|
|
Login |
[>]
[recovery mode] Kaspersky Industrial CTF: время защищать подстанции, и время ломать подстанции
habra.15
habrabot(difrex,1) — All
2015-10-05 18:30:03
Хватит чистого теоретизирования о несовершенстве существующих систем защиты критической инфраструктуры — пора переходить к практической части. Мы предлагаем взять в руки шашки и попробовать взломать цифровую подстанцию. Да нет, не эту. Макет. Если быть абсолютно точным, то мы предлагаем принять участие в CTF-соревнованиях, в финале которых представится возможность попробовать на прочность действующую модель цифровой подстанции. Но обо всем по порядку.
[Читать дальше →][1]
[1]: http://habrahabr.ru/post/268243/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-05 18:30:03
Хватит чистого теоретизирования о несовершенстве существующих систем защиты критической инфраструктуры — пора переходить к практической части. Мы предлагаем взять в руки шашки и попробовать взломать цифровую подстанцию. Да нет, не эту. Макет. Если быть абсолютно точным, то мы предлагаем принять участие в CTF-соревнованиях, в финале которых представится возможность попробовать на прочность действующую модель цифровой подстанции. Но обо всем по порядку.
[Читать дальше →][1]
[1]: http://habrahabr.ru/post/268243/#habracut
[>]
Поиск и чтение унаследованного кода
habra.15
habrabot(difrex,1) — All
2015-10-05 19:30:04
Вася — молодой программист. Получив задачу и засучив рукава, он берется за написание кода. Уже через день решение задачи готово, Вася запускает его… И сталкивается с неожиданной досадной ошибкой. Вася старательно исправляет ее и повторно запускает решение. В результате — снова неприятная ошибка. Так Вася долго наступает на грабли, пару раз значительно переписывает программу, пока, наконец, через неделю задача окончательно не решена. Петя — опытный программист. Получив постановку, он ищет, нет ли исходного кода, решавшего аналогичную задачу. Пару дней Петя проводит, читая материалы и разбираясь в чужих модулях, а на третий — запускает свое решение, основанное на уже существующем коде. В нем есть пара незначительных ошибок, которые удается быстро исправить. Ура! Все работает так, как нужно, уже на третий день. Как найти нужный вам кусок исходного кода? Как его понять? А главное — зачем все это делать? В поиске ответов на эти вопросы добро пожаловать под кат. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/267923/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-05 19:30:04
Вася — молодой программист. Получив задачу и засучив рукава, он берется за написание кода. Уже через день решение задачи готово, Вася запускает его… И сталкивается с неожиданной досадной ошибкой. Вася старательно исправляет ее и повторно запускает решение. В результате — снова неприятная ошибка. Так Вася долго наступает на грабли, пару раз значительно переписывает программу, пока, наконец, через неделю задача окончательно не решена. Петя — опытный программист. Получив постановку, он ищет, нет ли исходного кода, решавшего аналогичную задачу. Пару дней Петя проводит, читая материалы и разбираясь в чужих модулях, а на третий — запускает свое решение, основанное на уже существующем коде. В нем есть пара незначительных ошибок, которые удается быстро исправить. Ура! Все работает так, как нужно, уже на третий день. Как найти нужный вам кусок исходного кода? Как его понять? А главное — зачем все это делать? В поиске ответов на эти вопросы добро пожаловать под кат. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/267923/#habracut
[>]
ECFG: сажаем ~/.emacs на диету
habra.15
habrabot(difrex,1) — All
2015-10-05 20:30:03
Друзья, сегодня я хочу поделиться с вами реализацией идеи по созданию модульной, переносимой и масштабируемой конфигурации для вашего любимого текстового редактора, опробованную в деле за многие месяцы на самых различных сочетаниях железа и ПО: [Emacs Config][1]. ![image][2] [Читать дальше →][3]
[1]: https://github.com/maslennikov/emacs-config
[2]: https://habrastorage.org/getpro/habr/post_images/89a/0b6/40a/89a0b640a77fc6a35e6770ff6062da2f.png
[3]: http://habrahabr.ru/post/268271/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-05 20:30:03
Друзья, сегодня я хочу поделиться с вами реализацией идеи по созданию модульной, переносимой и масштабируемой конфигурации для вашего любимого текстового редактора, опробованную в деле за многие месяцы на самых различных сочетаниях железа и ПО: [Emacs Config][1]. ![image][2] [Читать дальше →][3]
[1]: https://github.com/maslennikov/emacs-config
[2]: https://habrastorage.org/getpro/habr/post_images/89a/0b6/40a/89a0b640a77fc6a35e6770ff6062da2f.png
{kind=link}
[3]: http://habrahabr.ru/post/268271/#habracut
[>]
[Из песочницы] Уязвимость в Platius: доступ в любой аккаунт
habra.15
habrabot(difrex,1) — All
2015-10-06 13:30:05
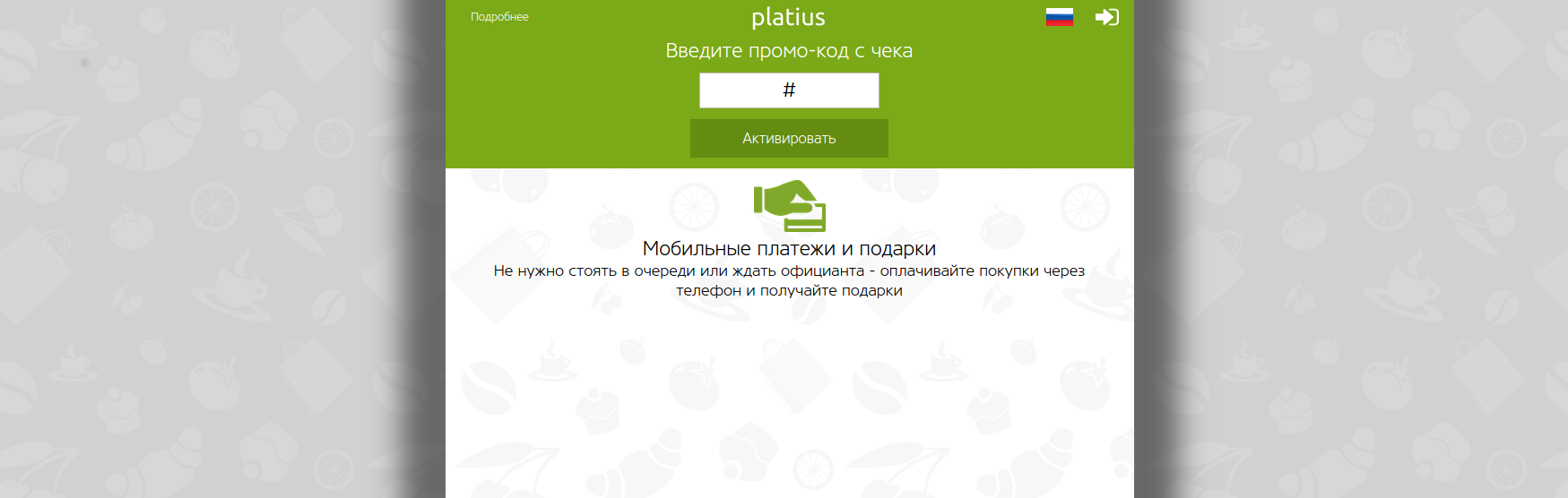
На прошлой неделе пришло письмо с приглашением пройти интервью в компанию [Платиус][1]. Позиция была написана как будто под меня, и после созвона была назначена встреча для интервью. У меня оставался вечер на подготовку и я решил изучить, чем же все таки компания занимается. Оказалось, что «предоставлением» свободного доступа к аккаунтам своих пользователей. ![][2] [Читать дальше →][3]
[1]: https://platius.ru/
[2]: https://habrastorage.org/files/aba/42f/9a5/aba42f9a5c9c4ca394fca300311554ec.png
[3]: http://habrahabr.ru/post/268305/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 13:30:05
На прошлой неделе пришло письмо с приглашением пройти интервью в компанию [Платиус][1]. Позиция была написана как будто под меня, и после созвона была назначена встреча для интервью. У меня оставался вечер на подготовку и я решил изучить, чем же все таки компания занимается. Оказалось, что «предоставлением» свободного доступа к аккаунтам своих пользователей. ![][2] [Читать дальше →][3]
[1]: https://platius.ru/
[2]: https://habrastorage.org/files/aba/42f/9a5/aba42f9a5c9c4ca394fca300311554ec.png
{kind=link}
[3]: http://habrahabr.ru/post/268305/#habracut
[>]
[Перевод] К чему можно оказаться не готовым, став тим-лидом
habra.15
habrabot(difrex,1) — All
2015-10-06 14:00:06
_Один технический специалист нашей компании [PayOnline][1], которая занимается автоматизацией приема платежей, предложил перевести статью автора Pascal de Vink, который проработал тим-лидом уже 2 года. Когда Pascal только занял эту должность, оказалось, что ко многим вещам он был просто не готов. Эта статья поможет избежать многих ошибок на пути от разработчика к лидеру команды. Ниже идет непосредственно перевод._ До этого я был инженером и занимался непосредственно кодом. Мне говорили, что у меня хорошие лидерские качества, наверно, поэтому я и попросил о повышении. Я даже не задумывался, что значит управлять целой командой инженеров. Сейчас думаю, вот бы тогда у меня было побольше времени на подготовку. Итак, без лишних слов, вот вещи, к которым я оказался не готов.
#### Меньше заниматься разработкой
Может, это и очевидно, но роль ведущего разработчика означает, что надо больше смотреть на общую картину, чем углубляться в конкретные аспекты того, что происходит. Я этого не понимал, пока не проработал пару месяцев, в течение которых мучился от того, что хотел разобраться во всех задачах, а времени на это не было. У меня было все меньше времени копаться в коде, а люди продолжали обращаться ко мне со своими очень узкоспециализированными задачами. Слишком поздно я понял, что надо разбираться в команде, а не во всех ее знаниях. Узнать, кто разбирается в нужной области оказалось намного быстрее и ценнее. Хотя, копаться в коде было намного веселее. [Читать дальше →][2]
[1]: http://payonline.ru/?utm_source=habrahabr&utm_medium=referral&utm_campaign=webpayments-main
[2]: http://habrahabr.ru/post/268325/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 14:00:06
_Один технический специалист нашей компании [PayOnline][1], которая занимается автоматизацией приема платежей, предложил перевести статью автора Pascal de Vink, который проработал тим-лидом уже 2 года. Когда Pascal только занял эту должность, оказалось, что ко многим вещам он был просто не готов. Эта статья поможет избежать многих ошибок на пути от разработчика к лидеру команды. Ниже идет непосредственно перевод._ До этого я был инженером и занимался непосредственно кодом. Мне говорили, что у меня хорошие лидерские качества, наверно, поэтому я и попросил о повышении. Я даже не задумывался, что значит управлять целой командой инженеров. Сейчас думаю, вот бы тогда у меня было побольше времени на подготовку. Итак, без лишних слов, вот вещи, к которым я оказался не готов.
