in binary. It is palindromic in both bases. Find n-th palindromic number». Или, по-русски: «Десятичное число 585 в двоичной системе счисления выглядит как 1001001001. Оно является палиндромом в обеих системах счисления. Найдите n-й подобный палиндром».
[Подробности][3]
[1]: http://habrahabr.ru/users/grey_wolfs/
[2]: http://habrahabr.ru/post/270325/
[3]: http://habrahabr.ru/post/272555/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 14:00:02
Не так давно прочитал на хабре статью [grey\_wolfs][1] [«Вперед, на поиски палиндромов»][2] о решении и оптимизации любопытной конкурсной задачки с весьма лаконичной формулировкой:
> «The decimal number 585 is 1001001001 in binary. It is palindromic in both bases. Find n-th palindromic number». Или, по-русски: «Десятичное число 585 в двоичной системе счисления выглядит как 1001001001. Оно является палиндромом в обеих системах счисления. Найдите n-й подобный палиндром».
[Подробности][3]
[1]: http://habrahabr.ru/users/grey_wolfs/
[2]: http://habrahabr.ru/post/270325/
[3]: http://habrahabr.ru/post/272555/#habracut
[>]
Как разрабатывается Cloud Foundry
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
![CF community logo][1]Я кратко расскажу о процессе разработки [Cloud Foundry][2] (CF), особенностях open source модели и немного личного опыта. В 2013 году я стал активным пользователем платформы, когда IBM запустила внутреннюю бету [Bluemix][3], в начале этого года я принял участие в портировании Cloud Foundry на [архитектуру POWER8][4], а с середины октября я стал членом CF core team, пройдя CF Dojo. Но обо всем по порядку. Не буду углубляться в историю или объяснять что такое Cloud Foundry, но вот необходимый минимум фактов. CF — это Platform as a Service (PaaS), разработанная VMWare и позднее переданная Pivotal Software. Исходный код был [открыт][5], сейчас еще есть отдельный [инкубатор][6] CF проектов. Чуть позже была создана [Cloud Foundry Foundation][7], в которую вошли Pivotal, IBM, VMWare, EMC, GE, Intel, SAP, настоящее время в нее входит более [50 организаций][8]. Изначально платформа была написана на Ruby, позднее часть компонент были переписаны на Go. [Читать дальше →][9]
[1]: https://habrastorage.org/files/840/bc2/176/840bc217654e4e6f8e2beffd8ed1198f.png
[2]: https://en.wikipedia.org/wiki/Cloud_Foundry
[3]: https://bluemix.net
[4]: https://en.wikipedia.org/wiki/POWER8
[5]: https://github.com/cloudfoundry/
[6]: https://github.com/cloudfoundry-incubator/
[7]: https://www.cloudfoundry.org
[8]: https://www.cloudfoundry.org/membership/members/
[9]: http://habrahabr.ru/post/272645/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
![CF community logo][1]Я кратко расскажу о процессе разработки [Cloud Foundry][2] (CF), особенностях open source модели и немного личного опыта. В 2013 году я стал активным пользователем платформы, когда IBM запустила внутреннюю бету [Bluemix][3], в начале этого года я принял участие в портировании Cloud Foundry на [архитектуру POWER8][4], а с середины октября я стал членом CF core team, пройдя CF Dojo. Но обо всем по порядку. Не буду углубляться в историю или объяснять что такое Cloud Foundry, но вот необходимый минимум фактов. CF — это Platform as a Service (PaaS), разработанная VMWare и позднее переданная Pivotal Software. Исходный код был [открыт][5], сейчас еще есть отдельный [инкубатор][6] CF проектов. Чуть позже была создана [Cloud Foundry Foundation][7], в которую вошли Pivotal, IBM, VMWare, EMC, GE, Intel, SAP, настоящее время в нее входит более [50 организаций][8]. Изначально платформа была написана на Ruby, позднее часть компонент были переписаны на Go. [Читать дальше →][9]
[1]: https://habrastorage.org/files/840/bc2/176/840bc217654e4e6f8e2beffd8ed1198f.png
{kind=link}
[2]: https://en.wikipedia.org/wiki/Cloud_Foundry
[3]: https://bluemix.net
[4]: https://en.wikipedia.org/wiki/POWER8
[5]: https://github.com/cloudfoundry/
[6]: https://github.com/cloudfoundry-incubator/
[7]: https://www.cloudfoundry.org
[8]: https://www.cloudfoundry.org/membership/members/
[9]: http://habrahabr.ru/post/272645/#habracut
[>]
Lori Timesheets — учет времени на платформе CUBA
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
> _“Время – это капитал работника умственного труда.” **Оноре де Бальзак**_
Часто случается, что люди отдают предпочтение старым и привычным вещам, игнорируя новые, даже себе во вред. Вот так и мы долгое время с упорством использовали систему учета времени, которая не отвечала нашим требованиям и постоянно создавала проблемы буквально всем — от программистов до бухгалтерии. ![][1] Всеобщие мучения с системой учета времени, по причине отсутствия времени (см рисунок), не стали веским основанием для разработки своей системы. Спасла же ситуацию идея написать реальное приложение для демонстрации возможностей нашей платформы CUBA. Совмещая приятное с полезным, система учета времени стала первым кандидатом. В настоящий момент разработка завершена, приложение внедрено в нашей компании, и мы готовы [поделиться][2] им со всеми желающими. В этой статье я расскажу, как мы в сжатые сроки (< 1 мес), ограниченными силами (человек и еще полчеловека) разработали это приложение. [Если вам интересно, добро пожаловать под кат][3]
[1]: https://habrastorage.org/files/6aa/244/d70/6aa244d704354f4383fe9b0b05bdafdf.png
[2]: https://www.cuba-platform.ru/solutions
[3]: http://habrahabr.ru/post/272231/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
> _“Время – это капитал работника умственного труда.” **Оноре де Бальзак**_
Часто случается, что люди отдают предпочтение старым и привычным вещам, игнорируя новые, даже себе во вред. Вот так и мы долгое время с упорством использовали систему учета времени, которая не отвечала нашим требованиям и постоянно создавала проблемы буквально всем — от программистов до бухгалтерии. ![][1] Всеобщие мучения с системой учета времени, по причине отсутствия времени (см рисунок), не стали веским основанием для разработки своей системы. Спасла же ситуацию идея написать реальное приложение для демонстрации возможностей нашей платформы CUBA. Совмещая приятное с полезным, система учета времени стала первым кандидатом. В настоящий момент разработка завершена, приложение внедрено в нашей компании, и мы готовы [поделиться][2] им со всеми желающими. В этой статье я расскажу, как мы в сжатые сроки (< 1 мес), ограниченными силами (человек и еще полчеловека) разработали это приложение. [Если вам интересно, добро пожаловать под кат][3]
[1]: https://habrastorage.org/files/6aa/244/d70/6aa244d704354f4383fe9b0b05bdafdf.png
{kind=link}
[2]: https://www.cuba-platform.ru/solutions
[3]: http://habrahabr.ru/post/272231/#habracut
[>]
Что нам стоит сайт распарсить. Основы webdriver API
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
[Поиск жилья][1], информации о товарах, вакансий, [знакомств][2], сравнение товаров фирмы с конкурентами, исследование отзывов в сети. ![][3] В интернет опубликовано много полезной информации и умение извлекать данные поможет в жизни и работе. Научимся получать информацию с помощью webdriver API. В публикации приведу два примера, код которых доступен на github. В конце статьи скринкаст про то, как программа управляет браузером. [Читать дальше →][4]
[1]: http://habrahabr.ru/post/237869/
[2]: http://habrahabr.ru/post/244193/
[3]: https://habrastorage.org/files/023/f78/7cc/023f787cc19746b7906d9fa1abdd335f.png
[4]: http://habrahabr.ru/post/272105/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
[Поиск жилья][1], информации о товарах, вакансий, [знакомств][2], сравнение товаров фирмы с конкурентами, исследование отзывов в сети. ![][3] В интернет опубликовано много полезной информации и умение извлекать данные поможет в жизни и работе. Научимся получать информацию с помощью webdriver API. В публикации приведу два примера, код которых доступен на github. В конце статьи скринкаст про то, как программа управляет браузером. [Читать дальше →][4]
[1]: http://habrahabr.ru/post/237869/
[2]: http://habrahabr.ru/post/244193/
[3]: https://habrastorage.org/files/023/f78/7cc/023f787cc19746b7906d9fa1abdd335f.png
{kind=link}
[4]: http://habrahabr.ru/post/272105/#habracut
[>]
Альтернатива Unity: Urho3D + C# + Xamarin
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
Про Urho3D уже [писали][1] на хабре, это полностью открытый 3D движок на языке С++ с редактором и интересным набором 3rd parties: Box2D, Bullet, kNet, Recast/Detour, SDL, FreeType и т.п. У движка есть редактор (написанный на нем же), но к сожалению, он далеко от Unity, зато есть другие плюсы (о них далее). Движок имеет очень аккуратный API, что стало причиной обращения взгляда Xamarin для использования кодогенератора (С++ API to C#) для генерации байндингов поверх API на языке C#. В результате получился движок ([UrhoSharp][2]) со следующими плюсами (по сравнению с тем же Unity):
* Полная поддержка последней версии Mono 4.2.x, C# 6.0/F# с Xamarin Studio / Visual Studio — грубо говоря это обычное приложение с шаблонами проектов для Visual Studio
* Открытый код (однако, для запуска на iOS и Android понадобится как минимум Xamarin Indie лицензия поскольку именно Xamarin используется на этих ОС в качестве платформы)
* Наличие C# (Xamarin) контролов, которые могут быть интегрированы в существующие неигровые приложения.
* Все плюшки оригинального движка, описанные в большом списке [тут][3].
* Распространяется через Nuget который содержит базовые ассеты и native библиотеки что делает его легко подключаемым
* Отличная производительность, минимальный оверхед от .NET/Mono
![][4] [Читать дальше →][5]
[1]: http://habrahabr.ru/post/265611/
[2]: http://developer.xamarin.com/guides/cross-platform/urho/
[3]: http://urho3d.github.io/
[4]: https://habrastorage.org/files/830/b6e/00c/830b6e00cf14404a8b558cc9e5fb9881.png
[5]: http://habrahabr.ru/post/272637/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
Про Urho3D уже [писали][1] на хабре, это полностью открытый 3D движок на языке С++ с редактором и интересным набором 3rd parties: Box2D, Bullet, kNet, Recast/Detour, SDL, FreeType и т.п. У движка есть редактор (написанный на нем же), но к сожалению, он далеко от Unity, зато есть другие плюсы (о них далее). Движок имеет очень аккуратный API, что стало причиной обращения взгляда Xamarin для использования кодогенератора (С++ API to C#) для генерации байндингов поверх API на языке C#. В результате получился движок ([UrhoSharp][2]) со следующими плюсами (по сравнению с тем же Unity):
* Полная поддержка последней версии Mono 4.2.x, C# 6.0/F# с Xamarin Studio / Visual Studio — грубо говоря это обычное приложение с шаблонами проектов для Visual Studio
* Открытый код (однако, для запуска на iOS и Android понадобится как минимум Xamarin Indie лицензия поскольку именно Xamarin используется на этих ОС в качестве платформы)
* Наличие C# (Xamarin) контролов, которые могут быть интегрированы в существующие неигровые приложения.
* Все плюшки оригинального движка, описанные в большом списке [тут][3].