#### Меньше заниматься разработкой
Может, это и очевидно, но роль ведущего разработчика означает, что надо больше смотреть на общую картину, чем углубляться в конкретные аспекты того, что происходит. Я этого не понимал, пока не проработал пару месяцев, в течение которых мучился от того, что хотел разобраться во всех задачах, а времени на это не было. У меня было все меньше времени копаться в коде, а люди продолжали обращаться ко мне со своими очень узкоспециализированными задачами. Слишком поздно я понял, что надо разбираться в команде, а не во всех ее знаниях. Узнать, кто разбирается в нужной области оказалось намного быстрее и ценнее. Хотя, копаться в коде было намного веселее. [Читать дальше →][2]
[1]: http://payonline.ru/?utm_source=habrahabr&utm_medium=referral&utm_campaign=webpayments-main
[2]: http://habrahabr.ru/post/268325/#habracut
[>]
[Из песочницы] Экспорт Terrain'а из WorldMachin в Unity3D
habra.15
habrabot(difrex,1) — All
2015-10-06 14:00:06
_Эта статья является адаптированным под современны редактор переводом на русский язык оригинальной инструкции: [«Terrain export from world machine to unity»][1]._
----
World Machine может служить отличным генератором местности для Unity. Unity же имеет нативную поддержку текстур и splatmaps. Вы можете создать и использовать несколько слоёв текстур местности одновременно. Здесь представлен простой рабочий код для импорта в Unity местности из World Machine. Пожалуйста, обратите внимание, что, хотя этот метод работает для основных местностей в unity, многие продвинутые пользователи могут создать собственные шейдеры местности, которые могут потребовать другую технику исполнения. [Читать дальше →][2]
[1]: http://www.world-machine.com/learn.php?page=workflow&workflow=wfunity
[2]: http://habrahabr.ru/post/268297/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 14:00:06
_Эта статья является адаптированным под современны редактор переводом на русский язык оригинальной инструкции: [«Terrain export from world machine to unity»][1]._
----
World Machine может служить отличным генератором местности для Unity. Unity же имеет нативную поддержку текстур и splatmaps. Вы можете создать и использовать несколько слоёв текстур местности одновременно. Здесь представлен простой рабочий код для импорта в Unity местности из World Machine. Пожалуйста, обратите внимание, что, хотя этот метод работает для основных местностей в unity, многие продвинутые пользователи могут создать собственные шейдеры местности, которые могут потребовать другую технику исполнения. [Читать дальше →][2]
[1]: http://www.world-machine.com/learn.php?page=workflow&workflow=wfunity
[2]: http://habrahabr.ru/post/268297/#habracut
[>]
Пол Грэм: «Проектирование и исследование»
habra.15
habrabot(difrex,1) — All
2015-10-06 14:30:04
![][1] Пол Грэм, [Design and Research][2], January 2003 [«Хакеры и Художники»][3], глава 15 **Проектирование и Исследование** _За перевод спасибо [knagaev][4]_ (Эта статья в своей основе содержит программный доклад на NEPLS осенью 2002 года) Приезжающих в Америку часто застаёт врасплох манера американцев начинать разговор с вопроса «Чем вы занимаетесь?» Я никогда не любил этот вопрос. Я очень редко слышал достойный ответ на него. Но сейчас думаю, что решил эту проблему. Теперь, если кто-нибудь спрашивает чем я занимаюсь, я смотрю ему прямо в глаза и говорю «Я проектирую [новый диалект Lisp][5].» Этот ответ я рекомендую всем, кто не любит когда интересуются что они делают. Разговор тут же свернёт на другие темы. Я не считаю, что занимаюсь исследованиями языков программирования. Я всего лишь проектирую один из них, как кто-нибудь может проектировать здание, или стул, или новый шрифт. Я не пытаюсь открыть что-то новое. Я только хочу создать язык, который будет хорош для программирования на нём. В какой-то мере, это делает жизнь намного проще. Различия между проектированием и исследованием похожи на противопоставление нового и хорошего. Архитектурное решение не должно быть новым, но должно быть качественным. Результаты исследования не обязательно должны быть правильными, но обязаны обладать новизной. Думаю, что эти два пути сходятся на вершине: лучший дизайн превосходит своих предшественников на основе использования новых идей, а лучшее исследование решает задачи, которые не столько новые, сколько на самом деле заслуживающие решения. Так что, в конечном счёте, мы стремимся к одному, просто двигаемся с разных сторон. ![image][6] [Читать дальше →][7]
[1]: https://habrastorage.org/files/6b7/825/d34/6b7825d347b9461a9d385aa8e33c1151.jpg
[2]: http://www.paulgraham.com/desres.html
[3]: http://habrahabr.ru/company/tceh/blog/253311/
[4]: http://habrahabr.ru/users/knagaev/
[5]: http://www.paulgraham.com/arc.html
[6]: https://habrastorage.org/getpro/habr/post_images/411/d72/a1d/411d72a1d2f854c14f6c3d0fc1d23806.png
[7]: http://habrahabr.ru/post/268281/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 14:30:04
![][1] Пол Грэм, [Design and Research][2], January 2003 [«Хакеры и Художники»][3], глава 15 **Проектирование и Исследование** _За перевод спасибо [knagaev][4]_ (Эта статья в своей основе содержит программный доклад на NEPLS осенью 2002 года) Приезжающих в Америку часто застаёт врасплох манера американцев начинать разговор с вопроса «Чем вы занимаетесь?» Я никогда не любил этот вопрос. Я очень редко слышал достойный ответ на него. Но сейчас думаю, что решил эту проблему. Теперь, если кто-нибудь спрашивает чем я занимаюсь, я смотрю ему прямо в глаза и говорю «Я проектирую [новый диалект Lisp][5].» Этот ответ я рекомендую всем, кто не любит когда интересуются что они делают. Разговор тут же свернёт на другие темы. Я не считаю, что занимаюсь исследованиями языков программирования. Я всего лишь проектирую один из них, как кто-нибудь может проектировать здание, или стул, или новый шрифт. Я не пытаюсь открыть что-то новое. Я только хочу создать язык, который будет хорош для программирования на нём. В какой-то мере, это делает жизнь намного проще. Различия между проектированием и исследованием похожи на противопоставление нового и хорошего. Архитектурное решение не должно быть новым, но должно быть качественным. Результаты исследования не обязательно должны быть правильными, но обязаны обладать новизной. Думаю, что эти два пути сходятся на вершине: лучший дизайн превосходит своих предшественников на основе использования новых идей, а лучшее исследование решает задачи, которые не столько новые, сколько на самом деле заслуживающие решения. Так что, в конечном счёте, мы стремимся к одному, просто двигаемся с разных сторон. ![image][6] [Читать дальше →][7]
[1]: https://habrastorage.org/files/6b7/825/d34/6b7825d347b9461a9d385aa8e33c1151.jpg
{kind=link}
[2]: http://www.paulgraham.com/desres.html
[3]: http://habrahabr.ru/company/tceh/blog/253311/
[4]: http://habrahabr.ru/users/knagaev/
[5]: http://www.paulgraham.com/arc.html
[6]: https://habrastorage.org/getpro/habr/post_images/411/d72/a1d/411d72a1d2f854c14f6c3d0fc1d23806.png
{kind=link}
[7]: http://habrahabr.ru/post/268281/#habracut
[>]
Новая атака на почтовый сервер Outlook Web Application позволяет украсть пароли
habra.15
habrabot(difrex,1) — All
2015-10-06 16:00:05
### Атака на корпоративный сервер Outlook Web Application (OWA) дает злоумышленникам доступ к паролям и учетным записям почты всей организации
![image][1] Команда специалистов по информационной безопасности из организации Cybereason обнаружила вредоносный модуль в файлах сервера OWA компании, имеющей на нем более 19 000 учетных записей. Имя компании не называется. Клиент Cybereason заметил подозрительную активность в своей внутренней сети и обратился за помощью к специалистам по безопасности. В ходе проведенного аудита на факт заражения внутренней сети, было обнаружена подмена одного из DLL-файлов на OWA-сервере организации-заказчика. В отличие от оригинального DLL-файла **OWAAUTH.dll**, DLL с бэкдором не содержал цифровой подписи и находился в другом каталоге. [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/339/894/8a2/3398948a2f42c807e8c810ed4266b373.png
[2]: http://habrahabr.ru/post/267167/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 16:00:05
### Атака на корпоративный сервер Outlook Web Application (OWA) дает злоумышленникам доступ к паролям и учетным записям почты всей организации
![image][1] Команда специалистов по информационной безопасности из организации Cybereason обнаружила вредоносный модуль в файлах сервера OWA компании, имеющей на нем более 19 000 учетных записей. Имя компании не называется. Клиент Cybereason заметил подозрительную активность в своей внутренней сети и обратился за помощью к специалистам по безопасности. В ходе проведенного аудита на факт заражения внутренней сети, было обнаружена подмена одного из DLL-файлов на OWA-сервере организации-заказчика. В отличие от оригинального DLL-файла **OWAAUTH.dll**, DLL с бэкдором не содержал цифровой подписи и находился в другом каталоге. [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/339/894/8a2/3398948a2f42c807e8c810ed4266b373.png
{kind=link}
[2]: http://habrahabr.ru/post/267167/#habracut
[>]
Приглашаем на OWASP EEE 11 октября
habra.15
habrabot(difrex,1) — All
2015-10-06 16:00:05
![][1] C 6 по 12 октября пройдёт целая серия из 7 мини-конференций для специалистов по информационной безопасности под общим названием [OWASP EEE][2]. Встречи пройдут в 6 разных странах: в Польше, Литве, Румынии (в городах Клуж (Cluj) и Бухарест), в Венгрии, России и Австрии. На каждой встрече будут разные доклады, но благодаря ежедневной онлайн-трансляции вы сможете посмотреть все интересующие выступления. Российская часть OWASP EEE состоится 11 октября в офисе Mail.Ru Group. Обращаем внимание, что все доклады будут на английском языке. [Читать дальше →][3]
[1]: https://habrastorage.org/files/fd4/26d/65a/fd426d65ac494ad6b8b107c2fac469a1.jpg
[2]: http://owaspeee.appsec.xyz/
[3]: http://habrahabr.ru/post/268337/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 16:00:05
![][1] C 6 по 12 октября пройдёт целая серия из 7 мини-конференций для специалистов по информационной безопасности под общим названием [OWASP EEE][2]. Встречи пройдут в 6 разных странах: в Польше, Литве, Румынии (в городах Клуж (Cluj) и Бухарест), в Венгрии, России и Австрии. На каждой встрече будут разные доклады, но благодаря ежедневной онлайн-трансляции вы сможете посмотреть все интересующие выступления. Российская часть OWASP EEE состоится 11 октября в офисе Mail.Ru Group. Обращаем внимание, что все доклады будут на английском языке. [Читать дальше →][3]
[1]: https://habrastorage.org/files/fd4/26d/65a/fd426d65ac494ad6b8b107c2fac469a1.jpg
{kind=link}
[2]: http://owaspeee.appsec.xyz/
[3]: http://habrahabr.ru/post/268337/#habracut
[>]
Профилировка работы с памятью с Intel® VTune™ Amplifier XE
habra.15
habrabot(difrex,1) — All
2015-10-06 16:00:05
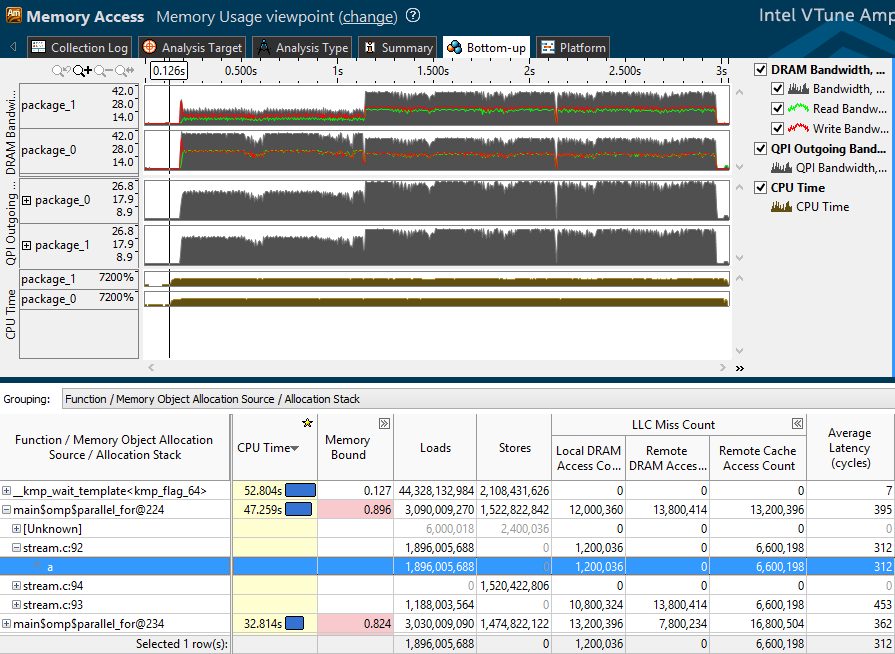
Неэффективный доступ к памяти, пожалуй, одна из наиболее частых проблем производительности программ. Скорость загрузки данных из памяти традиционно отстаёт от скорости их обработки процессором. Для уменьшения времени доступа к данным в современных процессорах реализуются специальные блоки и многоуровневые системы кэшей, позволяющие сократить время простоя процессора при загрузке данных, однако, в некоторых случаях, процессорная логика работает не эффективно. В этом посте поговорим о том, как можно исследовать работу с памятью вашего приложения с помощью нового профиля Memory Access в VTune Amplifier XE. ![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/06f/cbd/30e/06fcbd30e74445ba8da23c0fae109a25.png
[2]: http://habrahabr.ru/post/266687/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 16:00:05
Неэффективный доступ к памяти, пожалуй, одна из наиболее частых проблем производительности программ. Скорость загрузки данных из памяти традиционно отстаёт от скорости их обработки процессором. Для уменьшения времени доступа к данным в современных процессорах реализуются специальные блоки и многоуровневые системы кэшей, позволяющие сократить время простоя процессора при загрузке данных, однако, в некоторых случаях, процессорная логика работает не эффективно. В этом посте поговорим о том, как можно исследовать работу с памятью вашего приложения с помощью нового профиля Memory Access в VTune Amplifier XE. ![][1] [Читать дальше →][2]
[1]: https://habrastorage.org/files/06f/cbd/30e/06fcbd30e74445ba8da23c0fae109a25.png
{kind=link}
[2]: http://habrahabr.ru/post/266687/#habracut
[>]
Как писать тестируемый код
habra.15
habrabot(difrex,1) — All
2015-10-06 16:30:05
Если вы программист (или чего хуже архитектор), то можете ли вы ответить на такой простой вопрос: как писать НЕ тестируемый код? Призадумались? Если с трудом можете назвать хотя бы 3 способа добиться не тестируемого кода, то статья для вас. Многие скажут: а зачем мне знать, как писать не тестируемый код, плохому хочешь меня научить? Отвечаю: если знать типичные паттерны не тестируемого кода, то, если они есть, можно легко увидеть их в своем проекте. А, как известно, признание проблемы — уже половина пути к лечению. Также в статье дается ответ, как собственно осуществляется такое лечение. Прошу под кат. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/267277/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 16:30:05
Если вы программист (или чего хуже архитектор), то можете ли вы ответить на такой простой вопрос: как писать НЕ тестируемый код? Призадумались? Если с трудом можете назвать хотя бы 3 способа добиться не тестируемого кода, то статья для вас. Многие скажут: а зачем мне знать, как писать не тестируемый код, плохому хочешь меня научить? Отвечаю: если знать типичные паттерны не тестируемого кода, то, если они есть, можно легко увидеть их в своем проекте. А, как известно, признание проблемы — уже половина пути к лечению. Также в статье дается ответ, как собственно осуществляется такое лечение. Прошу под кат. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/267277/#habracut
[>]
Новая атака на почтовый сервер Microsoft Exchange позволяет украсть пароли
habra.15
habrabot(difrex,1) — All
2015-10-06 16:30:05
### Атака на Outlook Web Application (OWA) дает злоумышленникам доступ к паролям и учетным записям почты всей организации
![image][1] Команда специалистов по информационной безопасности из организации Cybereason обнаружила вредоносный модуль в файлах сервера OWA компании, имеющей на нем более 19 000 учетных записей. Имя компании не называется. Клиент Cybereason заметил подозрительную активность в своей внутренней сети и обратился за помощью к специалистам по безопасности. В ходе проведенного аудита на факт заражения внутренней сети, было обнаружена подмена одного из DLL-файлов на OWA-сервере организации-заказчика. В отличие от оригинального DLL-файла **OWAAUTH.dll**, DLL с бэкдором не содержал цифровой подписи и находился в другом каталоге. [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/339/894/8a2/3398948a2f42c807e8c810ed4266b373.png
[2]: http://habrahabr.ru/post/267167/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 16:30:05
### Атака на Outlook Web Application (OWA) дает злоумышленникам доступ к паролям и учетным записям почты всей организации
![image][1] Команда специалистов по информационной безопасности из организации Cybereason обнаружила вредоносный модуль в файлах сервера OWA компании, имеющей на нем более 19 000 учетных записей. Имя компании не называется. Клиент Cybereason заметил подозрительную активность в своей внутренней сети и обратился за помощью к специалистам по безопасности. В ходе проведенного аудита на факт заражения внутренней сети, было обнаружена подмена одного из DLL-файлов на OWA-сервере организации-заказчика. В отличие от оригинального DLL-файла **OWAAUTH.dll**, DLL с бэкдором не содержал цифровой подписи и находился в другом каталоге. [Читать дальше →][2]
[1]: https://habrastorage.org/getpro/habr/post_images/339/894/8a2/3398948a2f42c807e8c810ed4266b373.png
[2]: http://habrahabr.ru/post/267167/#habracut
[>]
HackerSIM: подделка любого телефонного номера. CTF по социальной инженерии
habra.15
habrabot(difrex,1) — All
2015-10-06 18:00:07
> _«Народ не должен бояться своего правительства, правительство должно бояться своего народа»_
> _«Privacy is ultimately more important than our fear of bad things happening, like terrorism.»_
![][1] _Уверены ли вы, что вам звонит тот, за кого себя выдает? Даже если высвечивается знакомый номер._ Недавно я обзавелся "[хакерской симкой всевластия][2]". Которая помимо лютой анонимности имеет фичу — подделка номера. Расскажу как это происходит. Чак на своем телефоне, куда вставлена HackerSIM, набирает команду \*150\*НомерАлисы# и через секунду получает подтверждение, что номер успешно «подделан». Затем Чак звонит со своего телефона Бобу. Телефон Боба принимает вызов, и на нем высвечивается, что ему звонит… Алиса. Profit. Далее события разворачиваются в зависимости от социнженерного (или чревовещательного) таланта Чака. Я начал разыгрывать своих хороших знакомых. [Читать дальше →][3]
[1]: https://habrastorage.org/files/57c/d27/cf0/57cd27cf00f34147b614a12222128ef2.jpg
[2]: http://geektimes.ru/post/263506/
[3]: http://habrahabr.ru/post/266709/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 18:00:07
> _«Народ не должен бояться своего правительства, правительство должно бояться своего народа»_
> _«Privacy is ultimately more important than our fear of bad things happening, like terrorism.»_
![][1] _Уверены ли вы, что вам звонит тот, за кого себя выдает? Даже если высвечивается знакомый номер._ Недавно я обзавелся "[хакерской симкой всевластия][2]". Которая помимо лютой анонимности имеет фичу — подделка номера. Расскажу как это происходит. Чак на своем телефоне, куда вставлена HackerSIM, набирает команду \*150\*НомерАлисы# и через секунду получает подтверждение, что номер успешно «подделан». Затем Чак звонит со своего телефона Бобу. Телефон Боба принимает вызов, и на нем высвечивается, что ему звонит… Алиса. Profit. Далее события разворачиваются в зависимости от социнженерного (или чревовещательного) таланта Чака. Я начал разыгрывать своих хороших знакомых. [Читать дальше →][3]
[1]: https://habrastorage.org/files/57c/d27/cf0/57cd27cf00f34147b614a12222128ef2.jpg
{kind=link}
[2]: http://geektimes.ru/post/263506/
[3]: http://habrahabr.ru/post/266709/#habracut
[>]
Тестирование в Яндексе. Как сделать отказоустойчивый грид из тысячи браузеров
habra.15
habrabot(difrex,1) — All
2015-10-06 19:00:03
Любой специалист, причастный к тестированию веб-приложений, знает, что большинство рутинных действий на сервисах умеет делать фреймворк [Selenium][1]. В Яндексе в день выполняются миллионы автотестов, использующих Selenium для работы с браузерами, поэтому нам нужны тысячи различных браузеров, доступных одновременно и 24/7. И вот тут начинается самое интересное. [![][2]][3] Selenium с большим количеством браузеров имеет много проблем с масштабированием и отказоустойчивостью. После нескольких попыток у нас получилось элегантное и простое в обслуживании решение, и мы хотим поделиться им с вами. Наш проект **gridrouter** позволяет организовать отказоустойчивый Selenium-грид из любого количества браузеров. Код выложен в open-source и доступен на [Github][4]. Под катом я расскажу, на какие недостатки Selenium мы обращали внимание, как пришли к нашему решению, и объясню, как его настроить. [Читать дальше →][5]
[1]: http://docs.seleniumhq.org/
[2]: https://habrastorage.org/files/173/930/c0e/173930c0ec244ae8afa229966e0453d3.png
[3]: http://habrahabr.ru/company/yandex/blog/268309/
[4]: https://github.com/seleniumkit/gridrouter
[5]: http://habrahabr.ru/post/268309/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 19:00:03
Любой специалист, причастный к тестированию веб-приложений, знает, что большинство рутинных действий на сервисах умеет делать фреймворк [Selenium][1]. В Яндексе в день выполняются миллионы автотестов, использующих Selenium для работы с браузерами, поэтому нам нужны тысячи различных браузеров, доступных одновременно и 24/7. И вот тут начинается самое интересное. [![][2]][3] Selenium с большим количеством браузеров имеет много проблем с масштабированием и отказоустойчивостью. После нескольких попыток у нас получилось элегантное и простое в обслуживании решение, и мы хотим поделиться им с вами. Наш проект **gridrouter** позволяет организовать отказоустойчивый Selenium-грид из любого количества браузеров. Код выложен в open-source и доступен на [Github][4]. Под катом я расскажу, на какие недостатки Selenium мы обращали внимание, как пришли к нашему решению, и объясню, как его настроить. [Читать дальше →][5]
[1]: http://docs.seleniumhq.org/
[2]: https://habrastorage.org/files/173/930/c0e/173930c0ec244ae8afa229966e0453d3.png
{kind=link}
[3]: http://habrahabr.ru/company/yandex/blog/268309/
[4]: https://github.com/seleniumkit/gridrouter
[5]: http://habrahabr.ru/post/268309/#habracut
[>]
Эм, но наша вина тут в чем? Мы выдаем эти сим-карты или что? (с) Вконтакте
habra.15
habrabot(difrex,1) — All
2015-10-06 20:00:02
У подруги моей жены увели с банковского счета приличную сумму денег, и сделали это, видимо, используя полученный обманным путем дубликат сим-карты на ее номер телефона. Официального заключения следствия еще нет, это всего лишь предположение сотрудника банка. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268357/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 20:00:02
У подруги моей жены увели с банковского счета приличную сумму денег, и сделали это, видимо, используя полученный обманным путем дубликат сим-карты на ее номер телефона. Официального заключения следствия еще нет, это всего лишь предположение сотрудника банка. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268357/#habracut
[>]
Расчет формул в офисных редакторах. Часть 1
habra.15
habrabot(difrex,1) — All
2015-10-06 22:00:04
_Картинка для привлечения внимания. Механический калькулятор_ Здравствуйте. Сегодня мы хотим представить вашему вниманию вводную статью о формулах в офисных редакторах. Также коснемся того, как задачу представления и расчета формул мы решаем в ядре редактора **[МойОфис][1]**, и наметим план будущих статей по этой теме. [Читать дальше →][2]
[1]: http://myoffice.ru/product-apps.html
[2]: http://habrahabr.ru/post/268351/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-06 22:00:04
_Картинка для привлечения внимания. Механический калькулятор_ Здравствуйте. Сегодня мы хотим представить вашему вниманию вводную статью о формулах в офисных редакторах. Также коснемся того, как задачу представления и расчета формул мы решаем в ядре редактора **[МойОфис][1]**, и наметим план будущих статей по этой теме. [Читать дальше →][2]
[1]: http://myoffice.ru/product-apps.html
[2]: http://habrahabr.ru/post/268351/#habracut
[>]
Jii: Полноценное приложение с архитектурой Yii2 в браузере
habra.15
habrabot(difrex,1) — All
2015-10-07 01:30:03
Привет всем хабровчанам, любителям **Yii** и **Node.js**. Продолжаю серию статей про Jii, на сей раз настала очередь рассказать о том, что Jii можно использовать в браузере.