* Распространяется через Nuget который содержит базовые ассеты и native библиотеки что делает его легко подключаемым
* Отличная производительность, минимальный оверхед от .NET/Mono
![][4] [Читать дальше →][5]
[1]: http://habrahabr.ru/post/265611/
[2]: http://developer.xamarin.com/guides/cross-platform/urho/
[3]: http://urho3d.github.io/
[4]: https://habrastorage.org/files/830/b6e/00c/830b6e00cf14404a8b558cc9e5fb9881.png
{kind=link}
[5]: http://habrahabr.ru/post/272637/#habracut
[>]
А можно ли не платить за панель? «Монетка»
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
Наступает момент когда [виртуального хостинга][1] становиться недостаточно и Ваш проект так и «проситься» на сервер. Не всегда для новых задач Вам понадобится сразу [выделенный сервер][2], но как минимум с [виртуального сервера][3] начать стоит. При этом многие из Вас, что бы как то сэкономить начинают искать партнера(ов) для аренды более производительной услуги. Также, одним из вариантов экономии бюджета — есть использование бесплатного программного обеспечения. Ведь не каждому из Вас, например, будет приятно сидеть в консоле и устанавливать необходимое ПО, или производить управление Вашими сайтами через туже командную строку. В такие моменты на помощь многим вебмастерам приходят панели управления хостингом, и как же приятно когда эта панель — именно качественный и бесплатный софт. Совсем недавно мы уже [рассказывали][4] об одном бесплатном программном продукте, ну а сегодня речь пойдет об еще одной интересной панели управления хостингом, а именно о «монетке»… ![][5] [Читать дальше →][6]
[1]: http://ua-hosting.company/hosting?language=russian
[2]: http://ua-hosting.company/servers?language=russian
[3]: http://ua-hosting.company/vps?language=russian
[4]: http://habrahabr.ru/company/ua-hosting/blog/271673/
[5]: https://habrastorage.org/files/cd5/81d/2f3/cd581d2f3894453c9fc6f988de171def.jpg
[6]: http://habrahabr.ru/post/272633/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 19:00:03
Наступает момент когда [виртуального хостинга][1] становиться недостаточно и Ваш проект так и «проситься» на сервер. Не всегда для новых задач Вам понадобится сразу [выделенный сервер][2], но как минимум с [виртуального сервера][3] начать стоит. При этом многие из Вас, что бы как то сэкономить начинают искать партнера(ов) для аренды более производительной услуги. Также, одним из вариантов экономии бюджета — есть использование бесплатного программного обеспечения. Ведь не каждому из Вас, например, будет приятно сидеть в консоле и устанавливать необходимое ПО, или производить управление Вашими сайтами через туже командную строку. В такие моменты на помощь многим вебмастерам приходят панели управления хостингом, и как же приятно когда эта панель — именно качественный и бесплатный софт. Совсем недавно мы уже [рассказывали][4] об одном бесплатном программном продукте, ну а сегодня речь пойдет об еще одной интересной панели управления хостингом, а именно о «монетке»… ![][5] [Читать дальше →][6]
[1]: http://ua-hosting.company/hosting?language=russian
[2]: http://ua-hosting.company/servers?language=russian
[3]: http://ua-hosting.company/vps?language=russian
[4]: http://habrahabr.ru/company/ua-hosting/blog/271673/
[5]: https://habrastorage.org/files/cd5/81d/2f3/cd581d2f3894453c9fc6f988de171def.jpg
{kind=link}
[6]: http://habrahabr.ru/post/272633/#habracut
[>]
[Перевод] Научиться программировать сложнее, чем кажется
habra.15
habrabot(difrex,1) — All
2015-12-08 22:00:03
![][1] _Просто «El clasico»_ «Много букв», «не осилил»: как показывает опыт, программирование требует наличия определенных способностей, которыми обладает лишь небольшой процент населения земли. Современная мода на экспресс-курсы в этой области порождает все больше спекуляций на тему, что отнюдь не способствует росту количества квалифицированных программистов. Этот пост подготовлен с учетом реалий Великобритании, а потому совершенно логично, что в других странах ситуация может выглядеть иначе, в частности, когда речь идет о социальном статусе разработчиков программного обеспечения. Средства массовой информации не перестают освещать тему нехватки квалифицированных программистов («программистов», «кодировщиков», «разработчиков ПО», поскольку все термины означают одно и тоже, я буду использовать из как взаимозаменяемые). Постоянно ведутся споры по поводу низкого уровня квалификации программистов. По сути мы просто не в состоянии подготовить кадры, соответствующие «солидным запросам завтрашнего дня». Вот что пишет The Telegraph: «Согласно данным Научного Совета, к 2030 году количество специалистов в сфере информационно-коммуникационных технологий вырастет на 39%, а в отчете О2 за 2013 год отмечалось, что для удовлетворения спроса на такого рода специалистов в период до 2017 года потребуется порядка 745 000 новых сотрудников. Кроме того, по результатам исследований, проведенных в прошлом году City & Guilds, три четверти работодателей из сферы IT, компьютерных и информационных услуг отметили явную нехватку квалифицированных кадров, в то время как 47% опрошенных заявили о неспособности действующей системы образования подготовить хороших специалистов». [Читать дальше →][2]
[1]: https://habrastorage.org/files/039/52f/9b7/03952f9b74474fa5837b758f5e9dabb1.JPG
[2]: http://habrahabr.ru/post/272617/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 22:00:03
![][1] _Просто «El clasico»_ «Много букв», «не осилил»: как показывает опыт, программирование требует наличия определенных способностей, которыми обладает лишь небольшой процент населения земли. Современная мода на экспресс-курсы в этой области порождает все больше спекуляций на тему, что отнюдь не способствует росту количества квалифицированных программистов. Этот пост подготовлен с учетом реалий Великобритании, а потому совершенно логично, что в других странах ситуация может выглядеть иначе, в частности, когда речь идет о социальном статусе разработчиков программного обеспечения. Средства массовой информации не перестают освещать тему нехватки квалифицированных программистов («программистов», «кодировщиков», «разработчиков ПО», поскольку все термины означают одно и тоже, я буду использовать из как взаимозаменяемые). Постоянно ведутся споры по поводу низкого уровня квалификации программистов. По сути мы просто не в состоянии подготовить кадры, соответствующие «солидным запросам завтрашнего дня». Вот что пишет The Telegraph: «Согласно данным Научного Совета, к 2030 году количество специалистов в сфере информационно-коммуникационных технологий вырастет на 39%, а в отчете О2 за 2013 год отмечалось, что для удовлетворения спроса на такого рода специалистов в период до 2017 года потребуется порядка 745 000 новых сотрудников. Кроме того, по результатам исследований, проведенных в прошлом году City & Guilds, три четверти работодателей из сферы IT, компьютерных и информационных услуг отметили явную нехватку квалифицированных кадров, в то время как 47% опрошенных заявили о неспособности действующей системы образования подготовить хороших специалистов». [Читать дальше →][2]
[1]: https://habrastorage.org/files/039/52f/9b7/03952f9b74474fa5837b758f5e9dabb1.JPG
{kind=link}
[2]: http://habrahabr.ru/post/272617/#habracut
[>]
[Перевод] Нейросеть на Python, часть 2: градиентный спуск
habra.15
habrabot(difrex,1) — All
2015-12-08 22:30:02
_[Часть 1][1]_
#### Давай сразу код!
import numpy as np
X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
alpha,hidden_dim = (0.5,4)
synapse_0 = 2*np.random.random((3,hidden_dim)) - 1
synapse_1 = 2*np.random.random((hidden_dim,1)) - 1
for j in xrange(60000):
layer_1 = 1/(1+np.exp(-(np.dot(X,synapse_0))))
layer_2 = 1/(1+np.exp(-(np.dot(layer_1,synapse_1))))
layer_2_delta = (layer_2 - y)*(layer_2*(1-layer_2))
layer_1_delta = layer_2_delta.dot(synapse_1.T) * (layer_1 * (1-layer_1))
synapse_1 -= (alpha * layer_1.T.dot(layer_2_delta))
synapse_0 -= (alpha * X.T.dot(layer_1_delta))
#### Часть 1: Оптимизация
В первой части я описал основные принципы обратного распространения в простой нейросети. Сеть позволила нам померить, каким образом каждый из весов сети вносит свой вклад в ошибку. И это позволило нам менять веса при помощи другого алгоритма — градиентного спуска. Суть происходящего в том, что обратное распространение не вносит в работу сети оптимизацию. Оно перемещает неверную информацию с конца сети на все веса внутри, чтобы другой алгоритм уже смог оптимизировать эти веса так, чтобы они соответствовали нашим данным. Но в принципе, у нас в изобилии присутствуют и другие методы нелинейной оптимизации, которые мы можем использовать с обратным распространением: [Читать дальше →][2]
[1]: http://habrahabr.ru/post/271563/
[2]: http://habrahabr.ru/post/272679/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-08 22:30:02
_[Часть 1][1]_
#### Давай сразу код!
import numpy as np
X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
alpha,hidden_dim = (0.5,4)
synapse_0 = 2*np.random.random((3,hidden_dim)) - 1
synapse_1 = 2*np.random.random((hidden_dim,1)) - 1
for j in xrange(60000):
layer_1 = 1/(1+np.exp(-(np.dot(X,synapse_0))))
layer_2 = 1/(1+np.exp(-(np.dot(layer_1,synapse_1))))
layer_2_delta = (layer_2 - y)*(layer_2*(1-layer_2))
layer_1_delta = layer_2_delta.dot(synapse_1.T) * (layer_1 * (1-layer_1))
synapse_1 -= (alpha * layer_1.T.dot(layer_2_delta))
synapse_0 -= (alpha * X.T.dot(layer_1_delta))
#### Часть 1: Оптимизация
В первой части я описал основные принципы обратного распространения в простой нейросети. Сеть позволила нам померить, каким образом каждый из весов сети вносит свой вклад в ошибку. И это позволило нам менять веса при помощи другого алгоритма — градиентного спуска. Суть происходящего в том, что обратное распространение не вносит в работу сети оптимизацию. Оно перемещает неверную информацию с конца сети на все веса внутри, чтобы другой алгоритм уже смог оптимизировать эти веса так, чтобы они соответствовали нашим данным. Но в принципе, у нас в изобилии присутствуют и другие методы нелинейной оптимизации, которые мы можем использовать с обратным распространением: [Читать дальше →][2]
[1]: http://habrahabr.ru/post/271563/
[2]: http://habrahabr.ru/post/272679/#habracut
[>]
collectd + front-end
habra.15
habrabot(difrex,1) — All
2015-12-09 11:30:02
![][1] Как показывает практика — б**o**льшая часть клиентов никак не мониторит используемые ресурсы, арендуемых ими услуг (особенно это заметно на дешевых услугах VPS от 3$).То есть, после установки системы и настройки необходимого для проекта софта, дальнейшая судьба сервера отдается на откуп случаю. И, когда появляются проблемы с работоспособностью сервера, информации для анализа не слишком много. _Кроме установленного и настроенного логирования в [atop][2] (который так же встречается не часто), логов системы, хотелось бы иметь больше информации с которой можно работать._ В данной статье будет описана процедура установки и настройки [collectd][3] и [collectd-web][4] на примере ОС семейства Debian. [Читать дальше][5]
[1]: https://habrastorage.org/files/14e/71d/c1c/14e71dc1ccb44f19995dd6612b1fce90.png
[2]: https://ru.wikipedia.org/wiki/Atop
[3]: https://collectd.org/
[4]: https://github.com/httpdss/collectd-web
[5]: http://habrahabr.ru/post/272447/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 11:30:02
![][1] Как показывает практика — б**o**льшая часть клиентов никак не мониторит используемые ресурсы, арендуемых ими услуг (особенно это заметно на дешевых услугах VPS от 3$).То есть, после установки системы и настройки необходимого для проекта софта, дальнейшая судьба сервера отдается на откуп случаю. И, когда появляются проблемы с работоспособностью сервера, информации для анализа не слишком много. _Кроме установленного и настроенного логирования в [atop][2] (который так же встречается не часто), логов системы, хотелось бы иметь больше информации с которой можно работать._ В данной статье будет описана процедура установки и настройки [collectd][3] и [collectd-web][4] на примере ОС семейства Debian. [Читать дальше][5]
[1]: https://habrastorage.org/files/14e/71d/c1c/14e71dc1ccb44f19995dd6612b1fce90.png
{kind=link}
[2]: https://ru.wikipedia.org/wiki/Atop
[3]: https://collectd.org/
[4]: https://github.com/httpdss/collectd-web
[5]: http://habrahabr.ru/post/272447/#habracut
[>]
Легко ли распознать информацию на банковской карточке?
habra.15
habrabot(difrex,1) — All
2015-12-09 13:00:02
![][1] Когда мы общаемся с нашими заказчиками, то, будучи специалистами в этой области, активно используем соответствующую терминологию, в частности слово «распознавание». При этом слушающая аудитория, воспитанная на Cuneiform и FineReader, часто вкладывает в этот термин именно задачу сопоставления вырезанного участка изображения некоторому числу (коду символа), которая в наши дни решается нейросетевым подходом и является далеко не первым этапом в задаче распознавания информации. В начале необходимо локализовать карточку на изображении, найти информационные поля, выполнить сегментацию на символы. Каждая перечисленная подзадача с формальной точки зрения является самостоятельной задачей распознавания. И если для обучения нейронных сетей существуют зарекомендовавшие себя подходы и инструменты, то в задачах ориентации и сегментации каждый раз требуется индивидуальный подход. Если вам интересно узнать про подходы, которые мы использовали при решении задачи распознавания банковской карточки, тогда добро пожаловать под кат! [Читать дальше →][2]
[1]: https://habrastorage.org/files/9d1/714/ca1/9d1714ca18cf4e149701b65e7e491d88.png
[2]: http://habrahabr.ru/post/272607/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 13:00:02
![][1] Когда мы общаемся с нашими заказчиками, то, будучи специалистами в этой области, активно используем соответствующую терминологию, в частности слово «распознавание». При этом слушающая аудитория, воспитанная на Cuneiform и FineReader, часто вкладывает в этот термин именно задачу сопоставления вырезанного участка изображения некоторому числу (коду символа), которая в наши дни решается нейросетевым подходом и является далеко не первым этапом в задаче распознавания информации. В начале необходимо локализовать карточку на изображении, найти информационные поля, выполнить сегментацию на символы. Каждая перечисленная подзадача с формальной точки зрения является самостоятельной задачей распознавания. И если для обучения нейронных сетей существуют зарекомендовавшие себя подходы и инструменты, то в задачах ориентации и сегментации каждый раз требуется индивидуальный подход. Если вам интересно узнать про подходы, которые мы использовали при решении задачи распознавания банковской карточки, тогда добро пожаловать под кат! [Читать дальше →][2]