Представьте, уже сейчас все структуры фреймворка, такие как [приложения][1], [компоненты][2], [контроллеры][3], [модули][4], модели, представления доступны в браузере! [Читать дальше →][5]
[1]: http://www.jiiframework.ru/guide/structure-applications
[2]: http://www.jiiframework.ru/guide/concept-components
[3]: http://www.jiiframework.ru/guide/structure-controllers
[4]: http://www.jiiframework.ru/guide/structure-modules
[5]: http://habrahabr.ru/post/268361/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 01:30:03
Привет всем хабровчанам, любителям **Yii** и **Node.js**. Продолжаю серию статей про Jii, на сей раз настала очередь рассказать о том, что Jii можно использовать в браузере.
Представьте, уже сейчас все структуры фреймворка, такие как [приложения][1], [компоненты][2], [контроллеры][3], [модули][4], модели, представления доступны в браузере! [Читать дальше →][5]
[1]: http://www.jiiframework.ru/guide/structure-applications
[2]: http://www.jiiframework.ru/guide/concept-components
[3]: http://www.jiiframework.ru/guide/structure-controllers
[4]: http://www.jiiframework.ru/guide/structure-modules
[5]: http://habrahabr.ru/post/268361/#habracut
[>]
[Из песочницы] Использование Remote API в робосимуляторе V-REP
habra.15
habrabot(difrex,1) — All
2015-10-07 08:30:04
![][1] V-REP представляет собой среду для симулирования (sandbox) различных видов роботов, при этом пользователю нет необходимости иметь физический доступ к реальной машине, что экономит деньги и время. Среда V-REP предоставляет удобный интерфейс для визуализации действий робота в трёхмерном виртуальном пространстве намного раньше, чем реальный прототип робота будет создан. При помощи данного руководства вы убедитесь, что для того, чтобы работать в данной среде, программисту не нужно иметь большого технического опыта в области роботостроения. Причиной создания данного руководства стало отсутствие (на то время) знаний языка Lua, на котором по умолчанию написаны все скрипты управления роботом, и его меньшая популярность. Цель данного руководства показать как пользоваться удалённым (Remote) API данной среды на примере языка Python. [Читать дальше →][2]
[1]: https://habrastorage.org/files/780/5fe/19e/7805fe19e40841e590867585770397fc.jpg
[2]: http://habrahabr.ru/post/268313/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 08:30:04
![][1] V-REP представляет собой среду для симулирования (sandbox) различных видов роботов, при этом пользователю нет необходимости иметь физический доступ к реальной машине, что экономит деньги и время. Среда V-REP предоставляет удобный интерфейс для визуализации действий робота в трёхмерном виртуальном пространстве намного раньше, чем реальный прототип робота будет создан. При помощи данного руководства вы убедитесь, что для того, чтобы работать в данной среде, программисту не нужно иметь большого технического опыта в области роботостроения. Причиной создания данного руководства стало отсутствие (на то время) знаний языка Lua, на котором по умолчанию написаны все скрипты управления роботом, и его меньшая популярность. Цель данного руководства показать как пользоваться удалённым (Remote) API данной среды на примере языка Python. [Читать дальше →][2]
[1]: https://habrastorage.org/files/780/5fe/19e/7805fe19e40841e590867585770397fc.jpg
{kind=link}
[2]: http://habrahabr.ru/post/268313/#habracut
[>]
DTO vs POCO vs Value Object
habra.15
habrabot(difrex,1) — All
2015-10-07 10:30:03
В этой статье я бы хотел прояснить различия между DTO (Data Transfer Object), Value Object и POCO (Plain Old CLR Object), также известным как POJO в среде Java. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268371/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 10:30:03
В этой статье я бы хотел прояснить различия между DTO (Data Transfer Object), Value Object и POCO (Plain Old CLR Object), также известным как POJO в среде Java. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268371/#habracut
[>]
RailsStuff — набор для разработки на рельсах
habra.15
habrabot(difrex,1) — All
2015-10-07 14:00:07
![image][1] Недавно мы опубликовали гем [RailsStuff][2]. Это коллекция небольших модулей и утилит для выполнения самых разных частых задач: от организации контроллеров и генерации уникальных случайных значений до парсера параметров и хэлперов переводов. В этом посте я расскажу про некоторые из них:
* ResourcesController — облегчённая и современная версия InheritedResources;
* Трекер типов;
* Генератор уникальных случайных значений;
* Хэлперы переводов и основных ссылок.
[Читать дальше →][3]
[1]: https://habrastorage.org/getpro/habr/post_images/3ce/2fe/a1e/3ce2fea1e154197aa7d9b1a252e890ca.png
[2]: https://github.com/printercu/rails_stuff
[3]: http://habrahabr.ru/post/268359/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 14:00:07
![image][1] Недавно мы опубликовали гем [RailsStuff][2]. Это коллекция небольших модулей и утилит для выполнения самых разных частых задач: от организации контроллеров и генерации уникальных случайных значений до парсера параметров и хэлперов переводов. В этом посте я расскажу про некоторые из них:
* ResourcesController — облегчённая и современная версия InheritedResources;
* Трекер типов;
* Генератор уникальных случайных значений;
* Хэлперы переводов и основных ссылок.
[Читать дальше →][3]
[1]: https://habrastorage.org/getpro/habr/post_images/3ce/2fe/a1e/3ce2fea1e154197aa7d9b1a252e890ca.png
{kind=link}
[2]: https://github.com/printercu/rails_stuff
[3]: http://habrahabr.ru/post/268359/#habracut
[>]
[Перевод] Сайд-проекты — почему это важно для разработчика
habra.15
habrabot(difrex,1) — All
2015-10-07 14:00:07
[![][1]][2] **Мы в [Alconost][3] весьма любим и ценим сторонние проекты, и порой отвлекаемся на них прямо в рабочее время. Так родились бесшабашные и задорные видео [о стобаксовой купюре][4] в разных художественных стилях, о том, [как сделать инфографику вирусной][5], [об истинной цене ожидания][6] в Интернете… У этих роликов не было заказчика — мы просто получили удовольствие, придумывая, рисуя и анимируя их. Для программистов сайд-проекты тоже имеют особое значение. Мы перевели целую статью шведского предпринимателя и разработчика Дэвида Эльбе об этом.** [![][7]][8]Я встречал сотни разработчиков. У лучших из них всегда были сторонние проекты, над которыми они колдовали по ночам. Как работодатель, я это всячески поддерживаю. Но существует немало компаний, которые запрещают подобную деятельность. Давайте поговорим о том, почему я считаю сайд-проекты хорошей идеей, как использую их для саморазвития и на что вам стоит обращать внимание. [Читать дальше →][9]
[1]: https://habrastorage.org/files/c68/ce3/d61/c68ce3d6154741b09b2554c389a87d70.jpg
[2]: http://alconost.com/?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=side-projects
[3]: http://alconost.com/?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=side-projects
[4]: https://www.youtube.com/watch?v=88BBtR9clh8
[5]: https://www.youtube.com/watch?v=h67olu3IFug
[6]: https://www.youtube.com/watch?v=98dfCH9Mu3c
[7]: https://habrastorage.org/files/1e0/13b/dbe/1e013bdbeae748cfbd7d1e613aa60c9c.png
[8]: http://alconost.com/?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=side-projects
[9]: http://habrahabr.ru/post/268367/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 14:00:07
[![][1]][2] **Мы в [Alconost][3] весьма любим и ценим сторонние проекты, и порой отвлекаемся на них прямо в рабочее время. Так родились бесшабашные и задорные видео [о стобаксовой купюре][4] в разных художественных стилях, о том, [как сделать инфографику вирусной][5], [об истинной цене ожидания][6] в Интернете… У этих роликов не было заказчика — мы просто получили удовольствие, придумывая, рисуя и анимируя их. Для программистов сайд-проекты тоже имеют особое значение. Мы перевели целую статью шведского предпринимателя и разработчика Дэвида Эльбе об этом.** [![][7]][8]Я встречал сотни разработчиков. У лучших из них всегда были сторонние проекты, над которыми они колдовали по ночам. Как работодатель, я это всячески поддерживаю. Но существует немало компаний, которые запрещают подобную деятельность. Давайте поговорим о том, почему я считаю сайд-проекты хорошей идеей, как использую их для саморазвития и на что вам стоит обращать внимание. [Читать дальше →][9]
[1]: https://habrastorage.org/files/c68/ce3/d61/c68ce3d6154741b09b2554c389a87d70.jpg
{kind=link}
[2]: http://alconost.com/?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=side-projects
[3]: http://alconost.com/?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=side-projects
[4]: https://www.youtube.com/watch?v=88BBtR9clh8
[5]: https://www.youtube.com/watch?v=h67olu3IFug
[6]: https://www.youtube.com/watch?v=98dfCH9Mu3c
[7]: https://habrastorage.org/files/1e0/13b/dbe/1e013bdbeae748cfbd7d1e613aa60c9c.png
{kind=link}
[8]: http://alconost.com/?utm_source=habrahabr&utm_medium=article&utm_campaign=translation&utm_content=side-projects
[9]: http://habrahabr.ru/post/268367/#habracut
[>]
Codebattle: игра для программистов
habra.15
habrabot(difrex,1) — All
2015-10-07 16:30:04
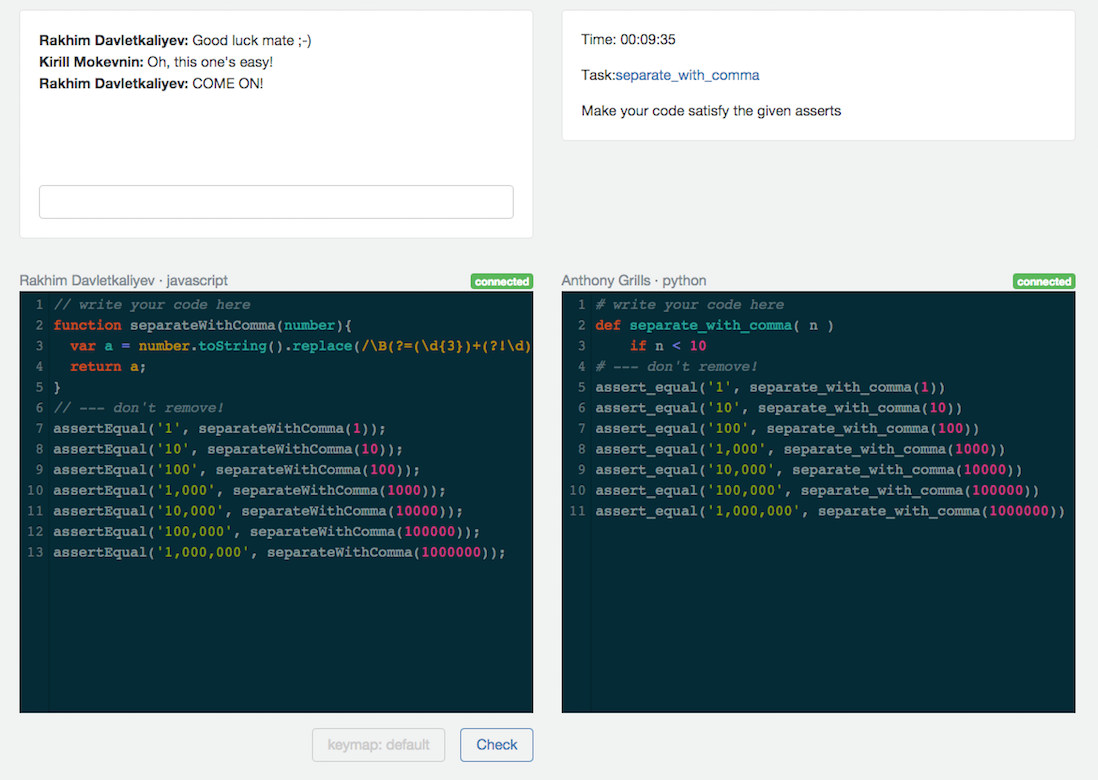
Привет, Хабрахабр! Мы в Хекслете любим не только учиться и учить, но и развлекаться. Но развлекаться по-своему, по-программерски. Поэтому мы запустили [Codebattle][1]. Это игра для программистов. Идея очень простая: вам и сопернику дается задача, вы решаете ее на выбранном вами языке. Вы видите код соперника в реальном времени, результаты запуска тестов и можете общаться с ним и зрителями в чате. Кто первый решит задачу (удовлетворит тестам) — тот победил. [![][2]][3] [Читать дальше →][4]
[1]: http://battle.hexlet.io/
[2]: https://habrastorage.org/files/91b/e3a/5b3/91be3a5b3cfd40bbb92ba9329729fa22.png
[3]: http://battle.hexlet.io/
[4]: http://habrahabr.ru/post/268389/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 16:30:04
Привет, Хабрахабр! Мы в Хекслете любим не только учиться и учить, но и развлекаться. Но развлекаться по-своему, по-программерски. Поэтому мы запустили [Codebattle][1]. Это игра для программистов. Идея очень простая: вам и сопернику дается задача, вы решаете ее на выбранном вами языке. Вы видите код соперника в реальном времени, результаты запуска тестов и можете общаться с ним и зрителями в чате. Кто первый решит задачу (удовлетворит тестам) — тот победил. [![][2]][3] [Читать дальше →][4]
[1]: http://battle.hexlet.io/
[2]: https://habrastorage.org/files/91b/e3a/5b3/91be3a5b3cfd40bbb92ba9329729fa22.png
{kind=link}
[3]: http://battle.hexlet.io/
[4]: http://habrahabr.ru/post/268389/#habracut
[>]
[Из песочницы] Функциональные тесты: Django + Selenium WebDriver и 3 варианта на Ваш выбор
habra.15
habrabot(difrex,1) — All
2015-10-07 16:30:04
> «В жизни каждого django-разработчика наступает момент, когда он решительно рвет со своим прошлым, лишенным функционального тестирования!»
Об этом и поговорим. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268385/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 16:30:04
> «В жизни каждого django-разработчика наступает момент, когда он решительно рвет со своим прошлым, лишенным функционального тестирования!»
Об этом и поговорим. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268385/#habracut
[>]
Создание загружаемых модулей Zabbix на примере добавления протокола Modbus
habra.15
habrabot(difrex,1) — All
2015-10-07 17:30:03
Еще в версии Zabbix 2.2 добавились загружаемые модули, которые позволили расширять на новом уровне возможности системы. «Зачем это нужно?», — спросите вы, ведь запускать внешние скрипты и программы из Zabbix можно было всегда. Конечно, в первую очередь это скорость — модули, как и сам Zabbix, пишутся на C и при правильном подходе работают максимально быстро, в отличие от внешних программ, которые требуется запускать на каждый опрос. Многих может напугать необходимость писать код, но сегодня я хочу показать вам, что все не так уж и сложно. Для примера, напишем модуль, который позволит Zabbix собирать информацию с устройств, работающих по широко распространённому в мире протоколу промышленной автоматизации — Modbus и снимем при помощи него показания температурных датчиков, а также получим параметры электроэнергии с счетчика Меркурий 230. В конце разместим наш модуль на портале [share.zabbix.com][1], где пользователи могут делиться своими наработками по Zabbix. ![][2] [Читать дальше →][3]
[1]: https://share.zabbix.com
[2]: https://habrastorage.org/files/3d5/924/c83/3d5924c8386d4bb387d7e4e766eda0a1.jpg
[3]: http://habrahabr.ru/post/268119/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 17:30:03
Еще в версии Zabbix 2.2 добавились загружаемые модули, которые позволили расширять на новом уровне возможности системы. «Зачем это нужно?», — спросите вы, ведь запускать внешние скрипты и программы из Zabbix можно было всегда. Конечно, в первую очередь это скорость — модули, как и сам Zabbix, пишутся на C и при правильном подходе работают максимально быстро, в отличие от внешних программ, которые требуется запускать на каждый опрос. Многих может напугать необходимость писать код, но сегодня я хочу показать вам, что все не так уж и сложно. Для примера, напишем модуль, который позволит Zabbix собирать информацию с устройств, работающих по широко распространённому в мире протоколу промышленной автоматизации — Modbus и снимем при помощи него показания температурных датчиков, а также получим параметры электроэнергии с счетчика Меркурий 230. В конце разместим наш модуль на портале [share.zabbix.com][1], где пользователи могут делиться своими наработками по Zabbix. ![][2] [Читать дальше →][3]
[1]: https://share.zabbix.com
[2]: https://habrastorage.org/files/3d5/924/c83/3d5924c8386d4bb387d7e4e766eda0a1.jpg
{kind=link}
[3]: http://habrahabr.ru/post/268119/#habracut
[>]
Технокнига, часть 4: литература по управлению продуктом, разработке веб-сервисов, управлению веб-проектами, бизнесу и системному анализу архитекторов
habra.15
habrabot(difrex,1) — All
2015-10-07 18:30:03
![][1] Мы продолжаем публиковать список рекомендуемой литературы для студентов [Технопарка][2]. На этот раз вас ждет заключительная часть, рассчитанная на студентов 4 семестра. Предыдущие части: [первая][3], [вторая][4], [третья][5]. [Читать дальше →][6]
[1]: https://habrastorage.org/files/1b4/178/8a8/1b41788a80e04dababa8eb914646d9c9.jpg
[2]: https://park.mail.ru/
[3]: http://habrahabr.ru/company/mailru/blog/265103/
[4]: http://habrahabr.ru/company/mailru/blog/266065/
[5]: http://habrahabr.ru/company/mailru/blog/267579/
[6]: http://habrahabr.ru/post/268395/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 18:30:03
![][1] Мы продолжаем публиковать список рекомендуемой литературы для студентов [Технопарка][2]. На этот раз вас ждет заключительная часть, рассчитанная на студентов 4 семестра. Предыдущие части: [первая][3], [вторая][4], [третья][5]. [Читать дальше →][6]
[1]: https://habrastorage.org/files/1b4/178/8a8/1b41788a80e04dababa8eb914646d9c9.jpg
{kind=link}
[2]: https://park.mail.ru/
[3]: http://habrahabr.ru/company/mailru/blog/265103/
[4]: http://habrahabr.ru/company/mailru/blog/266065/
[5]: http://habrahabr.ru/company/mailru/blog/267579/
[6]: http://habrahabr.ru/post/268395/#habracut
[>]
Добавить системный вызов. Часть 4 и последняя
habra.15
habrabot(difrex,1) — All
2015-10-07 20:30:03
__
- Что-то беспокоит меня Гондурас...
- Беспокоит? А ты его не чеши.
В предыдущих частях обсуждения ([1-я][1], [2-я][2] и [3-я][3]) мы рассматривали как, используя возможность поменять содержимое sys\_call\_table, **изменить** поведение того или иного системного вызова Linux. Сейчас мы продолжим эксперименты в сторону того, можно ли (и как) динамически **добавить** новый системный вызов в целях вашего программного проекта. [Читать дальше →][4]
[1]: http://habrahabr.ru/post/267535/
[2]: http://habrahabr.ru/post/267773/
[3]: http://habrahabr.ru/post/268145/
[4]: http://habrahabr.ru/post/268409/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 20:30:03
__
- Что-то беспокоит меня Гондурас...
- Беспокоит? А ты его не чеши.
В предыдущих частях обсуждения ([1-я][1], [2-я][2] и [3-я][3]) мы рассматривали как, используя возможность поменять содержимое sys\_call\_table, **изменить** поведение того или иного системного вызова Linux. Сейчас мы продолжим эксперименты в сторону того, можно ли (и как) динамически **добавить** новый системный вызов в целях вашего программного проекта. [Читать дальше →][4]
[1]: http://habrahabr.ru/post/267535/
[2]: http://habrahabr.ru/post/267773/
[3]: http://habrahabr.ru/post/268145/
[4]: http://habrahabr.ru/post/268409/#habracut
[>]
Диагностируем причину, выживаем в JAR hell: не дышим серой и не варимся в котле
habra.15
habrabot(difrex,1) — All
2015-10-07 21:00:04
Бывает что в крупном проекте работающем в jvm, _внезапно_ обнаруживается что приложение не работает и даже не запускается при обновлении какой-либо из зависимостей проекта. Такое же возможно из-за любого другого события, которое изменило порядок следования библиотек в classpath приложения. ![][1] [Добро пожаловать в JAR hell][2]
[1]: https://habrastorage.org/files/c23/5bf/678/c235bf678a904d86aa0cffeb55d9e418.jpg
[2]: http://habrahabr.ru/post/268393/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-07 21:00:04
Бывает что в крупном проекте работающем в jvm, _внезапно_ обнаруживается что приложение не работает и даже не запускается при обновлении какой-либо из зависимостей проекта. Такое же возможно из-за любого другого события, которое изменило порядок следования библиотек в classpath приложения. ![][1] [Добро пожаловать в JAR hell][2]
[1]: https://habrastorage.org/files/c23/5bf/678/c235bf678a904d86aa0cffeb55d9e418.jpg
{kind=link}
[2]: http://habrahabr.ru/post/268393/#habracut
[>]
[Из песочницы] Подключение двух принтеров к Thinstation и привязка их к портам
habra.15
habrabot(difrex,1) — All
2015-10-08 10:30:02
Бывает такая проблема что в конфиге принтерам назначены /dev/usb/lp0 и /dev/usb/lp1, а они вдруг меняются портами. Происходит это из-за того, что в Thinstation принтеры подключаются по принципу «кто первый встал — того и тапки», т.е. какой первый загрузился — того и /dev/usb/lp0. Короче, исправляем. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268345/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 10:30:02
Бывает такая проблема что в конфиге принтерам назначены /dev/usb/lp0 и /dev/usb/lp1, а они вдруг меняются портами. Происходит это из-за того, что в Thinstation принтеры подключаются по принципу «кто первый встал — того и тапки», т.е. какой первый загрузился — того и /dev/usb/lp0. Короче, исправляем. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268345/#habracut
[>]
DHCP сервер на нескольких VLAN
habra.15
habrabot(difrex,1) — All
2015-10-08 10:30:03
Постановка задачи. Под термином “клиент” будем понимать зону ответственности за совокупность сетевых устройств. Требуется обеспечить доступ для нескольких сотен клиентов к неким общим ресурсам в таком режиме, чтобы:
1. Каждый клиент не видел трафик остальных клиентов.
2. Неисправности одного клиента (broadcast-storm, конфликты IP-адресов, не санкционированные DHCP-сервера клиента и т.п.) не должны влиять на работу как других клиентов, так и всей системы в целом.
3. Каждый клиент не должен напрямую получать доступ к ресурсам других клиентов (хотя, как специальный случай, можно предусмотреть и разрешение данного трафика, но с его централизованным контролем и/или управлением ).