[1]: https://habrastorage.org/files/9d1/714/ca1/9d1714ca18cf4e149701b65e7e491d88.png
{kind=link}
[2]: http://habrahabr.ru/post/272607/#habracut
[>]
Революция WikiLeaks: дайджест злоключений
habra.15
habrabot(difrex,1) — All
2015-12-09 14:30:02
Сейчас в сети можно встретить множество упоминаний о WikiLeaks. Особенно в свете его притеснения со стороны правительственных спецслужб. Однако систематической и краткой информации, – которая может быть полезна при проведении тренингов по информационной безопасности, – об этом не так много. Представляю вашему вниманию свою версию такого систематически-краткого описания. Данная статья – это сжатый конспект тематических вырезок книги «Шифропанки: свобода и будущее Интернета», касающихся WikiLeaks. ![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/52f/339/403/52f339403265474a8ea99645d1e286c6.jpg
[2]: http://habrahabr.ru/post/272703/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 14:30:02
Сейчас в сети можно встретить множество упоминаний о WikiLeaks. Особенно в свете его притеснения со стороны правительственных спецслужб. Однако систематической и краткой информации, – которая может быть полезна при проведении тренингов по информационной безопасности, – об этом не так много. Представляю вашему вниманию свою версию такого систематически-краткого описания. Данная статья – это сжатый конспект тематических вырезок книги «Шифропанки: свобода и будущее Интернета», касающихся WikiLeaks. ![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/52f/339/403/52f339403265474a8ea99645d1e286c6.jpg
{kind=link}
[2]: http://habrahabr.ru/post/272703/#habracut
[>]
[Из песочницы] Битовая магия: получение следующего лексикографического сочетания
habra.15
habrabot(difrex,1) — All
2015-12-09 14:30:02
# Введение
Допустим у нас есть некоторое множество, которое состоит из _N_ элементов. Будем считать, что элементы пронумерованы от нуля до _N-1_. Набор _k_-элементных подмножеств данного множества (сочетаний) можно представить либо в виде массива индексов длины _k_. Либо в виде последовательности из _N_ бит, в которой установлено ровно _k_ из них. У Дональда Кнута в его приводится алгоритм генерации сочетаний в лексикографическом порядке, когда сочетания заданы в виде массива индексов. Мы попробуем перенести этот алгоритм на случай битовых масок. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/272707/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 14:30:02
# Введение
Допустим у нас есть некоторое множество, которое состоит из _N_ элементов. Будем считать, что элементы пронумерованы от нуля до _N-1_. Набор _k_-элементных подмножеств данного множества (сочетаний) можно представить либо в виде массива индексов длины _k_. Либо в виде последовательности из _N_ бит, в которой установлено ровно _k_ из них. У Дональда Кнута в его приводится алгоритм генерации сочетаний в лексикографическом порядке, когда сочетания заданы в виде массива индексов. Мы попробуем перенести этот алгоритм на случай битовых масок. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/272707/#habracut
[>]
Собственные типы индексов в СУБД Caché
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
[![][1]][2] В объектной и реляционной моделях данных СУБД Caché есть три типа индексов — обычные, [bitmap][3] и [bitslice][4]. Если по каким-то причинам этих индексов не хватает, начиная с версии 2013.1 программист может определить свой тип индексов и использовать его в любых классах. Подробности под катом (если вас не пугают слова типа метод-генератор). [Читать дальше →][5]
[1]: https://habrastorage.org/files/6c7/a54/754/6c7a547547284690aaf4668949b8b29e.jpg "Николай Загреков — Крестьянин с косой"
[2]: http://habrahabr.ru/post/272689/
[3]: http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_indices#GSQL_indices_bitmap
[4]: http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_indices#GSQL_indices_bitslice
[5]: http://habrahabr.ru/post/272689/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
[![][1]][2] В объектной и реляционной моделях данных СУБД Caché есть три типа индексов — обычные, [bitmap][3] и [bitslice][4]. Если по каким-то причинам этих индексов не хватает, начиная с версии 2013.1 программист может определить свой тип индексов и использовать его в любых классах. Подробности под катом (если вас не пугают слова типа метод-генератор). [Читать дальше →][5]
[1]: https://habrastorage.org/files/6c7/a54/754/6c7a547547284690aaf4668949b8b29e.jpg "Николай Загреков — Крестьянин с косой"
{kind=link}
[2]: http://habrahabr.ru/post/272689/
[3]: http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_indices#GSQL_indices_bitmap
[4]: http://docs.intersystems.com/cache20152/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_indices#GSQL_indices_bitslice
[5]: http://habrahabr.ru/post/272689/#habracut
[>]
Python Meetup октябрь: Deliberate Practice и десктоп-приложения на Penta.by
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
Всем привет! Спешим поделиться видеозаписями выступлений с очередной встречи минского Python-сообщества. Под катом вы найдете доклады:
* Deliberate Practice: Coding Dojo, Code Kata and Coderetreat / Сергей Сергиенко
* Быстрая разработка десктоп-приложений с Penta.by / Андрей Пучко
* WRK: Modern HTTP benchmarking tool / Алексей Романов
Приятного просмотра! ![image][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/c26/f75/966/c26f759666b1420395f98c03cf62ae3a.jpg
[2]: http://habrahabr.ru/post/272739/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
Всем привет! Спешим поделиться видеозаписями выступлений с очередной встречи минского Python-сообщества. Под катом вы найдете доклады:
* Deliberate Practice: Coding Dojo, Code Kata and Coderetreat / Сергей Сергиенко
* Быстрая разработка десктоп-приложений с Penta.by / Андрей Пучко
* WRK: Modern HTTP benchmarking tool / Алексей Романов
Приятного просмотра! ![image][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/c26/f75/966/c26f759666b1420395f98c03cf62ae3a.jpg
{kind=link}
[2]: http://habrahabr.ru/post/272739/#habracut
[>]
Oбновление Vim FileStyle
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
### **О прошлом**
В декабре прошлого года, я [писал][1] о плагине который позволяет при открытии файла увидеть несоблюдение некоторых аспектов кодинг стандарта. ![image][2] Прошло время и плагин получил новый функционал. [Читать дальше →][3]
[1]: http://habrahabr.ru/post/245691/
[2]: https://habrastorage.org/getpro/habr/post_images/1a0/8a7/7ae/1a08a77ae7bb846ae419dfd6a4c25dd8.png
[3]: http://habrahabr.ru/post/267765/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
### **О прошлом**
В декабре прошлого года, я [писал][1] о плагине который позволяет при открытии файла увидеть несоблюдение некоторых аспектов кодинг стандарта. ![image][2] Прошло время и плагин получил новый функционал. [Читать дальше →][3]
[1]: http://habrahabr.ru/post/245691/
[2]: https://habrastorage.org/getpro/habr/post_images/1a0/8a7/7ae/1a08a77ae7bb846ae419dfd6a4c25dd8.png
{kind=link}
[3]: http://habrahabr.ru/post/267765/#habracut
[>]
[Из песочницы] Простой метапоисковый алгоритм на Python
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
#### Лирическое отступление
В рамках научно-исследовательской работы в вузе я столкнулся с такой задачей, как классификация текстовой информации. По сути, мне нужно было создать алгоритм, который, обрабатывая определенный текстовый документ на входе, вернул бы мне на выходе массив, каждый элемент которого являлся бы мерой принадлежности этого текста (вероятностью или степенью уверенности) к одной из заданных тематик. В данной статье речь пойдет не о решении задачи классификации конкретно, а о попытке автоматизировать наиболее скучный этап разработки рубрикатора — создание обучающей выборки.
#### Когда лень работать руками
Первая и самая очевидная для меня мысль – написать простой метапоисковый алгоритм на Python. Другими словами, вся автоматизация сводится к использованию выдачи другой поисковой машины (Google Search) за неимением своих баз данных. Сразу оговорюсь, есть уже готовые библиотеки, решающие подобную задачу, например pygoogle. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/272711/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
#### Лирическое отступление
В рамках научно-исследовательской работы в вузе я столкнулся с такой задачей, как классификация текстовой информации. По сути, мне нужно было создать алгоритм, который, обрабатывая определенный текстовый документ на входе, вернул бы мне на выходе массив, каждый элемент которого являлся бы мерой принадлежности этого текста (вероятностью или степенью уверенности) к одной из заданных тематик. В данной статье речь пойдет не о решении задачи классификации конкретно, а о попытке автоматизировать наиболее скучный этап разработки рубрикатора — создание обучающей выборки.
#### Когда лень работать руками
Первая и самая очевидная для меня мысль – написать простой метапоисковый алгоритм на Python. Другими словами, вся автоматизация сводится к использованию выдачи другой поисковой машины (Google Search) за неимением своих баз данных. Сразу оговорюсь, есть уже готовые библиотеки, решающие подобную задачу, например pygoogle. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/272711/#habracut
[>]
«Прозрачный» Squid с фильтрацией HTTPS ресурсов без подмены сертификатов (х86, х64 — универсальная инструкция)
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
Всем привет! [Прошлая статья][1] про прозрачное проксирование HTTPS с помощью Squid'a была вполне успешной. Приходило по почте множество отзывов об успешной установке данной системы. Но также и поступали письма с просьбами о помощи. Проблемы были вполне решаемыми. Но не так давно обратилась ко мне одна коллега с просьбой о помощи в установке этой системы на х64 архитектуре (Debian). Тут мы озадачились. Во-первых, оказалось, что прошлая статья непригодна для этого по причине отсутствия нужных исходников в репозитории Debian (там теперь 3.5.10). Найти нужные в первой статье Debian'овские исходники не удалось, а checkinstall выдавал странные ошибки. Во-вторых, хотелось более универсального решения, которое бы без проблем работало и на х64, и на х86, и (по-возможности) на других дистрибутивах. Решение было найдено. Получилось небольшое дополнение к предыдущей статье + некоторые уточнения. Данная инструкция позволяет скомпилировать как х86, так и х64 версии Squid'a и создать соответствующие пакеты. Инструкция будет разбита на несколько пунктов и подпунктов. Если интересно, идем под кат: [Читать дальше →][2]
[1]: http://habrahabr.ru/post/267851/
[2]: http://habrahabr.ru/post/272733/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-09 18:00:02
Всем привет! [Прошлая статья][1] про прозрачное проксирование HTTPS с помощью Squid'a была вполне успешной. Приходило по почте множество отзывов об успешной установке данной системы. Но также и поступали письма с просьбами о помощи. Проблемы были вполне решаемыми. Но не так давно обратилась ко мне одна коллега с просьбой о помощи в установке этой системы на х64 архитектуре (Debian). Тут мы озадачились. Во-первых, оказалось, что прошлая статья непригодна для этого по причине отсутствия нужных исходников в репозитории Debian (там теперь 3.5.10). Найти нужные в первой статье Debian'овские исходники не удалось, а checkinstall выдавал странные ошибки. Во-вторых, хотелось более универсального решения, которое бы без проблем работало и на х64, и на х86, и (по-возможности) на других дистрибутивах. Решение было найдено. Получилось небольшое дополнение к предыдущей статье + некоторые уточнения. Данная инструкция позволяет скомпилировать как х86, так и х64 версии Squid'a и создать соответствующие пакеты. Инструкция будет разбита на несколько пунктов и подпунктов. Если интересно, идем под кат: [Читать дальше →][2]
[1]: http://habrahabr.ru/post/267851/
[2]: http://habrahabr.ru/post/272733/#habracut
[>]
Эхо «правды Сноудена»: Дед Мороз следит за тобой
habra.15
habrabot(difrex,1) — All
2015-12-10 01:30:02
После серии широко известных разоблачений, инициированных Эдвардом Сноуденом, в СМИ всё чаще и чаще говорят о т.н. «большом брате». Весна Интернета позади. Из объединяющего пространства, свободного от цензуры, Сеть превратилась в орудие глобального контроля. Государства всё жёстче отслеживают поступки своих граждан, подавляя любые нежелательные действия, и не только их. ![][1] Владеет Сетью тот, кто контролирует её структуры, разбросанные по городам мира: волоконно-оптические линии связи, спутники, серверы. Тотальный характер мощнейшей машины контроля пока очевиден не всем пользователям Интернета. Джулиан Ассанж, – основавший знаменитый проект WikiLeaks – и его соратники по движению «шифропанков» призывают к борьбе за свободу обмена информацией. Их оружие – криптография. Ими объявлен общий сбор под знамёна шифрования. [Читать дальше →][2]
[1]: https://habrastorage.org/files/cb9/5bd/21a/cb95bd21a33c4874925483a7d535d00a.jpg
[2]: http://habrahabr.ru/post/272727/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 01:30:02
После серии широко известных разоблачений, инициированных Эдвардом Сноуденом, в СМИ всё чаще и чаще говорят о т.н. «большом брате». Весна Интернета позади. Из объединяющего пространства, свободного от цензуры, Сеть превратилась в орудие глобального контроля. Государства всё жёстче отслеживают поступки своих граждан, подавляя любые нежелательные действия, и не только их. ![][1] Владеет Сетью тот, кто контролирует её структуры, разбросанные по городам мира: волоконно-оптические линии связи, спутники, серверы. Тотальный характер мощнейшей машины контроля пока очевиден не всем пользователям Интернета. Джулиан Ассанж, – основавший знаменитый проект WikiLeaks – и его соратники по движению «шифропанков» призывают к борьбе за свободу обмена информацией. Их оружие – криптография. Ими объявлен общий сбор под знамёна шифрования. [Читать дальше →][2]
[1]: https://habrastorage.org/files/cb9/5bd/21a/cb95bd21a33c4874925483a7d535d00a.jpg
{kind=link}
[2]: http://habrahabr.ru/post/272727/#habracut
[>]
[Из песочницы] Общая схема построения алгоритмов на примере кубика Рубика
habra.15
habrabot(difrex,1) — All
2015-12-10 15:00:02
![][1] Возможно, многие из читателей пытались собрать кубик Рубика 3×3 самостоятельно, но после множества неудачных попыток либо бросали это занятие, либо искали готовое решение. Целью этой статьи является показать на примере кубика Рубика что найти решение любой (из класса решаемых) задачи самостоятельно, есть вполне выполнимая задача для каждого, если при этом руководствоваться определенным набором правил. Данное решение получено мною за 10 часов, плюс этого алгоритма что он не требует запоминать сложные комбинации и длительное время тренироваться — достаточно собрать данным способом всего несколько раз. [Читать дальше →][2]
[1]: https://habrastorage.org/files/6a9/8ac/f7f/6a98acf7f01f47478c5943e87dbb9d21.png
[2]: http://habrahabr.ru/post/272803/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 15:00:02
![][1] Возможно, многие из читателей пытались собрать кубик Рубика 3×3 самостоятельно, но после множества неудачных попыток либо бросали это занятие, либо искали готовое решение. Целью этой статьи является показать на примере кубика Рубика что найти решение любой (из класса решаемых) задачи самостоятельно, есть вполне выполнимая задача для каждого, если при этом руководствоваться определенным набором правил. Данное решение получено мною за 10 часов, плюс этого алгоритма что он не требует запоминать сложные комбинации и длительное время тренироваться — достаточно собрать данным способом всего несколько раз. [Читать дальше →][2]
[1]: https://habrastorage.org/files/6a9/8ac/f7f/6a98acf7f01f47478c5943e87dbb9d21.png
{kind=link}
[2]: http://habrahabr.ru/post/272803/#habracut
[>]
[recovery mode] Лаборатория тестирования на проникновение «Test lab v.8»: банк взломан
habra.15
habrabot(difrex,1) — All
2015-12-10 15:30:02
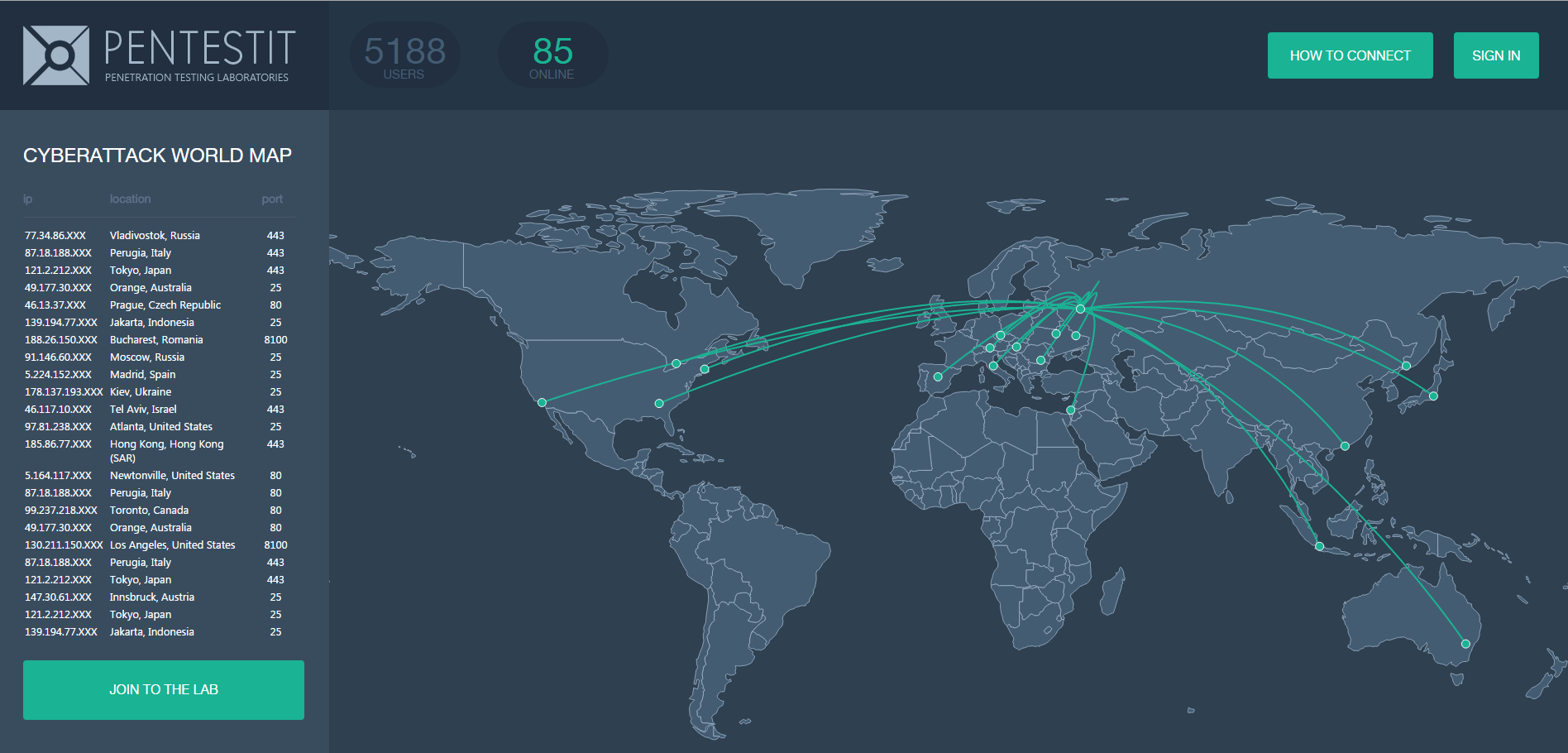
![][1] 13 ноября 2015 г. была запущена очередная, восьмая по счету лаборатория тестирования на проникновение [«Test lab v.8»][2], которая представляла собой виртуальный банк. К моменту открытия лаборатории количество зарегистрированных участников превышало отметку в 5 000. Ниже будет представлена информация о результатах участия и ИТ-структуре лаборатории, а также имена и комментарии победителей с частичным прохождением. Итак, начнем. [Читать дальше →][3]
[1]: https://habrastorage.org/files/fee/4a3/d92/fee4a3d9268a4a809b93b5e9a859b743.png
[2]: https://lab.pentestit.ru/pentestlabs/4
[3]: http://habrahabr.ru/post/272539/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 15:30:02
![][1] 13 ноября 2015 г. была запущена очередная, восьмая по счету лаборатория тестирования на проникновение [«Test lab v.8»][2], которая представляла собой виртуальный банк. К моменту открытия лаборатории количество зарегистрированных участников превышало отметку в 5 000. Ниже будет представлена информация о результатах участия и ИТ-структуре лаборатории, а также имена и комментарии победителей с частичным прохождением. Итак, начнем. [Читать дальше →][3]
[1]: https://habrastorage.org/files/fee/4a3/d92/fee4a3d9268a4a809b93b5e9a859b743.png
{kind=link}
[2]: https://lab.pentestit.ru/pentestlabs/4
[3]: http://habrahabr.ru/post/272539/#habracut
[>]
Шпаргалка Java-программиста 5. Двести пятьдесят русскоязычных обучающих видео докладов и лекций о Java
habra.15
habrabot(difrex,1) — All
2015-12-10 17:00:02
Думаю, мало кто будет спорить, что просмотр видео хороших лекций и докладов с конференций это один из самый быстрых и простых способов научится чему-то новому. Проблема в том, что по Java сложно найти все хорошие видео конференций и доклады по нужной теме. Более того, по названию многих видео с конференций сложно понять, какой именно они теме повещены. ![][1] Поэтому я подготовил данный сборник видео докладов на русском языке с различных конференций ([Joker][2], [JPoint][3], [JavaDays][4], [JEEConf][5], конечно, с [DEV labs][6], которые организовывает Luxoft), и, естественно, видео из канала [Luxoft Training Center][7]. Всё видео разделено на различные категории и при необходимости добавлено описание. [Читать дальше →][8]
[1]: https://habrastorage.org/files/6b1/35a/070/6b135a070120406eb0c62ab426228f2c.jpg
[2]: http://jokerconf.com
[3]: http://javapoint
[4]: http://javaday.org.ua/
[5]: http://jeeconf.com/materials/
[6]: http://www.soft-labs.net/ru/conf/DEV_labs_2015_Java_partII/
[7]: https://www.youtube.com/user/LuxoftTrainingCenter
[8]: http://habrahabr.ru/post/272025/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 17:00:02
Думаю, мало кто будет спорить, что просмотр видео хороших лекций и докладов с конференций это один из самый быстрых и простых способов научится чему-то новому. Проблема в том, что по Java сложно найти все хорошие видео конференций и доклады по нужной теме. Более того, по названию многих видео с конференций сложно понять, какой именно они теме повещены. ![][1] Поэтому я подготовил данный сборник видео докладов на русском языке с различных конференций ([Joker][2], [JPoint][3], [JavaDays][4], [JEEConf][5], конечно, с [DEV labs][6], которые организовывает Luxoft), и, естественно, видео из канала [Luxoft Training Center][7]. Всё видео разделено на различные категории и при необходимости добавлено описание. [Читать дальше →][8]
[1]: https://habrastorage.org/files/6b1/35a/070/6b135a070120406eb0c62ab426228f2c.jpg
{kind=link}
[2]: http://jokerconf.com
[3]: http://javapoint
[4]: http://javaday.org.ua/
[5]: http://jeeconf.com/materials/
[6]: http://www.soft-labs.net/ru/conf/DEV_labs_2015_Java_partII/
[7]: https://www.youtube.com/user/LuxoftTrainingCenter
[8]: http://habrahabr.ru/post/272025/#habracut
[>]
Школа Данных «Билайн», приоткрываем занавес
habra.15
habrabot(difrex,1) — All
2015-12-10 17:00:02
![][1] Привет, хабр! Вы уже много раз слышали про то, что мы проводим курсы машинного обучения и анализа данных в [Школе Данных «Билайн»][2]. Сегодня мы приоткроем занавес и расскажем, чему же учатся наши слушатели, и какие задачи им приходится решать. Итак, мы завершили наш первый курс. Сейчас идет второй и 25 января стартует третий. В [ предыдущих публикациях][3], мы уже начали рассказывать, чему мы учим на наших занятиях. Здесь мы более подробно поговорим о таких темах, как автоматическая обработка текстов, рекомендательные системы, анализ Больших Данных и успешное участие в соревнованиях Kaggle. [Читать дальше →][4]
[1]: https://habrastorage.org/files/93e/b67/737/93eb677375e444e9bca75a943e27d301.png
[2]: http://bigdata.beeline.digital
[3]: http://habrahabr.ru/company/beeline/blog/270619/
[4]: http://habrahabr.ru/post/272799/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 17:00:02
![][1] Привет, хабр! Вы уже много раз слышали про то, что мы проводим курсы машинного обучения и анализа данных в [Школе Данных «Билайн»][2]. Сегодня мы приоткроем занавес и расскажем, чему же учатся наши слушатели, и какие задачи им приходится решать. Итак, мы завершили наш первый курс. Сейчас идет второй и 25 января стартует третий. В [ предыдущих публикациях][3], мы уже начали рассказывать, чему мы учим на наших занятиях. Здесь мы более подробно поговорим о таких темах, как автоматическая обработка текстов, рекомендательные системы, анализ Больших Данных и успешное участие в соревнованиях Kaggle. [Читать дальше →][4]
[1]: https://habrastorage.org/files/93e/b67/737/93eb677375e444e9bca75a943e27d301.png
{kind=link}
[2]: http://bigdata.beeline.digital
[3]: http://habrahabr.ru/company/beeline/blog/270619/
[4]: http://habrahabr.ru/post/272799/#habracut
[>]
[Перевод] 2015 – год Cryptolocker, и как кибер-преступники совершенствовали свои атаки
habra.15
habrabot(difrex,1) — All
2015-12-10 19:30:02
![][1] В конце 2013 года появились первые признаки новых угроз, которые вскоре станут одним из самых прибыльных видов атак, осуществляемых кибер-преступниками. **Cryptolocker** – наиболее популярное семейство ransomware, которое в конечном итоге стало использоваться в качестве названия для всех угроз подобного типа. Эта угроза всегда работает по одному и тому же сценарию: шифрует документы и требует выкуп для того, чтобы восстановить зашифрованные документы. В этом году [мы уже писали][2] о принципах работы Cryptolocker. Кратко о том, каким образом происходит **шифрование файлов** уже после [Читать дальше →][3]
[1]: https://habrastorage.org/files/f08/723/f23/f08723f235094b419a9696bf4edeee06.jpg
[2]: http://club.cnews.ru/blogs/entry/cryptolocker_chto_eto_takoe_i_kak_ego_izbezhat
[3]: http://habrahabr.ru/post/272831/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 19:30:02
![][1] В конце 2013 года появились первые признаки новых угроз, которые вскоре станут одним из самых прибыльных видов атак, осуществляемых кибер-преступниками. **Cryptolocker** – наиболее популярное семейство ransomware, которое в конечном итоге стало использоваться в качестве названия для всех угроз подобного типа. Эта угроза всегда работает по одному и тому же сценарию: шифрует документы и требует выкуп для того, чтобы восстановить зашифрованные документы. В этом году [мы уже писали][2] о принципах работы Cryptolocker. Кратко о том, каким образом происходит **шифрование файлов** уже после [Читать дальше →][3]
[1]: https://habrastorage.org/files/f08/723/f23/f08723f235094b419a9696bf4edeee06.jpg
{kind=link}
[2]: http://club.cnews.ru/blogs/entry/cryptolocker_chto_eto_takoe_i_kak_ego_izbezhat
[3]: http://habrahabr.ru/post/272831/#habracut
[>]
Поднимаем сложный проект на Django с использованием Docker
habra.15
habrabot(difrex,1) — All
2015-12-10 19:30:02
Добрый день, коллеги. Сегодня я расскажу о не совсем простой концепции быстрого (до часа после нескольких тренировок) развёртывания проекта для работы команды, состоящей как минимум из отдельных фронтенд и бэкенд разработчиков. Исходные данные у нас такие: начинается разработка проекта, в которой планируется «тонкий бэкенд». Т.е. бэк у нас состоит из закешированных страниц (рендерятся любым шаблонизатором), объёмных моделей с сопутствующей логикой (ORM) и REST API, выполняющего роль контроллера. Фактически, View в такой системе редуцировано и вынесено в JS, благо есть разные реакты, ангуляры и прочие вещи, которые позволяют фронтендщикам считать себя «белыми людьми». [Читать дальше →][1]
[1]: http://habrahabr.ru/post/272811/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 19:30:02
Добрый день, коллеги. Сегодня я расскажу о не совсем простой концепции быстрого (до часа после нескольких тренировок) развёртывания проекта для работы команды, состоящей как минимум из отдельных фронтенд и бэкенд разработчиков. Исходные данные у нас такие: начинается разработка проекта, в которой планируется «тонкий бэкенд». Т.е. бэк у нас состоит из закешированных страниц (рендерятся любым шаблонизатором), объёмных моделей с сопутствующей логикой (ORM) и REST API, выполняющего роль контроллера. Фактически, View в такой системе редуцировано и вынесено в JS, благо есть разные реакты, ангуляры и прочие вещи, которые позволяют фронтендщикам считать себя «белыми людьми». [Читать дальше →][1]
[1]: http://habrahabr.ru/post/272811/#habracut
[>]
Фишинговые приложения для Вконтакте на Google Play
habra.15
habrabot(difrex,1) — All
2015-12-10 19:30:02
Пару месяцев назад лаборатория Каспеского опубликовала [статью][1] о фишинге аккаунтов ВК в Google Play, но не рассказали как это реализовано и почему такие приложения задерживаются в маркете. В их статье говорилось о том, что около 1 миллиона пользователей могли стать жертвами фишинга. Примерно те же приложения я реверсила еще весной. Я тогда поспорила с другом, что в маркете есть вредоносные приложения. Вредоносные приложения найти не получилось, нашлись только фейки для “Вконтакте”. Но возможно, просто мало искала. Но сейчас и их в маркете найти уже не удалось, скорее всего они были удалены, после обнаружения Лабораторией Касперского. [Читать дальше →][2]
[1]: http://habrahabr.ru/post/268581/
[2]: http://habrahabr.ru/post/272783/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 19:30:02
Пару месяцев назад лаборатория Каспеского опубликовала [статью][1] о фишинге аккаунтов ВК в Google Play, но не рассказали как это реализовано и почему такие приложения задерживаются в маркете. В их статье говорилось о том, что около 1 миллиона пользователей могли стать жертвами фишинга. Примерно те же приложения я реверсила еще весной. Я тогда поспорила с другом, что в маркете есть вредоносные приложения. Вредоносные приложения найти не получилось, нашлись только фейки для “Вконтакте”. Но возможно, просто мало искала. Но сейчас и их в маркете найти уже не удалось, скорее всего они были удалены, после обнаружения Лабораторией Касперского. [Читать дальше →][2]
[1]: http://habrahabr.ru/post/268581/
[2]: http://habrahabr.ru/post/272783/#habracut
[>]
Материалы расследования: «200 лет со дня рождения Ады Лавлейс, первого программиста человечества»
habra.15
habrabot(difrex,1) — All
2015-12-10 20:00:02
_**Дата:** 10 декабря 2015 года, начальнику отдела №8 от следователя id1033. **Тип запроса:** инициация расследования. **Причина:** в связи с подозрительной активность юзера id1596704383 в период с 30 июля 2005 по 9 декабря 2015, прошу предоставить необходимые ресурсы по Форме 2 и наделить полномочиями в соответствии с протоколом «Observer-z». **Обоснование:** на основе данных, полученных из открытых источников системой аналитики ПОПСИИ-2014 («Можжевельник») были выявлены уникальные сигнатуры (присвоены идентификаторы с sig8876 по sig8951), свидетельствующие об активном сборе и аналитике материалов из сети из разряда «Первоисточник-18». Согласно распоряжению от 20 ноября 2015, докладывать незамедлительно о любой активности в реальности связанной с «Первоисточник-18», уведомляю, что 10 декабря в 16-00 по московскому времени, юзер id1596704383 перешел к активным действиям в реальности. К запросу прилагаю материалы, перехваченные из черновиков юзера id1596704383 10 декабря 2015 года на публичном ресурсе «Habrahabr»._ ![][1] _«Я — дьявол или ангел» (Ада Лавлейс, из письма Чарльзу Бэббиджу 1843) _ **200 лет со дня рождения Ады Лавлейс, первого программиста человечества** 10 декабря 1815 года у поэта Байрона [родилась дочка][2], которая в 1842 году в свои 27 лет написала первую программу для [вычислительной машины (паровой) Бэббиджа][3].