4. Клиенты должны иметь возможность получения доступа к общим внешним ресурсам (которыми могут быть как отдельные сервера, так и сеть Интернет в целом).
5. Общие ресурсы должны также иметь возможность доступа к ресурсам клиентов (конечно при условии, что известен общему ресурсу известен IP-адрес ресурса клиента).
6. Адресное пространство для клиентов выделяется централизованно и его администрирование не должно быть чрезмерно сложным.
В качестве примеров практического применения можно назвать изоляцию локальных сетей отделов в крупной организации, организацию VoIP-связи или доступа в сеть Интернет для нескольких независимых потребителей и т.п. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268331/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 10:30:03
Постановка задачи. Под термином “клиент” будем понимать зону ответственности за совокупность сетевых устройств. Требуется обеспечить доступ для нескольких сотен клиентов к неким общим ресурсам в таком режиме, чтобы:
1. Каждый клиент не видел трафик остальных клиентов.
2. Неисправности одного клиента (broadcast-storm, конфликты IP-адресов, не санкционированные DHCP-сервера клиента и т.п.) не должны влиять на работу как других клиентов, так и всей системы в целом.
3. Каждый клиент не должен напрямую получать доступ к ресурсам других клиентов (хотя, как специальный случай, можно предусмотреть и разрешение данного трафика, но с его централизованным контролем и/или управлением ).
4. Клиенты должны иметь возможность получения доступа к общим внешним ресурсам (которыми могут быть как отдельные сервера, так и сеть Интернет в целом).
5. Общие ресурсы должны также иметь возможность доступа к ресурсам клиентов (конечно при условии, что известен общему ресурсу известен IP-адрес ресурса клиента).
6. Адресное пространство для клиентов выделяется централизованно и его администрирование не должно быть чрезмерно сложным.
В качестве примеров практического применения можно назвать изоляцию локальных сетей отделов в крупной организации, организацию VoIP-связи или доступа в сеть Интернет для нескольких независимых потребителей и т.п. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268331/#habracut
[>]
Решение проблемы установки разрешения экрана в Thinstation
habra.15
habrabot(difrex,1) — All
2015-10-08 10:30:03
В продолжение предыдущих статей ([Экономим электричество на тонких клиентах][1], [Подключение двух принтеров к Thinstation и привязка их к портам][2], [Мониторинг и управление Thinstation 5.x][3]) продолжу делиться опытом настройки Thinstation. С переходом на Thinstation-5 часто возникает проблема «неправильного» разрешения экрана, хоть опция **SCREEN\_RESOLUTION=\*\*\*x\*\*\*** и определена. Этот глюк разработчики почему-то тащат из версии в версию, несмотря на мои сообщения в багтрекере. Приходится исправлять каждый раз вручную. [Читать дальше →][4]
[1]: http://habrahabr.ru/post/268349/
[2]: http://habrahabr.ru/post/268345/
[3]: http://habrahabr.ru/sandbox/97325/
[4]: http://habrahabr.ru/post/268375/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 10:30:03
В продолжение предыдущих статей ([Экономим электричество на тонких клиентах][1], [Подключение двух принтеров к Thinstation и привязка их к портам][2], [Мониторинг и управление Thinstation 5.x][3]) продолжу делиться опытом настройки Thinstation. С переходом на Thinstation-5 часто возникает проблема «неправильного» разрешения экрана, хоть опция **SCREEN\_RESOLUTION=\*\*\*x\*\*\*** и определена. Этот глюк разработчики почему-то тащат из версии в версию, несмотря на мои сообщения в багтрекере. Приходится исправлять каждый раз вручную. [Читать дальше →][4]
[1]: http://habrahabr.ru/post/268349/
[2]: http://habrahabr.ru/post/268345/
[3]: http://habrahabr.ru/sandbox/97325/
[4]: http://habrahabr.ru/post/268375/#habracut
[>]
Ищем стабильность в ритейле, XYZ–анализ ассортимента
habra.15
habrabot(difrex,1) — All
2015-10-08 10:30:03
XYZ–анализ — одна из форм анализа товарного ассортимента магазина, сети или отдельной товарной группы в ритейле. [][1]
**XYZ–анализ** определяет стабильность продаж товара за определенный период. Полезен для управления ассортиментом и поставками товаров, организации работы с поставщиками. Результаты позволяют разделить товары по категориям и выделить для них место на складе, уровень запасов и организацию доставки. Как отдельный метод анализа в ритейле XYZ используется не так уж часто, чаще его можно встретить как совмещенный с [**АВС анализом**][2]. Но, в любом случае, как метод для принятия решений по управлению ассортиментом товарной группы или магазина может принести несомненную пользу. Начнем с рассмотрения его особенностей и возможностей применения. [Читать дальше →][3]
[1]: http://habrahabr.ru/company/datawiz/blog/268341/
[2]: http://habrahabr.ru/company/datawiz/blog/267175/
[3]: http://habrahabr.ru/post/268341/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 10:30:03
XYZ–анализ — одна из форм анализа товарного ассортимента магазина, сети или отдельной товарной группы в ритейле. [][1]
**XYZ–анализ** определяет стабильность продаж товара за определенный период. Полезен для управления ассортиментом и поставками товаров, организации работы с поставщиками. Результаты позволяют разделить товары по категориям и выделить для них место на складе, уровень запасов и организацию доставки. Как отдельный метод анализа в ритейле XYZ используется не так уж часто, чаще его можно встретить как совмещенный с [**АВС анализом**][2]. Но, в любом случае, как метод для принятия решений по управлению ассортиментом товарной группы или магазина может принести несомненную пользу. Начнем с рассмотрения его особенностей и возможностей применения. [Читать дальше →][3]
[1]: http://habrahabr.ru/company/datawiz/blog/268341/
[2]: http://habrahabr.ru/company/datawiz/blog/267175/
[3]: http://habrahabr.ru/post/268341/#habracut
[>]
[Перевод] Перевод: Один год с Go
habra.15
habrabot(difrex,1) — All
2015-10-08 11:00:04
![][1]Под катом — перевод статьи опытного разработчика о его опыте практического применения Go. **** — мнение переводчика может не совпадать с мнением автора статьи. [почитать что он там пишет][2]
[1]: https://habrastorage.org/files/a18/7de/a26/a187dea263874a3c8f07166c844c209e.png
[2]: http://habrahabr.ru/post/268411/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 11:00:04
![][1]Под катом — перевод статьи опытного разработчика о его опыте практического применения Go. **** — мнение переводчика может не совпадать с мнением автора статьи. [почитать что он там пишет][2]
[1]: https://habrastorage.org/files/a18/7de/a26/a187dea263874a3c8f07166c844c209e.png
{kind=link}
[2]: http://habrahabr.ru/post/268411/#habracut
[>]
USB killer v2.0
habra.15
habrabot(difrex,1) — All
2015-10-08 12:30:03
Наконец-то удалось организовать монтаж и тестирование опытных образцов устройства новой версии. Устройства, выполняющего лишь одну функцию, – уничтожение компьютеров. Впрочем, не будем ограничиваться только компьютерами, устройство способно вывести из строя практически любую технику оборудованную USB Host интерфейсом. К примеру, у меня на столе стоит осциллограф с USB интерфейсом (но он ещё пригодится), практически все смартфоны поддерживают USB OTG режим, TV, роутеры, модемы и т.д. [Подробности][1]
[1]: http://habrahabr.ru/post/268421/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 12:30:03
Наконец-то удалось организовать монтаж и тестирование опытных образцов устройства новой версии. Устройства, выполняющего лишь одну функцию, – уничтожение компьютеров. Впрочем, не будем ограничиваться только компьютерами, устройство способно вывести из строя практически любую технику оборудованную USB Host интерфейсом. К примеру, у меня на столе стоит осциллограф с USB интерфейсом (но он ещё пригодится), практически все смартфоны поддерживают USB OTG режим, TV, роутеры, модемы и т.д. [Подробности][1]
[1]: http://habrahabr.ru/post/268421/#habracut
[>]
Поисковые подсказки изнутри
habra.15
habrabot(difrex,1) — All
2015-10-08 12:30:03
Ночная зала. Тысячи таинственных ликов в темноте, подсвеченных голубоватым свечением мониторов. Оглушительный треск миллиона клавиш. Подобные выстрелам автомата удары по клавишам «Enter». Зловещее стрекотание сотен тысяч мышек… Так, наверняка, играло воображение каждого разработчика высоконагруженной системы. И если его вовремя не остановить, то может выйти целый триллер или фильм ужасов. Но в данной статье мы будем гораздо ближе к земле. Мы кратко рассмотрим известные подходы к решению задачи поисковых подсказок, как мы научились делать их полнотекстовыми, а также расскажем о парочке уловок, на которые мы пошли, чтобы придать им скорости, но при этом не научить жадности к ресурсам. В конце статьи вас ждёт бонус — небольшой рабочий пример. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/267469/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 12:30:03
Ночная зала. Тысячи таинственных ликов в темноте, подсвеченных голубоватым свечением мониторов. Оглушительный треск миллиона клавиш. Подобные выстрелам автомата удары по клавишам «Enter». Зловещее стрекотание сотен тысяч мышек… Так, наверняка, играло воображение каждого разработчика высоконагруженной системы. И если его вовремя не остановить, то может выйти целый триллер или фильм ужасов. Но в данной статье мы будем гораздо ближе к земле. Мы кратко рассмотрим известные подходы к решению задачи поисковых подсказок, как мы научились делать их полнотекстовыми, а также расскажем о парочке уловок, на которые мы пошли, чтобы придать им скорости, но при этом не научить жадности к ресурсам. В конце статьи вас ждёт бонус — небольшой рабочий пример. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/267469/#habracut
[>]
Экономим электричество на тонких клиентах
habra.15
habrabot(difrex,1) — All
2015-10-08 17:30:03
В целях экономии электроэнергии на работе вышла директива: на выходные и праздники, а так же на ночь, все компьютеры, кроме критичных, должны быть выключены. Но как водится — кто то да забудет. Для тонких клиентов есть два решения — поднять [TSmon][1] и с него рулить или подключится к клиенту по ssh и дать команду на выключение. По большому счёту сам процесс не сложный — добавляем в сборку пакет **sshd**, задаём пароль для root в файле **build.conf** параметром **param rootpasswd**, собираем образ, загружаем, когда надо логинимся по ssh на клиенте и выключаем, но интереснее разослать всем нужным клиентам сигнал на выключение одной командой, без лишних телодвижений. Почему не telnet — потому что по ssh проще сделать автологин, без костылей типа perl и expect. Далее описан способ реализации. [Читать дальше →][2]
[1]: http://thinstation.pro/thin/101-tsmon.html
[2]: http://habrahabr.ru/post/268349/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 17:30:03
В целях экономии электроэнергии на работе вышла директива: на выходные и праздники, а так же на ночь, все компьютеры, кроме критичных, должны быть выключены. Но как водится — кто то да забудет. Для тонких клиентов есть два решения — поднять [TSmon][1] и с него рулить или подключится к клиенту по ssh и дать команду на выключение. По большому счёту сам процесс не сложный — добавляем в сборку пакет **sshd**, задаём пароль для root в файле **build.conf** параметром **param rootpasswd**, собираем образ, загружаем, когда надо логинимся по ssh на клиенте и выключаем, но интереснее разослать всем нужным клиентам сигнал на выключение одной командой, без лишних телодвижений. Почему не telnet — потому что по ssh проще сделать автологин, без костылей типа perl и expect. Далее описан способ реализации. [Читать дальше →][2]
[1]: http://thinstation.pro/thin/101-tsmon.html
[2]: http://habrahabr.ru/post/268349/#habracut
[>]
[Перевод] Основные сертификаты информационной безопасности для ИТ-специалистов и предприятий
habra.15
habrabot(difrex,1) — All
2015-10-08 17:30:03
![][1] Даже если просто просматривать заголовки новостей, то этого достаточно, чтобы понимать: в сфере информационной безопасности постоянно появляются новые угрозы и уязвимости. А потому предприятиям крайне важно иметь возможность осуществлять подготовку своих профессионалов в области безопасности в таком объеме, как того требует их стратегия ИТ-управления. Это означает, что существует только один вопрос: как лучше всего, с одной стороны, специалистам получить адекватное обучение (что сделает их более востребованными на рынке труда), а с другой стороны, предприятиям улучшить свои протоколы и процедуры безопасности (и продемонстрировать своим клиентам чувство безопасности)? Правильные решения – это сертификаты безопасности, которые допускают сочетания минимальных требований, стандартизированного языка и профессионального кодекса этики. Если мы, как специалисты и руководители предприятий решили взять курс в управлении ИТ-безопасностью, то рекомендуется выбирать сертификаты ведущих международных и независимых организаций. С учетом этого, в данной статье мы приводим некоторые из доступных наиболее серьезных сертификационных программ: **CISA / CISM** CISA и CISM– это две основные аккредитации, выдаваемые ассоциацией [Читать дальше →][2]
[1]: https://habrastorage.org/files/b60/a88/0a9/b60a880a92b245c3bae883782e971bdd.jpg
[2]: http://habrahabr.ru/post/268453/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 17:30:03
![][1] Даже если просто просматривать заголовки новостей, то этого достаточно, чтобы понимать: в сфере информационной безопасности постоянно появляются новые угрозы и уязвимости. А потому предприятиям крайне важно иметь возможность осуществлять подготовку своих профессионалов в области безопасности в таком объеме, как того требует их стратегия ИТ-управления. Это означает, что существует только один вопрос: как лучше всего, с одной стороны, специалистам получить адекватное обучение (что сделает их более востребованными на рынке труда), а с другой стороны, предприятиям улучшить свои протоколы и процедуры безопасности (и продемонстрировать своим клиентам чувство безопасности)? Правильные решения – это сертификаты безопасности, которые допускают сочетания минимальных требований, стандартизированного языка и профессионального кодекса этики. Если мы, как специалисты и руководители предприятий решили взять курс в управлении ИТ-безопасностью, то рекомендуется выбирать сертификаты ведущих международных и независимых организаций. С учетом этого, в данной статье мы приводим некоторые из доступных наиболее серьезных сертификационных программ: **CISA / CISM** CISA и CISM– это две основные аккредитации, выдаваемые ассоциацией [Читать дальше →][2]
[1]: https://habrastorage.org/files/b60/a88/0a9/b60a880a92b245c3bae883782e971bdd.jpg
{kind=link}
[2]: http://habrahabr.ru/post/268453/#habracut
[>]
[Из песочницы] Конференция SGTech Europe 2015: взгляд из России
habra.15
habrabot(difrex,1) — All
2015-10-08 17:30:03
Конференция Smart Grid Technical Forum (SGTech Europe) проводилась в Амстердаме с 22 по 24 сентября 2015 года. SGTech Europe — это ежегодная конференция, которая собирает представителей крупнейших европейских сетевых компаний, компаний-операторов диспетчерского управления, консалтеров и производителей решений в области автоматизации подстанций, телекоммуникаций и информационной безопасности. Формат конференции предусматривал три рабочих дня:
* Первый день — пленарное заседание, работа по трем секциям: автоматизация подстанций, интеграция СКАДА и бизнес сетей, телеком в энергетике, круглые столы по темам.