> _«Суть и предназначение машины изменятся от того, какую информацию мы в нее вложим. Машина сможет писать музыку, рисовать картины и покажет науке такие пути, которые мы никогда и нигде не видели.» Ада Лавлейс_
**Ada** — язык программирования, созданный в 1979—1980 годах в ходе проекта Министерством обороны США с целью разработать единый язык программирования для встроенных систем (то есть систем управления автоматизированными комплексами, функционирующими в реальном времени). Имелись в виду, прежде всего, бортовые системы управления военными объектами (кораблями, самолётами, танками, ракетами, снарядами и т. п.). 10 декабря 1980 года был утверждён стандарт языка. [Читать дальше →][4]
[1]: https://habrastorage.org/files/a66/41e/d80/a6641ed802004c4d91dbc8070cc1b5c6.jpg
[2]: http://geektimes.ru/post/80800/
[3]: http://habrahabr.ru/post/80334/
[4]: http://habrahabr.ru/post/272841/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-10 20:00:02
_**Дата:** 10 декабря 2015 года, начальнику отдела №8 от следователя id1033. **Тип запроса:** инициация расследования. **Причина:** в связи с подозрительной активность юзера id1596704383 в период с 30 июля 2005 по 9 декабря 2015, прошу предоставить необходимые ресурсы по Форме 2 и наделить полномочиями в соответствии с протоколом «Observer-z». **Обоснование:** на основе данных, полученных из открытых источников системой аналитики ПОПСИИ-2014 («Можжевельник») были выявлены уникальные сигнатуры (присвоены идентификаторы с sig8876 по sig8951), свидетельствующие об активном сборе и аналитике материалов из сети из разряда «Первоисточник-18». Согласно распоряжению от 20 ноября 2015, докладывать незамедлительно о любой активности в реальности связанной с «Первоисточник-18», уведомляю, что 10 декабря в 16-00 по московскому времени, юзер id1596704383 перешел к активным действиям в реальности. К запросу прилагаю материалы, перехваченные из черновиков юзера id1596704383 10 декабря 2015 года на публичном ресурсе «Habrahabr»._ ![][1] _«Я — дьявол или ангел» (Ада Лавлейс, из письма Чарльзу Бэббиджу 1843) _ **200 лет со дня рождения Ады Лавлейс, первого программиста человечества** 10 декабря 1815 года у поэта Байрона [родилась дочка][2], которая в 1842 году в свои 27 лет написала первую программу для [вычислительной машины (паровой) Бэббиджа][3].
> _«Суть и предназначение машины изменятся от того, какую информацию мы в нее вложим. Машина сможет писать музыку, рисовать картины и покажет науке такие пути, которые мы никогда и нигде не видели.» Ада Лавлейс_
**Ada** — язык программирования, созданный в 1979—1980 годах в ходе проекта Министерством обороны США с целью разработать единый язык программирования для встроенных систем (то есть систем управления автоматизированными комплексами, функционирующими в реальном времени). Имелись в виду, прежде всего, бортовые системы управления военными объектами (кораблями, самолётами, танками, ракетами, снарядами и т. п.). 10 декабря 1980 года был утверждён стандарт языка. [Читать дальше →][4]
[1]: https://habrastorage.org/files/a66/41e/d80/a6641ed802004c4d91dbc8070cc1b5c6.jpg
{kind=link}
[2]: http://geektimes.ru/post/80800/
[3]: http://habrahabr.ru/post/80334/
[4]: http://habrahabr.ru/post/272841/#habracut
[>]
В антивирусе Avast обнаружены и устранены критические уязвимости
habra.15
habrabot(difrex,1) — All
2015-12-11 03:30:02
[![][1]][2] Летом 2015 года пользователи интернета широко обсуждали проблемы безопасности антивирусных инструментов. Напомним, тогда серьезные уязвимости были [обнаружены][3] в продуктах ESET, а затем и в [BitDefender с Symantec][4]. На текущей неделе стало известно об очередных проблемах с защитой антивирусного софта. Один из пользователей ресурса Google Code опубликовал описания и тестовые сценарии эксплуатации четырех серьезных уязвимостей антивируса Avast, две из которых являются критическими. [Читать дальше →][5]
[1]: https://habrastorage.org/files/ab2/d17/422/ab2d174220bf4f3782f11f5314a3dac0.jpg
[2]: http://habrahabr.ru/company/pt/blog/272851/
[3]: http://habrahabr.ru/company/pt/blog/261075/
[4]: http://habrahabr.ru/company/pt/blog/264013/
[5]: http://habrahabr.ru/post/272851/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 03:30:02
[![][1]][2] Летом 2015 года пользователи интернета широко обсуждали проблемы безопасности антивирусных инструментов. Напомним, тогда серьезные уязвимости были [обнаружены][3] в продуктах ESET, а затем и в [BitDefender с Symantec][4]. На текущей неделе стало известно об очередных проблемах с защитой антивирусного софта. Один из пользователей ресурса Google Code опубликовал описания и тестовые сценарии эксплуатации четырех серьезных уязвимостей антивируса Avast, две из которых являются критическими. [Читать дальше →][5]
[1]: https://habrastorage.org/files/ab2/d17/422/ab2d174220bf4f3782f11f5314a3dac0.jpg
{kind=link}
[2]: http://habrahabr.ru/company/pt/blog/272851/
[3]: http://habrahabr.ru/company/pt/blog/261075/
[4]: http://habrahabr.ru/company/pt/blog/264013/
[5]: http://habrahabr.ru/post/272851/#habracut
[>]
Как я 8 месяцев переписывал свою криптовалюту с PHP на Go. Часть 1
habra.15
habrabot(difrex,1) — All
2015-12-11 12:30:02
![][1] «Не звони и не пиши мне больше!!!!» — пришла смс-ка от моей девушки Кати. Через пару часов я осознал, что теперь у меня появилась куча свободного времени и я решил переписать Dcoin на Go. [Читать дальше →][2]
[1]: https://habrastorage.org/files/912/ce1/f48/912ce1f48a75415fb529d933668ed3bd.jpeg
[2]: http://habrahabr.ru/post/272695/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 12:30:02
![][1] «Не звони и не пиши мне больше!!!!» — пришла смс-ка от моей девушки Кати. Через пару часов я осознал, что теперь у меня появилась куча свободного времени и я решил переписать Dcoin на Go. [Читать дальше →][2]
[1]: https://habrastorage.org/files/912/ce1/f48/912ce1f48a75415fb529d933668ed3bd.jpeg
{kind=link}
[2]: http://habrahabr.ru/post/272695/#habracut
[>]
В антивирусе Avast обнаружены критические уязвимости
habra.15
habrabot(difrex,1) — All
2015-12-11 13:30:02
[![][1]][2] Летом 2015 года пользователи интернета широко обсуждали проблемы безопасности антивирусных инструментов. Напомним, тогда серьезные уязвимости были [обнаружены][3] в продуктах ESET, а затем и в [BitDefender с Symantec][4]. На текущей неделе стало известно об очередных проблемах с защитой антивирусного софта. Один из пользователей ресурса Google Code опубликовал описания и тестовые сценарии эксплуатации четырех серьезных уязвимостей антивируса Avast, две из которых являются критическими. [Читать дальше →][5]
[1]: https://habrastorage.org/files/ab2/d17/422/ab2d174220bf4f3782f11f5314a3dac0.jpg
[2]: http://habrahabr.ru/company/pt/blog/272851/
[3]: http://habrahabr.ru/company/pt/blog/261075/
[4]: http://habrahabr.ru/company/pt/blog/264013/
[5]: http://habrahabr.ru/post/272851/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 13:30:02
[![][1]][2] Летом 2015 года пользователи интернета широко обсуждали проблемы безопасности антивирусных инструментов. Напомним, тогда серьезные уязвимости были [обнаружены][3] в продуктах ESET, а затем и в [BitDefender с Symantec][4]. На текущей неделе стало известно об очередных проблемах с защитой антивирусного софта. Один из пользователей ресурса Google Code опубликовал описания и тестовые сценарии эксплуатации четырех серьезных уязвимостей антивируса Avast, две из которых являются критическими. [Читать дальше →][5]
[1]: https://habrastorage.org/files/ab2/d17/422/ab2d174220bf4f3782f11f5314a3dac0.jpg
[2]: http://habrahabr.ru/company/pt/blog/272851/
[3]: http://habrahabr.ru/company/pt/blog/261075/
[4]: http://habrahabr.ru/company/pt/blog/264013/
[5]: http://habrahabr.ru/post/272851/#habracut
[>]
[Перевод] Первые шаги с Java 9 и проект Jigsaw – часть вторая
habra.15
habrabot(difrex,1) — All
2015-12-11 16:00:02
Здравствуйте, Хабр. После некоторого промедления публикуем вторую часть статьи о проекте Jigsaw и Java 9, вышедшую в блоге Codecentric. Перевод первой части находится [здесь][1]. [Читать дальше →][2]
[1]: http://habrahabr.ru/company/piter/blog/271941/
[2]: http://habrahabr.ru/post/272861/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 16:00:02
Здравствуйте, Хабр. После некоторого промедления публикуем вторую часть статьи о проекте Jigsaw и Java 9, вышедшую в блоге Codecentric. Перевод первой части находится [здесь][1]. [Читать дальше →][2]
[1]: http://habrahabr.ru/company/piter/blog/271941/
[2]: http://habrahabr.ru/post/272861/#habracut
[>]
Саундсквоттинг — новый вид мошенничества с доменами
habra.15
habrabot(difrex,1) — All
2015-12-11 19:00:01
Появилась новая разновидность киберсквоттинга, именуемая **саундсквоттингом** (от англ. «soundsquatting»). Суть действия также заключается в противоправном использовании доменных имен, только с помощью омофонов — слов одинакового звучания и при этом разного написания (например, «eight» и «ate» — пишутся по-разному, а на слух их различить сложно). Интернет-мошенники или саундсквоттеры выбирают популярные домены и находят к ним созвучные имена. В результате они получают сайты, которым гарантирована посещаемость благодаря созвучному сходству с популярными ресурсами. ![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/6a7/b6f/650/6a7b6f650469463a8720b7ed78f707a5.png
[2]: http://habrahabr.ru/post/272849/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 19:00:01
Появилась новая разновидность киберсквоттинга, именуемая **саундсквоттингом** (от англ. «soundsquatting»). Суть действия также заключается в противоправном использовании доменных имен, только с помощью омофонов — слов одинакового звучания и при этом разного написания (например, «eight» и «ate» — пишутся по-разному, а на слух их различить сложно). Интернет-мошенники или саундсквоттеры выбирают популярные домены и находят к ним созвучные имена. В результате они получают сайты, которым гарантирована посещаемость благодаря созвучному сходству с популярными ресурсами. ![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/6a7/b6f/650/6a7b6f650469463a8720b7ed78f707a5.png
{kind=link}
[2]: http://habrahabr.ru/post/272849/#habracut
[>]
[Из песочницы] О том, как я неделю вдуплял в Bareos
habra.15
habrabot(difrex,1) — All
2015-12-11 20:30:01
Попала ко мне задача организовать резервное копирование с GUI и чтобы прям как у больших дядек. Ранее стоял rsnapshot и всё работало чудесно пока объёмы не возросли до сотен гигабайт, сайты и базы данных, сотни тестовых площадок. Увеличился парк серверов и управлять всем этим делом стало трудно. Из всех имеющихся решений мы выбирали опенсорс и остановились на bareos как на самом часто используемом, чтобы в случае чего быстренько загуглить. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/272869/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 20:30:01
Попала ко мне задача организовать резервное копирование с GUI и чтобы прям как у больших дядек. Ранее стоял rsnapshot и всё работало чудесно пока объёмы не возросли до сотен гигабайт, сайты и базы данных, сотни тестовых площадок. Увеличился парк серверов и управлять всем этим делом стало трудно. Из всех имеющихся решений мы выбирали опенсорс и остановились на bareos как на самом часто используемом, чтобы в случае чего быстренько загуглить. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/272869/#habracut
[>]
Security Week 50: DDoS корневых DNS-серверов, жизнь APT Sofacy, много криптографии
habra.15
habrabot(difrex,1) — All
2015-12-11 20:30:01
![][1]Серьезные перемены происходят ровно в тот момент, когда процент желающих что-то изменить превышает определенную критическую отметку. Нет, я сейчас не про политику, чур меня и свят-свят, а про IT в целом и IT-безопасность. И хотят в общем-то все разного: компании — чтобы не DDoS-или и не ломали, пользователи — чтобы не крали пароли и не угоняли аккаунты, security-вендоры — нового отношения к безопасности у всех заинтересованных лиц, регуляторы — ну понятно, хотят регулировать. Вот краткая выжимка [предсказаний][2] наших экспертов на будущий год: эволюция APT (меньше технологий, больше массовости и вообще снижение издержек), атаки на новые финансовые инструменты а-ля ApplePay и фондовые биржи — поближе к местам высокой концентрации цифровых дензнаков, атаки на самих ИБ-исследователей через применяемые ими инструменты, взлом компаний ради чистого ущерба репутации (а.к.а. вывешивание грязного белья), дефицит доверия любым IT-инструментам (взломать могут все, что угодно), включая доверенные сертификаты, ботнеты из маршрутизаторов и прочих IoT, масштабный кризис криптографии. В предсказаниях этого года нет ни единого пункта «на вырост», ни одного маловероятного сценария развития. Ну разве что к таковым можно отнести атаки на управляемые компьютером автомобили, да и то речь идет о взломе инфраструктуры, от которой они зависят — сотовых и спутниковых сетей. Все это, в той или иной степени, сбудется, проблема в том, что _как-то не хочется_. По возможности хотелось бы этого всего _избежать_. А если хочется не только нам, но и вообще всем (пусть и по-разному), то может ли 2016-й также стать годом прогресса в коллективной IT-безопасности? Я ни разу не эксперт, но хочется верить, что да. Переходим к новостям недели. Предыдущие выпуски [доступны по тегу][3]. [Читать дальше →][4]
[1]: https://habrastorage.org/files/66e/161/b90/66e161b90f17441cb6da4de514790879.jpg
[2]: https://securelist.ru/analysis/ksb/27454/kaspersky-security-bulletin-2015-prognozy-na-2016-god/
[3]: http://habrahabr.ru/search/?target_type=posts&q=%5Bklsw%5D%20&order_by=date
[4]: http://habrahabr.ru/post/272855/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 20:30:01
![][1]Серьезные перемены происходят ровно в тот момент, когда процент желающих что-то изменить превышает определенную критическую отметку. Нет, я сейчас не про политику, чур меня и свят-свят, а про IT в целом и IT-безопасность. И хотят в общем-то все разного: компании — чтобы не DDoS-или и не ломали, пользователи — чтобы не крали пароли и не угоняли аккаунты, security-вендоры — нового отношения к безопасности у всех заинтересованных лиц, регуляторы — ну понятно, хотят регулировать. Вот краткая выжимка [предсказаний][2] наших экспертов на будущий год: эволюция APT (меньше технологий, больше массовости и вообще снижение издержек), атаки на новые финансовые инструменты а-ля ApplePay и фондовые биржи — поближе к местам высокой концентрации цифровых дензнаков, атаки на самих ИБ-исследователей через применяемые ими инструменты, взлом компаний ради чистого ущерба репутации (а.к.а. вывешивание грязного белья), дефицит доверия любым IT-инструментам (взломать могут все, что угодно), включая доверенные сертификаты, ботнеты из маршрутизаторов и прочих IoT, масштабный кризис криптографии. В предсказаниях этого года нет ни единого пункта «на вырост», ни одного маловероятного сценария развития. Ну разве что к таковым можно отнести атаки на управляемые компьютером автомобили, да и то речь идет о взломе инфраструктуры, от которой они зависят — сотовых и спутниковых сетей. Все это, в той или иной степени, сбудется, проблема в том, что _как-то не хочется_. По возможности хотелось бы этого всего _избежать_. А если хочется не только нам, но и вообще всем (пусть и по-разному), то может ли 2016-й также стать годом прогресса в коллективной IT-безопасности? Я ни разу не эксперт, но хочется верить, что да. Переходим к новостям недели. Предыдущие выпуски [доступны по тегу][3]. [Читать дальше →][4]
[1]: https://habrastorage.org/files/66e/161/b90/66e161b90f17441cb6da4de514790879.jpg
{kind=link}
[2]: https://securelist.ru/analysis/ksb/27454/kaspersky-security-bulletin-2015-prognozy-na-2016-god/
[3]: http://habrahabr.ru/search/?target_type=posts&q=%5Bklsw%5D%20&order_by=date
[4]: http://habrahabr.ru/post/272855/#habracut
[>]
Как подружить Linq-to-Entities и Regex
habra.15
habrabot(difrex,1) — All
2015-12-11 21:00:02
_Entity Framework_ сильно облегчает разработку систем, использующих базы данных. Не будем сейчас спорить о достоинствах и недостатках этого фреймворка (коих, конечно, немало), а рассмотрим одну из практических задач, которую мне пришлось решать при разработке такой системы. Предположим, у нас есть база данных _SQLite_ с довольно большим количеством записей, и эта база используется в нашем _.NET_ приложении через [System.Data.SQLite][1] и [Entity Framework 6.0][2]. И вот приходит заказчик и сообщает, что ему нужна новая функция поиска записей в базе, да такая, чтобы можно было искать с использованием стандартных регулярных выражений. В этой статье я расскажу, как я добился того, что процессинг регулярного выражения, задаваемого в _Linq_-запросе, происходит на стороне сервера, что позволяет ускорить его обработку и не допустить бессмысленного раздувания памяти клиентского приложения из-за предварительного скачивания всех данных. [Читать дальше →][3]
[1]: https://system.data.sqlite.org
[2]: https://msdn.microsoft.com/en-us/data/aa937723
[3]: http://habrahabr.ru/post/272917/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 21:00:02
_Entity Framework_ сильно облегчает разработку систем, использующих базы данных. Не будем сейчас спорить о достоинствах и недостатках этого фреймворка (коих, конечно, немало), а рассмотрим одну из практических задач, которую мне пришлось решать при разработке такой системы. Предположим, у нас есть база данных _SQLite_ с довольно большим количеством записей, и эта база используется в нашем _.NET_ приложении через [System.Data.SQLite][1] и [Entity Framework 6.0][2]. И вот приходит заказчик и сообщает, что ему нужна новая функция поиска записей в базе, да такая, чтобы можно было искать с использованием стандартных регулярных выражений. В этой статье я расскажу, как я добился того, что процессинг регулярного выражения, задаваемого в _Linq_-запросе, происходит на стороне сервера, что позволяет ускорить его обработку и не допустить бессмысленного раздувания памяти клиентского приложения из-за предварительного скачивания всех данных. [Читать дальше →][3]
[1]: https://system.data.sqlite.org
[2]: https://msdn.microsoft.com/en-us/data/aa937723
[3]: http://habrahabr.ru/post/272917/#habracut
[>]
[Перевод] DASH “Эволюция” анонсирована как “Социальная платёжная сеть”
habra.15
habrabot(difrex,1) — All
2015-12-11 21:00:02
[![image][1]][2] Эван Даффилд (Evan Duffield), создатель и ведущий разработчик [криптовалюты DASH][3] (текущий рейтинг — №5 по капитализации), раскрыл планы по развитию следующего поколения DASH “Evolution” на ежегодной Латино-Американской Биткоин конференции LaBitconf-2015. Следующий этап развития этой криптовалюты реализует: Децентрализованное хранение персональной информации, Социальный функционал, Защищённую идентичность, Децентрализованный API (DAPI) и много другое. В ходе видео-интервью на LaBitconf-2015, Эван Даффилд рассказывает о планах по развитию DASH, нацеленных на создание “Paypal-подобного” функционала у цифровой валюты (криптовалюты), что должно обеспечить рядовым пользователям значительные преимущества в плане простоты использования и т.д. [Читать дальше →][4]
[1]: https://habrastorage.org/files/c2d/f15/76a/c2df1576a80e47169f6a9f13da342ac9.jpg
[2]: http://habrahabr.ru/post/272915/
[3]: https://www.dash.org/ru/
[4]: http://habrahabr.ru/post/272915/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-11 21:00:02
[![image][1]][2] Эван Даффилд (Evan Duffield), создатель и ведущий разработчик [криптовалюты DASH][3] (текущий рейтинг — №5 по капитализации), раскрыл планы по развитию следующего поколения DASH “Evolution” на ежегодной Латино-Американской Биткоин конференции LaBitconf-2015. Следующий этап развития этой криптовалюты реализует: Децентрализованное хранение персональной информации, Социальный функционал, Защищённую идентичность, Децентрализованный API (DAPI) и много другое. В ходе видео-интервью на LaBitconf-2015, Эван Даффилд рассказывает о планах по развитию DASH, нацеленных на создание “Paypal-подобного” функционала у цифровой валюты (криптовалюты), что должно обеспечить рядовым пользователям значительные преимущества в плане простоты использования и т.д. [Читать дальше →][4]
[1]: https://habrastorage.org/files/c2d/f15/76a/c2df1576a80e47169f6a9f13da342ac9.jpg
{kind=link}
[2]: http://habrahabr.ru/post/272915/
[3]: https://www.dash.org/ru/
[4]: http://habrahabr.ru/post/272915/#habracut
[>]
[Перевод] DASH «Эволюция» анонсирована как «Социальная платёжная сеть»
habra.15
habrabot(difrex,1) — All
2015-12-12 01:00:02
[![image][1]][2] Эван Даффилд (Evan Duffield), создатель и ведущий разработчик [криптовалюты DASH][3] (текущий рейтинг — №5 по капитализации), раскрыл планы по развитию следующего поколения DASH “Evolution” на ежегодной Латино-Американской Биткоин конференции LaBitconf-2015. Следующий этап развития этой криптовалюты реализует: Децентрализованное хранение персональной информации, Социальный функционал, Защищённую идентичность, Децентрализованный API (DAPI) и много другое. В ходе видео-интервью на LaBitconf-2015, Эван Даффилд рассказывает о планах по развитию DASH, нацеленных на создание “Paypal-подобного” функционала у цифровой валюты (криптовалюты), что должно обеспечить рядовым пользователям значительные преимущества в плане простоты использования и т.д. [Читать дальше →][4]
[1]: https://habrastorage.org/files/c2d/f15/76a/c2df1576a80e47169f6a9f13da342ac9.jpg
[2]: http://habrahabr.ru/post/272915/
[3]: https://www.dash.org/ru/
[4]: http://habrahabr.ru/post/272915/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-12 01:00:02
[![image][1]][2] Эван Даффилд (Evan Duffield), создатель и ведущий разработчик [криптовалюты DASH][3] (текущий рейтинг — №5 по капитализации), раскрыл планы по развитию следующего поколения DASH “Evolution” на ежегодной Латино-Американской Биткоин конференции LaBitconf-2015. Следующий этап развития этой криптовалюты реализует: Децентрализованное хранение персональной информации, Социальный функционал, Защищённую идентичность, Децентрализованный API (DAPI) и много другое. В ходе видео-интервью на LaBitconf-2015, Эван Даффилд рассказывает о планах по развитию DASH, нацеленных на создание “Paypal-подобного” функционала у цифровой валюты (криптовалюты), что должно обеспечить рядовым пользователям значительные преимущества в плане простоты использования и т.д. [Читать дальше →][4]
[1]: https://habrastorage.org/files/c2d/f15/76a/c2df1576a80e47169f6a9f13da342ac9.jpg
[2]: http://habrahabr.ru/post/272915/
[3]: https://www.dash.org/ru/
[4]: http://habrahabr.ru/post/272915/#habracut
[>]
Про открытые данные, проектах и на их основе и о том что происходит с открытыми государственными данными в России
habra.15
habrabot(difrex,1) — All
2015-12-12 21:00:02
![][1] Кто-то возможно знает, для кого-то может быть новостью, но вчера и позавчера в России завершился саммит по открытым данным. И по его итогам, а также по итогам года я понимаю, что пора рассказать о том, что творится с открытыми данными и с другими частями открытости нашего государства. К тому же мой опыт (и опыт вот уже очень долгий) создания проектов на открытых данных очень сильно отличается от слов чиновников и политиков, которые можно услышать на таких публичных мероприятиях. Начну с саммита. **Саммит по открытым данным** На фоне всех остальных мероприятий по открытым данным за последние годы — это одно из первых организованных на довольно хорошем уровне. Даже на «совете по открытым данным» в Яндексе в июне 2015 года было очень много непрофильных выступлений, подробнее в заметке "[Приоткрытые данные][2]" в этот же раз все не отходили от темы открытых данных и это главный и важный плюс всего произошедшего. В плюсы я могу записать также те части саммита в которых я участвовал. Это были круглые столы посвящённые темам криминальной статистики и востребованности государственных финансов. Если коротко, то видно что эти данные нужны и востребованы. На круглом столе про востребованность госфинансов вообще очень много было вопросов про информацию связанную с открытыми данными по госзакупкам. Подробнее и отдельно я напишу ещё про эти круглые столы, но суть общая что данные будут и что ведомства — готовы к диалогу с потребителями. Плюс у меня просто руки не доходят рассказать про все проходящие мероприятия связанные с открытыми данными — встречи с разработчиками, заседания общественных советов и так далее. Я обязательно всё напишу, материалы копятся и тексты пишутся. А теперь о том что у нас происходит с открытыми данными. [Читать дальше →][3]
[1]: https://habrastorage.org/files/0ba/571/3d9/0ba5713d9f3b4893b2f8d48b239614c9.jpg
[2]: http://habrahabr.ru/company/infoculture/blog/260389/
[3]: http://habrahabr.ru/post/272965/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-12 21:00:02
![][1] Кто-то возможно знает, для кого-то может быть новостью, но вчера и позавчера в России завершился саммит по открытым данным. И по его итогам, а также по итогам года я понимаю, что пора рассказать о том, что творится с открытыми данными и с другими частями открытости нашего государства. К тому же мой опыт (и опыт вот уже очень долгий) создания проектов на открытых данных очень сильно отличается от слов чиновников и политиков, которые можно услышать на таких публичных мероприятиях. Начну с саммита. **Саммит по открытым данным** На фоне всех остальных мероприятий по открытым данным за последние годы — это одно из первых организованных на довольно хорошем уровне. Даже на «совете по открытым данным» в Яндексе в июне 2015 года было очень много непрофильных выступлений, подробнее в заметке "[Приоткрытые данные][2]" в этот же раз все не отходили от темы открытых данных и это главный и важный плюс всего произошедшего. В плюсы я могу записать также те части саммита в которых я участвовал. Это были круглые столы посвящённые темам криминальной статистики и востребованности государственных финансов. Если коротко, то видно что эти данные нужны и востребованы. На круглом столе про востребованность госфинансов вообще очень много было вопросов про информацию связанную с открытыми данными по госзакупкам. Подробнее и отдельно я напишу ещё про эти круглые столы, но суть общая что данные будут и что ведомства — готовы к диалогу с потребителями. Плюс у меня просто руки не доходят рассказать про все проходящие мероприятия связанные с открытыми данными — встречи с разработчиками, заседания общественных советов и так далее. Я обязательно всё напишу, материалы копятся и тексты пишутся. А теперь о том что у нас происходит с открытыми данными. [Читать дальше →][3]