* Второй день — итоги обсуждений на круглых столах, продолжение докладов по секциям.
* Третий день был тематическим (Smart Sec Europe 2015) и был полностью посвящен вопросам информационной безопасности критических инфраструктур.
Параллельно с конференцией в фойе проходила выставка, было порядка 15 стендов на которых были представлены ведущие поставщики решений по обсуждавшимся на конференции темам, в том числе Schneider Electric, Siemens, Landis+Gyr, Advantech, Sae-IT, Locomation, Satel, Netcontrol, Security Matters, Subnet, Alstom и другие. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268443/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 17:30:03
Конференция Smart Grid Technical Forum (SGTech Europe) проводилась в Амстердаме с 22 по 24 сентября 2015 года. SGTech Europe — это ежегодная конференция, которая собирает представителей крупнейших европейских сетевых компаний, компаний-операторов диспетчерского управления, консалтеров и производителей решений в области автоматизации подстанций, телекоммуникаций и информационной безопасности. Формат конференции предусматривал три рабочих дня:
* Первый день — пленарное заседание, работа по трем секциям: автоматизация подстанций, интеграция СКАДА и бизнес сетей, телеком в энергетике, круглые столы по темам.
* Второй день — итоги обсуждений на круглых столах, продолжение докладов по секциям.
* Третий день был тематическим (Smart Sec Europe 2015) и был полностью посвящен вопросам информационной безопасности критических инфраструктур.
Параллельно с конференцией в фойе проходила выставка, было порядка 15 стендов на которых были представлены ведущие поставщики решений по обсуждавшимся на конференции темам, в том числе Schneider Electric, Siemens, Landis+Gyr, Advantech, Sae-IT, Locomation, Satel, Netcontrol, Security Matters, Subnet, Alstom и другие. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268443/#habracut
[>]
Как сделать fuel-плагин (на примере NFS). Часть 2
habra.15
habrabot(difrex,1) — All
2015-10-08 18:00:05
Действующие лица и исполнители: Александр Кислицкий — автор кода, Евгения Шумахер, Ирина Поволоцкая — полезные замечания и ссылки, Вячеслав Струк — ревью, Илья Стечкин — рассказчик _**Важная оговорка:** мир плагинов очень быстро развивается. То, что описано ниже, актуально для плагинов, созданных под [MOS 6.0][1]. Напомним, что MOS — это Mirantis OpenStack, наш дистрибутив, открытый, как и все, что мы делаем. Однако на прошлой неделе было официально объявлено об официальном выпуске [MOS 7.0][2], а это совсем другая история, которую мы тоже постараемся рассказать. Но в другой раз. Для ленивых копипастеров сразу предлагаем ссылку на [GitHub][3] и напоминаем, что лень — двигатель прогресса._ [Читать дальше →][4]
[1]: https://software.mirantis.com/releases/
[2]: https://software.mirantis.com/openstack-download-form/
[3]: https://github.com/stackforge-attic/fuel-plugin-external-nfs
[4]: http://habrahabr.ru/post/268315/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 18:00:05
Действующие лица и исполнители: Александр Кислицкий — автор кода, Евгения Шумахер, Ирина Поволоцкая — полезные замечания и ссылки, Вячеслав Струк — ревью, Илья Стечкин — рассказчик _**Важная оговорка:** мир плагинов очень быстро развивается. То, что описано ниже, актуально для плагинов, созданных под [MOS 6.0][1]. Напомним, что MOS — это Mirantis OpenStack, наш дистрибутив, открытый, как и все, что мы делаем. Однако на прошлой неделе было официально объявлено об официальном выпуске [MOS 7.0][2], а это совсем другая история, которую мы тоже постараемся рассказать. Но в другой раз. Для ленивых копипастеров сразу предлагаем ссылку на [GitHub][3] и напоминаем, что лень — двигатель прогресса._ [Читать дальше →][4]
[1]: https://software.mirantis.com/releases/
[2]: https://software.mirantis.com/openstack-download-form/
[3]: https://github.com/stackforge-attic/fuel-plugin-external-nfs
[4]: http://habrahabr.ru/post/268315/#habracut
[>]
Google выпустила security-обновление для Android
habra.15
habrabot(difrex,1) — All
2015-10-08 18:00:05
Google выпустила обновление для Android, которое закрывает ряд уязвимостей в различных компонентах ОС. В рамках обновления _Nexus Security Bulletin — October 2015_ компания исправила 30 уникальных уязвимостей, включая, уязвимость Stagefright 2.0, о которой мы более подробно писали [здесь][1]. Уязвимости присутствуют в системном компоненте _libstagefright_ и позволяют атакующему удаленно исполнить код в Android с максимальными привилегиями в системе. ![][2] Новое обновление для Android уже третье по счету, в котором Google пытается избавить пользователей от уязвимостей типа Stagefright. Предыдущие обновления закрывали в Android критический для пользователей метод эксплуатации уязвимостей с использованием мультимедийного MMS-сообщения, когда ему даже не нужно открывать само сообщение, при этом эксплойт срабатывает сразу по приходу сообщения. Обновление этого месяца закрывает другой вектор эксплуатации — с использованием мобильного веб-браузера. [Читать дальше →][3]
[1]: http://habrahabr.ru/company/eset/blog/268101/
[2]: //habrastorage.org/files/f95/f81/3fa/f95f813fa42049e6a6c973b85ff5b000.png
[3]: http://habrahabr.ru/post/268291/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-08 18:00:05
Google выпустила обновление для Android, которое закрывает ряд уязвимостей в различных компонентах ОС. В рамках обновления _Nexus Security Bulletin — October 2015_ компания исправила 30 уникальных уязвимостей, включая, уязвимость Stagefright 2.0, о которой мы более подробно писали [здесь][1]. Уязвимости присутствуют в системном компоненте _libstagefright_ и позволяют атакующему удаленно исполнить код в Android с максимальными привилегиями в системе. ![][2] Новое обновление для Android уже третье по счету, в котором Google пытается избавить пользователей от уязвимостей типа Stagefright. Предыдущие обновления закрывали в Android критический для пользователей метод эксплуатации уязвимостей с использованием мультимедийного MMS-сообщения, когда ему даже не нужно открывать само сообщение, при этом эксплойт срабатывает сразу по приходу сообщения. Обновление этого месяца закрывает другой вектор эксплуатации — с использованием мобильного веб-браузера. [Читать дальше →][3]
[1]: http://habrahabr.ru/company/eset/blog/268101/
[2]: //habrastorage.org/files/f95/f81/3fa/f95f813fa42049e6a6c973b85ff5b000.png
[3]: http://habrahabr.ru/post/268291/#habracut
[>]
Коллизия для SHA-1 за 10 дней
habra.15
habrabot(difrex,1) — All
2015-10-09 09:00:05
![image][1] В начале года я [рекомендовал][2] обновить SSL/TLS сертификаты, имеющие подпись с алгоритмом SHA-1. Теперь это стало не просто рекомендацией, а предупреждением. Недавние новости показали — оценка того, что получение коллизии для SHA-1 будет вполне доступно для криминального мира уже к 2018 году, оказалась оптимистичной. Марк Стивенс, Пьер Карпмэн и Томас Пейрин (надеюсь они простят меня за такой перевод их имен) опубликовали [статью][3] и [пресс-релиз][4], в которых призывают как можно скорее отказаться от SHA-1. Они показывают, что создание поддельной подписи, основанной на SHA-1 сейчас может стоить около 100$ тыс., что вполне по карману преступному миру, а не 700$ тыс., как рассчитывал на 2015 год известный криптограф Брюс Шнайер. [Читать дальше →][5]
[1]: https://habrastorage.org/files/40b/7d0/617/40b7d0617d6a4c5493724d5a324c3441.jpg
[2]: http://habrahabr.ru/post/250109/
[3]: https://docs.google.com/viewer?url=https%3A%2F%2Fsites.google.com%2Fsite%2Fitstheshappening%2Fshappening_article.pdf%3Fattredirects%3D0
[4]: https://docs.google.com/viewer?url=https%3A%2F%2Fsites.google.com%2Fsite%2Fitstheshappening%2Fshappening_PR.pdf%3Fattredirects%3D0
[5]: http://habrahabr.ru/post/268495/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 09:00:05
![image][1] В начале года я [рекомендовал][2] обновить SSL/TLS сертификаты, имеющие подпись с алгоритмом SHA-1. Теперь это стало не просто рекомендацией, а предупреждением. Недавние новости показали — оценка того, что получение коллизии для SHA-1 будет вполне доступно для криминального мира уже к 2018 году, оказалась оптимистичной. Марк Стивенс, Пьер Карпмэн и Томас Пейрин (надеюсь они простят меня за такой перевод их имен) опубликовали [статью][3] и [пресс-релиз][4], в которых призывают как можно скорее отказаться от SHA-1. Они показывают, что создание поддельной подписи, основанной на SHA-1 сейчас может стоить около 100$ тыс., что вполне по карману преступному миру, а не 700$ тыс., как рассчитывал на 2015 год известный криптограф Брюс Шнайер. [Читать дальше →][5]
[1]: https://habrastorage.org/files/40b/7d0/617/40b7d0617d6a4c5493724d5a324c3441.jpg
{kind=link}
[2]: http://habrahabr.ru/post/250109/
[3]: https://docs.google.com/viewer?url=https%3A%2F%2Fsites.google.com%2Fsite%2Fitstheshappening%2Fshappening_article.pdf%3Fattredirects%3D0
[4]: https://docs.google.com/viewer?url=https%3A%2F%2Fsites.google.com%2Fsite%2Fitstheshappening%2Fshappening_PR.pdf%3Fattredirects%3D0
[5]: http://habrahabr.ru/post/268495/#habracut
[>]
Коллизия для SHA-1 за 100$ тыс
habra.15
habrabot(difrex,1) — All
2015-10-09 12:00:06