[1]: https://habrastorage.org/files/0ba/571/3d9/0ba5713d9f3b4893b2f8d48b239614c9.jpg
{kind=link}
[2]: http://habrahabr.ru/company/infoculture/blog/260389/
[3]: http://habrahabr.ru/post/272965/#habracut
[>]
Про открытые данные, проектах на их основе и о том что происходит с открытыми государственными данными в России
habra.15
habrabot(difrex,1) — All
2015-12-13 01:00:03
![][1] Кто-то возможно знает, для кого-то может быть новостью, но вчера и позавчера в России завершился саммит по открытым данным. И по его итогам, а также по итогам года я понимаю, что пора рассказать о том, что творится с открытыми данными и с другими частями открытости нашего государства. К тому же мой опыт (и опыт вот уже очень долгий) создания проектов на открытых данных очень сильно отличается от слов чиновников и политиков, которые можно услышать на таких публичных мероприятиях. Начну с саммита. **Саммит по открытым данным** На фоне всех остальных мероприятий по открытым данным за последние годы — это одно из первых организованных на довольно хорошем уровне. Даже на «совете по открытым данным» в Яндексе в июне 2015 года было очень много непрофильных выступлений, подробнее в заметке "[Приоткрытые данные][2]" в этот же раз все не отходили от темы открытых данных и это главный и важный плюс всего произошедшего. В плюсы я могу записать также те части саммита в которых я участвовал. Это были круглые столы посвящённые темам криминальной статистики и востребованности государственных финансов. Если коротко, то видно что эти данные нужны и востребованы. На круглом столе про востребованность госфинансов вообще очень много было вопросов про информацию связанную с открытыми данными по госзакупкам. Подробнее и отдельно я напишу ещё про эти круглые столы, но суть общая что данные будут и что ведомства — готовы к диалогу с потребителями. Плюс у меня просто руки не доходят рассказать про все проходящие мероприятия связанные с открытыми данными — встречи с разработчиками, заседания общественных советов и так далее. Я обязательно всё напишу, материалы копятся и тексты пишутся. А теперь о том что у нас происходит с открытыми данными. [Читать дальше →][3]
[1]: https://habrastorage.org/files/0ba/571/3d9/0ba5713d9f3b4893b2f8d48b239614c9.jpg
[2]: http://habrahabr.ru/company/infoculture/blog/260389/
[3]: http://habrahabr.ru/post/272965/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-13 01:00:03
![][1] Кто-то возможно знает, для кого-то может быть новостью, но вчера и позавчера в России завершился саммит по открытым данным. И по его итогам, а также по итогам года я понимаю, что пора рассказать о том, что творится с открытыми данными и с другими частями открытости нашего государства. К тому же мой опыт (и опыт вот уже очень долгий) создания проектов на открытых данных очень сильно отличается от слов чиновников и политиков, которые можно услышать на таких публичных мероприятиях. Начну с саммита. **Саммит по открытым данным** На фоне всех остальных мероприятий по открытым данным за последние годы — это одно из первых организованных на довольно хорошем уровне. Даже на «совете по открытым данным» в Яндексе в июне 2015 года было очень много непрофильных выступлений, подробнее в заметке "[Приоткрытые данные][2]" в этот же раз все не отходили от темы открытых данных и это главный и важный плюс всего произошедшего. В плюсы я могу записать также те части саммита в которых я участвовал. Это были круглые столы посвящённые темам криминальной статистики и востребованности государственных финансов. Если коротко, то видно что эти данные нужны и востребованы. На круглом столе про востребованность госфинансов вообще очень много было вопросов про информацию связанную с открытыми данными по госзакупкам. Подробнее и отдельно я напишу ещё про эти круглые столы, но суть общая что данные будут и что ведомства — готовы к диалогу с потребителями. Плюс у меня просто руки не доходят рассказать про все проходящие мероприятия связанные с открытыми данными — встречи с разработчиками, заседания общественных советов и так далее. Я обязательно всё напишу, материалы копятся и тексты пишутся. А теперь о том что у нас происходит с открытыми данными. [Читать дальше →][3]
[1]: https://habrastorage.org/files/0ba/571/3d9/0ba5713d9f3b4893b2f8d48b239614c9.jpg
[2]: http://habrahabr.ru/company/infoculture/blog/260389/
[3]: http://habrahabr.ru/post/272965/#habracut
[>]
Игры, которые учат программированию
habra.15
habrabot(difrex,1) — All
2015-12-13 20:30:03
![][1] Образование стоит дорого. Хорошее образование стоит очень дорого. Но тем не менее возможность получить бесплатное и качественное образование есть у каждого. Компании и корпорации во всём мире вкладывают деньги в создание бесплатных образовательных продуктов. Отчасти, чтобы обеспечить себя квалифицированными кадрами в будущем. Отчасти, для преодоления бедности, предоставления всем равного доступ к качественному образованию. У каждого есть возможность воспользоваться специально созданной для обучения школьников средой программирования Scratch, которую разрабатывают специалисты одного из самых престижных технических учебных заведений США и мира — Массачусетского технологического института. Или игрой Minecraft, за которую Microsoft год назад заплатила $2,5 млрд и с помощью которой, в том числе, планирует обучать детей программированию. Или обучающими играми, которые создают энтузиасты и добровольцы во всём мире. Препятствием для использования подобных ресурсов может быть неосведомлённость о их существовании или незнание языка. Действительно, англоязычных ресурсов и игр значительно больше. Но существуют и русскоязычные игры, обучающие программированию. [Читать дальше →][2]
[1]: https://habrastorage.org/files/66b/422/2c6/66b4222c6013419c99a41da806ef6438.jpg
[2]: http://habrahabr.ru/post/273003/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-13 20:30:03
![][1] Образование стоит дорого. Хорошее образование стоит очень дорого. Но тем не менее возможность получить бесплатное и качественное образование есть у каждого. Компании и корпорации во всём мире вкладывают деньги в создание бесплатных образовательных продуктов. Отчасти, чтобы обеспечить себя квалифицированными кадрами в будущем. Отчасти, для преодоления бедности, предоставления всем равного доступ к качественному образованию. У каждого есть возможность воспользоваться специально созданной для обучения школьников средой программирования Scratch, которую разрабатывают специалисты одного из самых престижных технических учебных заведений США и мира — Массачусетского технологического института. Или игрой Minecraft, за которую Microsoft год назад заплатила $2,5 млрд и с помощью которой, в том числе, планирует обучать детей программированию. Или обучающими играми, которые создают энтузиасты и добровольцы во всём мире. Препятствием для использования подобных ресурсов может быть неосведомлённость о их существовании или незнание языка. Действительно, англоязычных ресурсов и игр значительно больше. Но существуют и русскоязычные игры, обучающие программированию. [Читать дальше →][2]
[1]: https://habrastorage.org/files/66b/422/2c6/66b4222c6013419c99a41da806ef6438.jpg
{kind=link}
[2]: http://habrahabr.ru/post/273003/#habracut
[>]
Знакомьтесь: Хеш-стеганография. Очень медленная, но совершенно секретная
habra.15
habrabot(difrex,1) — All
2015-12-13 21:00:02
Да, уважаемый читатель, вы правильно прочитали: **_совершенно секретная_**. Причем, прошу заметить, _совершенно секретная_ в самом строгом математическом смысле: [совершенно секретная по Кашену][1], ибо [расстояние Кульбака — Лейблера ][2] в моей математической конструкции будет равно нулю; причем не «почти нулю», а всамделишному нулю, без всяких «бесконечно малых» и иных вульгарных приближений! Каким образом? А очень просто — я вообще не буду ничего _вкраплять_ в стегоконтейнер. Действительно, если мы ничего не вкрапляем, то _пустой контейнер_ неотличим от _стегоконтейнера_, верно? «Подождите, но ведь если мы **** ничего не передаем!!!» — разумно поспорит со мной читатель. Абсолютно верно! Вкраплять мы и не будем! Есть способ, не искажая контейнер, тем не менее передать информацию. Как? Cхематично **Хеш-стеганографию [ɔ⃝][3]** можно представить так: ![][4] Текстовое пояснение к картинке под катом. [Поехали][5]
[1]: https://www.zurich.ibm.com/~cca/papers/stego.pdf
[2]: https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%9A%D1%83%D0%BB%D1%8C%D0%B1%D0%B0%D0%BA%D0%B0_%E2%80%94_%D0%9B%D0%B5%D0%B9%D0%B1%D0%BB%D0%B5%D1%80%D0%B0
[3]: https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D0%BB%D0%B5%D1%84%D1%82
[4]: https://habrastorage.org/files/912/1c9/806/9121c9806ada40619a316812d823d5db.gif
[5]: http://habrahabr.ru/post/272935/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-13 21:00:02
Да, уважаемый читатель, вы правильно прочитали: **_совершенно секретная_**. Причем, прошу заметить, _совершенно секретная_ в самом строгом математическом смысле: [совершенно секретная по Кашену][1], ибо [расстояние Кульбака — Лейблера ][2] в моей математической конструкции будет равно нулю; причем не «почти нулю», а всамделишному нулю, без всяких «бесконечно малых» и иных вульгарных приближений! Каким образом? А очень просто — я вообще не буду ничего _вкраплять_ в стегоконтейнер. Действительно, если мы ничего не вкрапляем, то _пустой контейнер_ неотличим от _стегоконтейнера_, верно? «Подождите, но ведь если мы **** ничего не передаем!!!» — разумно поспорит со мной читатель. Абсолютно верно! Вкраплять мы и не будем! Есть способ, не искажая контейнер, тем не менее передать информацию. Как? Cхематично **Хеш-стеганографию [ɔ⃝][3]** можно представить так: ![][4] Текстовое пояснение к картинке под катом. [Поехали][5]
[1]: https://www.zurich.ibm.com/~cca/papers/stego.pdf
[2]: https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%9A%D1%83%D0%BB%D1%8C%D0%B1%D0%B0%D0%BA%D0%B0_%E2%80%94_%D0%9B%D0%B5%D0%B9%D0%B1%D0%BB%D0%B5%D1%80%D0%B0
[3]: https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D0%BB%D0%B5%D1%84%D1%82
[4]: https://habrastorage.org/files/912/1c9/806/9121c9806ada40619a316812d823d5db.gif
{kind=link}
[5]: http://habrahabr.ru/post/272935/#habracut
[>]
Магические битборды и русские шашки
habra.15
habrabot(difrex,1) — All
2015-12-13 21:30:03
Данная статья — иллюстрация, каким образом битовые трюки могут быть использованы не только в задачах на собеседованиях, но и при решении реальных задач. В статье дано описание одного метода быстрой генерации ходов в русских шашках на основе магических битбордов (magic bitboard). [Битборды][1] — представление позиции в виде нескольких беззнаковых целых чисел, каждый бит которого отвечает за состояние некоторого элемента игры, например клетки. Обычно использование битбордов даёт выигрыш по производительности и по объёму используемой памяти, но связано с более изощрённым программированием. При этом часто возникает задача получения значения определённых бит в битборде, например, для последующего обращения к таблице. Есть два основных подхода к решению этой задачи. Первый — использование и поддержка избыточного представления в виде дополнительных битбордов с перенумерацией битов. Такие битборды асто называют вращаемые. Второй способ — умножение на магическую константу, сдвиг и обращение к таблице. О таких магических битбордах и пойдёт речь в этой статье. [Читать дальше →][2]
[1]: https://en.wikipedia.org/wiki/Bitboard"
[2]: http://habrahabr.ru/post/272815/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-13 21:30:03
Данная статья — иллюстрация, каким образом битовые трюки могут быть использованы не только в задачах на собеседованиях, но и при решении реальных задач. В статье дано описание одного метода быстрой генерации ходов в русских шашках на основе магических битбордов (magic bitboard). [Битборды][1] — представление позиции в виде нескольких беззнаковых целых чисел, каждый бит которого отвечает за состояние некоторого элемента игры, например клетки. Обычно использование битбордов даёт выигрыш по производительности и по объёму используемой памяти, но связано с более изощрённым программированием. При этом часто возникает задача получения значения определённых бит в битборде, например, для последующего обращения к таблице. Есть два основных подхода к решению этой задачи. Первый — использование и поддержка избыточного представления в виде дополнительных битбордов с перенумерацией битов. Такие битборды асто называют вращаемые. Второй способ — умножение на магическую константу, сдвиг и обращение к таблице. О таких магических битбордах и пойдёт речь в этой статье. [Читать дальше →][2]
[1]: https://en.wikipedia.org/wiki/Bitboard"
[2]: http://habrahabr.ru/post/272815/#habracut
[>]
Черный пиар Telegram. Кому верить?
habra.15
habrabot(difrex,1) — All
2015-12-13 22:30:01
![image][1] Недавно на Geektimes подняли шум со статьей [«Плохой Telegram» или Как я не взял денег за черный пиар Telegram на Хабрахабре][2]. В итоге выяснили, что знакомый Бурумыча читает переписку дочери и что приветствие «Добрый день» лучше чем «Доброго времени суток». Дабы вбросить в вентилятор полезной информации, мы со специалистами компании [Edison][3] сделали подборку публикаций про Telegam и безопасные мессенджеры, чтобы пытливый читатель мог самостоятельно сделать вывод (а не получить «проплаченную» экспертизу) чему стоит доверять и чем пользоваться для своих целей. Про уровень доверия/желтизны СМИ предлагаю решить читателю самостоятельно. Поток адекватной и неадекватной информации про безопасность коммуникации (и мессенджеров в том числе) растет и будет расти, и очень хочется, чтобы на Хабре можно было найти грамотную, независимую и понятную аналитику. Какими критериями пользоваться для оценки безопасности мессенджеров, можно подсмотреть у борцов за цифровую неприкосновенность — [Electronic Frontier Foundation][4] (EFF). Кстати, вопрос, являются ли эти критерии исчерпывающими или нужны дополнительные (например, про маскировку метаданных)? Чтобы повысить градус объективности и независимости, прошу высказаться в комментах тех, кто разбирается в вопросе по поводу безопасности мессенджеров. **На основе каких данных можно делать выводы?** [Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/364/d22/933/364d22933ae7ab5f35eaa0f2d91866b8.jpg
[2]: http://geektimes.ru/post/267072/
[3]: http://www.edsd.ru/
[4]: https://ru.wikipedia.org/wiki/Electronic_Frontier_Foundation
[5]: http://habrahabr.ru/post/273001/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-13 22:30:01
![image][1] Недавно на Geektimes подняли шум со статьей [«Плохой Telegram» или Как я не взял денег за черный пиар Telegram на Хабрахабре][2]. В итоге выяснили, что знакомый Бурумыча читает переписку дочери и что приветствие «Добрый день» лучше чем «Доброго времени суток». Дабы вбросить в вентилятор полезной информации, мы со специалистами компании [Edison][3] сделали подборку публикаций про Telegam и безопасные мессенджеры, чтобы пытливый читатель мог самостоятельно сделать вывод (а не получить «проплаченную» экспертизу) чему стоит доверять и чем пользоваться для своих целей. Про уровень доверия/желтизны СМИ предлагаю решить читателю самостоятельно. Поток адекватной и неадекватной информации про безопасность коммуникации (и мессенджеров в том числе) растет и будет расти, и очень хочется, чтобы на Хабре можно было найти грамотную, независимую и понятную аналитику. Какими критериями пользоваться для оценки безопасности мессенджеров, можно подсмотреть у борцов за цифровую неприкосновенность — [Electronic Frontier Foundation][4] (EFF). Кстати, вопрос, являются ли эти критерии исчерпывающими или нужны дополнительные (например, про маскировку метаданных)? Чтобы повысить градус объективности и независимости, прошу высказаться в комментах тех, кто разбирается в вопросе по поводу безопасности мессенджеров. **На основе каких данных можно делать выводы?** [Читать дальше →][5]
[1]: https://habrastorage.org/getpro/habr/post_images/364/d22/933/364d22933ae7ab5f35eaa0f2d91866b8.jpg
{kind=link}
[2]: http://geektimes.ru/post/267072/
[3]: http://www.edsd.ru/
[4]: https://ru.wikipedia.org/wiki/Electronic_Frontier_Foundation
[5]: http://habrahabr.ru/post/273001/#habracut
[>]
Полный перевод Unix-коанов на русский язык
habra.15
habrabot(difrex,1) — All
2015-12-14 02:00:04
![][1] Представляю на ваш суд ещё один перевод коанов о Мастере Фу на русский язык. В данный сборник вошли все коаны, на данный момент [опубликованные на сайте][2] Эрика Реймонда. Надо сказать, что сам Эрик личность весьма неординарная, но упоминания в данной статье стоящая. Помимо холиваров в списках рассылки всевозможных проектов за его авторством также несколько серьёзных трудов о Unix — в том числе и о сообществе, без которого экосистема современных открытых проектов не была бы возможной ([полный список книг][3]). Идея перевести коаны в очередной раз пришла мне в голову во время чтения одного из таких трудов, а именно «The Art of Unix Programming», поскольку многое из скрытого смысла коанов становится ясно только после прочтения очередной главы оттуда. Ну и конечно же, дисклеймер: все комментарии и специфика переложения есть плод воображения вашего покорного слуги. Я публикую этот перевод в надежде на то, что он может кому-то понравиться, но не предоставляю на него никаких гарантий, в том числе соответствия канонам перевода или пригодности для цитирования где бы то ни было. [Итак][4]
[1]: https://habrastorage.org/files/53d/22c/449/53d22c449b2c4210888477e2f913d19b.jpg
[2]: http://www.catb.org/esr/writings/unix-koans/
[3]: http://www.catb.org/esr/writings/
[4]: http://habrahabr.ru/post/273023/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-14 02:00:04
![][1] Представляю на ваш суд ещё один перевод коанов о Мастере Фу на русский язык. В данный сборник вошли все коаны, на данный момент [опубликованные на сайте][2] Эрика Реймонда. Надо сказать, что сам Эрик личность весьма неординарная, но упоминания в данной статье стоящая. Помимо холиваров в списках рассылки всевозможных проектов за его авторством также несколько серьёзных трудов о Unix — в том числе и о сообществе, без которого экосистема современных открытых проектов не была бы возможной ([полный список книг][3]). Идея перевести коаны в очередной раз пришла мне в голову во время чтения одного из таких трудов, а именно «The Art of Unix Programming», поскольку многое из скрытого смысла коанов становится ясно только после прочтения очередной главы оттуда. Ну и конечно же, дисклеймер: все комментарии и специфика переложения есть плод воображения вашего покорного слуги. Я публикую этот перевод в надежде на то, что он может кому-то понравиться, но не предоставляю на него никаких гарантий, в том числе соответствия канонам перевода или пригодности для цитирования где бы то ни было. [Итак][4]
[1]: https://habrastorage.org/files/53d/22c/449/53d22c449b2c4210888477e2f913d19b.jpg
{kind=link}
[2]: http://www.catb.org/esr/writings/unix-koans/
[3]: http://www.catb.org/esr/writings/
[4]: http://habrahabr.ru/post/273023/#habracut
[>]
Маленькие секреты большого колл-центра: предиктивный обзвон
habra.15
habrabot(difrex,1) — All
2015-12-14 11:00:03
![][1]Мы продолжаем рассказывать интересные зарисовки из жизни колл-центров, телекомов и облачной телефонии. Случалось ли вам отвечать на звонок и слышать “пожалуйста подождите, оператор сейчас свяжется с вами”? Первая мысль, которая приходит в голову обычно нецензурна, вторая — “они что, вконец обнаглели?!?”. Получивший такой звонок пользователь — жертва хитрой технологии “предиктивного обзвона”, которая позволяет колл-центрам экономить сотни часов времени, но иногда приводит к забавным результатам. Под катом я расскажу про эту штуку подробнее и покажу, как она может быть реализована в несколько строк кода на нашей облачной платформе voximplant [Под катом - sip, rtp и немного javascript][2]
[1]: https://habrastorage.org/files/a3a/5ab/975/a3a5ab9754e34931b32ec0b7c5cf260d.jpg
[2]: http://habrahabr.ru/post/272945/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-14 11:00:03
![][1]Мы продолжаем рассказывать интересные зарисовки из жизни колл-центров, телекомов и облачной телефонии. Случалось ли вам отвечать на звонок и слышать “пожалуйста подождите, оператор сейчас свяжется с вами”? Первая мысль, которая приходит в голову обычно нецензурна, вторая — “они что, вконец обнаглели?!?”. Получивший такой звонок пользователь — жертва хитрой технологии “предиктивного обзвона”, которая позволяет колл-центрам экономить сотни часов времени, но иногда приводит к забавным результатам. Под катом я расскажу про эту штуку подробнее и покажу, как она может быть реализована в несколько строк кода на нашей облачной платформе voximplant [Под катом - sip, rtp и немного javascript][2]
[1]: https://habrastorage.org/files/a3a/5ab/975/a3a5ab9754e34931b32ec0b7c5cf260d.jpg
{kind=link}
[2]: http://habrahabr.ru/post/272945/#habracut
[>]
[Из песочницы] Как сжать плоского кота
habra.15
habrabot(difrex,1) — All
2015-12-14 13:30:02
Однажды в студеную зимнюю пору… ровно год назад, у нас появилась нетривиальная задача. Есть экран на электронных чернилах, есть процессор 16МГц (да-да, во встраиваемой электронике, особенно сверхнизкого энергопотребления, встречаются и такие) и совсем нет памяти. Ну, т.е. килобайтов 8 RAM и 256 Flash. Килобайтов, Карл. И в эти унылые килобайты необходимо запихнуть несколько изображений 800х600 в четырех оттенках серого. Быстро перемножив в уме 800 на 600 и на 2 бита на пиксель получаем 120 тысяч байтов. Несколько не влезает. Надо сжимать. Так перед нами появилась задача: «как сжать плоского кота»? Почему кота? Да потому, что на котиках тестировали, на чем же еще черно-белые картинки проверять. Не на долларовых банкнотах же. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/273047/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-14 13:30:02
Однажды в студеную зимнюю пору… ровно год назад, у нас появилась нетривиальная задача. Есть экран на электронных чернилах, есть процессор 16МГц (да-да, во встраиваемой электронике, особенно сверхнизкого энергопотребления, встречаются и такие) и совсем нет памяти. Ну, т.е. килобайтов 8 RAM и 256 Flash. Килобайтов, Карл. И в эти унылые килобайты необходимо запихнуть несколько изображений 800х600 в четырех оттенках серого. Быстро перемножив в уме 800 на 600 и на 2 бита на пиксель получаем 120 тысяч байтов. Несколько не влезает. Надо сжимать. Так перед нами появилась задача: «как сжать плоского кота»? Почему кота? Да потому, что на котиках тестировали, на чем же еще черно-белые картинки проверять. Не на долларовых банкнотах же. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/273047/#habracut
[>]
[Из песочницы] Как я отлаживал python httplib и httplib2
habra.15
habrabot(difrex,1) — All
2015-12-14 16:00:02
Понадобилось мне однажды у себя в проекте реализовать работу с файловым хранилищем с использованием HTTP REST API. Проект разрабатывается на python, к тому же уже был реализован http-клиент с использованием библиотеки httplib2, поэтому было решено расширить функциональность http-клиента и работать с файловым хранилищем через туже библиотеку. Проблема возникла при загрузке файлов на сервер. Первый PUT запрос выполняется, далее все последующие запросы отказываются выполняться — 500 _Internal Server Error_. Смотрю Wireshark'ом выясняется что после первого запроса сервер посылает в заголовках ответа **connection: keep-alive** и следом через 5 секунд закрывает соединение. Всё просто — это таймаут keep-alive установлен на сервере. ![][1] А вот как это выглядит на клиенте: [Читать дальше →][2]
[1]: https://habrastorage.org/files/5e9/6fa/dfa/5e96fadfa3ce4f8891e6e19601233b26.png
[2]: http://habrahabr.ru/post/273051/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-14 16:00:02
Понадобилось мне однажды у себя в проекте реализовать работу с файловым хранилищем с использованием HTTP REST API. Проект разрабатывается на python, к тому же уже был реализован http-клиент с использованием библиотеки httplib2, поэтому было решено расширить функциональность http-клиента и работать с файловым хранилищем через туже библиотеку. Проблема возникла при загрузке файлов на сервер. Первый PUT запрос выполняется, далее все последующие запросы отказываются выполняться — 500 _Internal Server Error_. Смотрю Wireshark'ом выясняется что после первого запроса сервер посылает в заголовках ответа **connection: keep-alive** и следом через 5 секунд закрывает соединение. Всё просто — это таймаут keep-alive установлен на сервере. ![][1] А вот как это выглядит на клиенте: [Читать дальше →][2]
[1]: https://habrastorage.org/files/5e9/6fa/dfa/5e96fadfa3ce4f8891e6e19601233b26.png
{kind=link}
[2]: http://habrahabr.ru/post/273051/#habracut
[>]
Multihome IPv4 в Linux
habra.15
habrabot(difrex,1) — All
2015-12-14 16:00:02
Содержимое: как сделать так, чтобы компьютер отвечал в интернете на все свои IP-адреса по всем своим интерфейсам, каждый из которых шлюз по умолчанию. Касается и серверов, и десктопов. Ключевые слова: policy routing, source based routing Лирика: Есть достаточно статей про policy routing в Linux. Но они чаще всего разбирают общие, более тонкие и сложные случаи. Я же разберу тривиальный сценарий следующего вида: ![][1] Нашему компьютеру (серверу) доступно три интерфейса. На каждом интерфейсе шлюз ему выдал IP (статикой или по dhcp, не важно) и сказал «весь трафик шли мне». Если мы оставим эту конфигурацию как есть, то будет использоваться принцип «кто последний встал, того и дефолтный шлюз». На картинке выше, если последним поднимется нижний интерфейс (241), то в него будет отправляться весь трафик. Если к нашему серверу придёт запрос на первый интерфейс (188), то ответ на него всё равно пойдёт по нижнему. Если у маршрутизатора/провайдера есть хотя бы минимальная защита от подделки адресов, то ответ просто дропнут, как невалидный (с точки зрения 241.241.241.1 ему прислали из сети 241.241.241.0/24 пакет с src 188.188.188.188, чего, очевидно, быть не должно). Другими словами, в обычном варианте будет работать только один интерфейс. Чтобы сделать ситуацию хуже, если адреса получены по dhcp, то обновление аренды на других интефрейсах может перезаписать шлюз по умолчанию, что означает, что тот интерфейс, который работал, работать перестанет, а начнёт работать другой интерфейс. Удачной стабильной работы вашему серверу, так сказать.
# Решение
[Читать дальше →][2]
[1]: https://habrastorage.org/files/5e6/b09/738/5e6b0973886b4ab689b8acea335ca0da.png
[2]: http://habrahabr.ru/post/107267/#habracut
habra.15
habrabot(difrex,1) — All
2015-12-14 16:00:02
Содержимое: как сделать так, чтобы компьютер отвечал в интернете на все свои IP-адреса по всем своим интерфейсам, каждый из которых шлюз по умолчанию. Касается и серверов, и десктопов. Ключевые слова: policy routing, source based routing Лирика: Есть достаточно статей про policy routing в Linux. Но они чаще всего разбирают общие, более тонкие и сложные случаи. Я же разберу тривиальный сценарий следующего вида: ![][1] Нашему компьютеру (серверу) доступно три интерфейса. На каждом интерфейсе шлюз ему выдал IP (статикой или по dhcp, не важно) и сказал «весь трафик шли мне». Если мы оставим эту конфигурацию как есть, то будет использоваться принцип «кто последний встал, того и дефолтный шлюз». На картинке выше, если последним поднимется нижний интерфейс (241), то в него будет отправляться весь трафик. Если к нашему серверу придёт запрос на первый интерфейс (188), то ответ на него всё равно пойдёт по нижнему. Если у маршрутизатора/провайдера есть хотя бы минимальная защита от подделки адресов, то ответ просто дропнут, как невалидный (с точки зрения 241.241.241.1 ему прислали из сети 241.241.241.0/24 пакет с src 188.188.188.188, чего, очевидно, быть не должно). Другими словами, в обычном варианте будет работать только один интерфейс. Чтобы сделать ситуацию хуже, если адреса получены по dhcp, то обновление аренды на других интефрейсах может перезаписать шлюз по умолчанию, что означает, что тот интерфейс, который работал, работать перестанет, а начнёт работать другой интерфейс. Удачной стабильной работы вашему серверу, так сказать.
# Решение
[Читать дальше →][2]
[1]: https://habrastorage.org/files/5e6/b09/738/5e6b0973886b4ab689b8acea335ca0da.png
{kind=link}
[2]: http://habrahabr.ru/post/107267/#habracut