![image][1] В начале года я [рекомендовал][2] обновить SSL/TLS сертификаты, имеющие подпись с алгоритмом SHA-1. Теперь это стало не просто рекомендацией, а предупреждением. Недавние новости показали — оценка того, что получение коллизии для SHA-1 будет вполне доступно для криминального мира уже к 2018 году, оказалась оптимистичной. Марк Стивенс, Пьер Карпмэн и Томас Пейрин (надеюсь они простят меня за такой перевод их имен) опубликовали [статью][3] и [пресс-релиз][4], в которых призывают как можно скорее отказаться от SHA-1. Они показывают, что создание поддельной подписи, основанной на SHA-1 сейчас может стоить около 100$ тыс., что вполне по карману преступному миру, а не 700$ тыс., как рассчитывал на 2015 год известный криптограф Брюс Шнайер. [Читать дальше →][5]
[1]: https://habrastorage.org/files/40b/7d0/617/40b7d0617d6a4c5493724d5a324c3441.jpg
[2]: http://habrahabr.ru/post/250109/
[3]: https://docs.google.com/viewer?url=https%3A%2F%2Fsites.google.com%2Fsite%2Fitstheshappening%2Fshappening_article.pdf%3Fattredirects%3D0
[4]: https://docs.google.com/viewer?url=https%3A%2F%2Fsites.google.com%2Fsite%2Fitstheshappening%2Fshappening_PR.pdf%3Fattredirects%3D0
[5]: http://habrahabr.ru/post/268495/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 12:00:06
![image][1] В начале года я [рекомендовал][2] обновить SSL/TLS сертификаты, имеющие подпись с алгоритмом SHA-1. Теперь это стало не просто рекомендацией, а предупреждением. Недавние новости показали — оценка того, что получение коллизии для SHA-1 будет вполне доступно для криминального мира уже к 2018 году, оказалась оптимистичной. Марк Стивенс, Пьер Карпмэн и Томас Пейрин (надеюсь они простят меня за такой перевод их имен) опубликовали [статью][3] и [пресс-релиз][4], в которых призывают как можно скорее отказаться от SHA-1. Они показывают, что создание поддельной подписи, основанной на SHA-1 сейчас может стоить около 100$ тыс., что вполне по карману преступному миру, а не 700$ тыс., как рассчитывал на 2015 год известный криптограф Брюс Шнайер. [Читать дальше →][5]
[1]: https://habrastorage.org/files/40b/7d0/617/40b7d0617d6a4c5493724d5a324c3441.jpg
[2]: http://habrahabr.ru/post/250109/
[3]: https://docs.google.com/viewer?url=https%3A%2F%2Fsites.google.com%2Fsite%2Fitstheshappening%2Fshappening_article.pdf%3Fattredirects%3D0
[4]: https://docs.google.com/viewer?url=https%3A%2F%2Fsites.google.com%2Fsite%2Fitstheshappening%2Fshappening_PR.pdf%3Fattredirects%3D0
[5]: http://habrahabr.ru/post/268495/#habracut
[>]
Знакомимся с Otto, наследником Vagrant
habra.15
habrabot(difrex,1) — All
2015-10-09 12:30:05
[Otto][1] — это новый продукт от Hashicorp, логический наследник Vagrant, призванный упростить процесс разработки и деплоя программ в современном мире облачных технологий. Концептуально новый подход к проблеме, проверенные технологии под капотом и открытый исходный код. Персональный DevOps ассистент разработчика. ![][2] [Читать дальше →][3]
[1]: https://www.ottoproject.io
[2]: https://habrastorage.org/files/6d4/ec4/b47/6d4ec4b4786f47048d5fd55301234115.png
[3]: http://habrahabr.ru/post/268497/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 12:30:05
[Otto][1] — это новый продукт от Hashicorp, логический наследник Vagrant, призванный упростить процесс разработки и деплоя программ в современном мире облачных технологий. Концептуально новый подход к проблеме, проверенные технологии под капотом и открытый исходный код. Персональный DevOps ассистент разработчика. ![][2] [Читать дальше →][3]
[1]: https://www.ottoproject.io
[2]: https://habrastorage.org/files/6d4/ec4/b47/6d4ec4b4786f47048d5fd55301234115.png
{kind=link}
[3]: http://habrahabr.ru/post/268497/#habracut
[>]
[Из песочницы] Внешняя сортировка с O(1) дополнительной памяти
habra.15
habrabot(difrex,1) — All
2015-10-09 15:00:07
Прочитав [эту статью][1], я вспомнил, как писал внешнюю сортировку, которая использовала O(1) внешней памяти. Функция получала бинарый файл и максимальный размер памяти, которую она могла выделить под массив:
void ext_sort(const std::string filename, const size_t memory)
Я использовал алгоритм из [Effective Performance of External Sorting with No Additional Disk Space][2]:
1. Разделим файл на блоки, которые помещаются в доступную память. Обозначим эти блоки Block\_1, Block\_2, …, Block\_(S-1), Block\_S. Установим P = 1.
2. Читаем Block\_P в память.
3. Отсортируем данные в памяти и запишем назад в Block\_P. Установим P = P + 1, и если P ≤ S, то читаем Block\_P в память и повторяем этот шаг. Другими словами, отсортируем каждый блок файла.
4. Разделим каждый блок на меньшие блоки B\_1 и B\_2. Каждый из таких блоков занимает половину доступной памяти.
5. Читаем блок B\_1 блока Block\_1 в первую половину доступной памяти. Установим Q = 2.
6. Читаем блок B\_1 блока Block\_Q во вторую половину доступной памяти.
7. Объеденим массивы в памяти с помощью in-place слияния, запишем вторую половину памяти в блок B\_1 блока Block\_Q и установим Q = Q + 1, если Q ≤ S, читаем блок B\_1 блока Block\_Q во вторую половину доступной памяти и повторяем этот шаг.
8. Записываем первую половину доступной памяти в блок B\_1 блока Block\_1. Так как мы всегда оставляли в памяти меньшую половину элементов и провели слияние со всеми блоками, то в этой части памяти хранятся M минимальных элементы всего файла.
9. Читаем блок B\_2 блока Block\_S во вторую половину доступной памяти. Установим Q = S −1.
10. Читаем блок B\_2 блока Block\_Q в первую половину доступной памяти.
11. Объеденим массивы в памяти с помощью in-place слияния, запишем первую половину доступной памяти в блок B\_2 блока Block\_Q и установим Q = Q −1. Если Q ≥ 1 читаем блок B\_2 блока Block\_Q в первую половину доступной памяти и повторяем этот шаг.
12. Записываем вторую половину доступной памяти в блок B\_2 блока Block\_S. Аналогично шагу 8, тут хранятся максимальные элементы всего файла.
13. Начиная от блока B\_2 блока Block\_1 и до блока B\_1 блока Block\_S, определим новые блоки в файле и снова пронумеруем их Block\_1 to Block\_S. Разделим каждый блок на блоки B\_1 и B\_2. Установим P = 1.
14. Читаем B\_1 и B\_2 блока Block\_P в память. Объеденим массивы в памяти. запишем отсортированный массив назад в Block\_P и установим P = P +1. Если P ≤ S, повторяем этот шаг.
15. Если S > 1, возвращаемся к шагу 5. Каждый раз мы выделяем M минимальных и максимальных элементов, записываем их в начало и конец файла соответственно, а потом делаем то же самое с оставшимися элементами, пока не дойдем до середины файла.
Преимущество такого алгоритма, кроме отсутствия буфера на диске, это то, что с диска мы читаем данные относительно большими порциями, что ускоряет алгоритм. Реализуем алгоритм на C++. [Читать дальше →][3]
[1]: http://habrahabr.ru/post/266557/
[2]: https://scholar.google.co.il/scholar?cluster=7995905689817415486&hl=ru&as_sdt=0,5
[3]: http://habrahabr.ru/post/268535/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 15:00:07
Прочитав [эту статью][1], я вспомнил, как писал внешнюю сортировку, которая использовала O(1) внешней памяти. Функция получала бинарый файл и максимальный размер памяти, которую она могла выделить под массив:
void ext_sort(const std::string filename, const size_t memory)
Я использовал алгоритм из [Effective Performance of External Sorting with No Additional Disk Space][2]:
1. Разделим файл на блоки, которые помещаются в доступную память. Обозначим эти блоки Block\_1, Block\_2, …, Block\_(S-1), Block\_S. Установим P = 1.
2. Читаем Block\_P в память.
3. Отсортируем данные в памяти и запишем назад в Block\_P. Установим P = P + 1, и если P ≤ S, то читаем Block\_P в память и повторяем этот шаг. Другими словами, отсортируем каждый блок файла.
4. Разделим каждый блок на меньшие блоки B\_1 и B\_2. Каждый из таких блоков занимает половину доступной памяти.
5. Читаем блок B\_1 блока Block\_1 в первую половину доступной памяти. Установим Q = 2.
6. Читаем блок B\_1 блока Block\_Q во вторую половину доступной памяти.
7. Объеденим массивы в памяти с помощью in-place слияния, запишем вторую половину памяти в блок B\_1 блока Block\_Q и установим Q = Q + 1, если Q ≤ S, читаем блок B\_1 блока Block\_Q во вторую половину доступной памяти и повторяем этот шаг.
8. Записываем первую половину доступной памяти в блок B\_1 блока Block\_1. Так как мы всегда оставляли в памяти меньшую половину элементов и провели слияние со всеми блоками, то в этой части памяти хранятся M минимальных элементы всего файла.
9. Читаем блок B\_2 блока Block\_S во вторую половину доступной памяти. Установим Q = S −1.
10. Читаем блок B\_2 блока Block\_Q в первую половину доступной памяти.
11. Объеденим массивы в памяти с помощью in-place слияния, запишем первую половину доступной памяти в блок B\_2 блока Block\_Q и установим Q = Q −1. Если Q ≥ 1 читаем блок B\_2 блока Block\_Q в первую половину доступной памяти и повторяем этот шаг.
12. Записываем вторую половину доступной памяти в блок B\_2 блока Block\_S. Аналогично шагу 8, тут хранятся максимальные элементы всего файла.
13. Начиная от блока B\_2 блока Block\_1 и до блока B\_1 блока Block\_S, определим новые блоки в файле и снова пронумеруем их Block\_1 to Block\_S. Разделим каждый блок на блоки B\_1 и B\_2. Установим P = 1.
14. Читаем B\_1 и B\_2 блока Block\_P в память. Объеденим массивы в памяти. запишем отсортированный массив назад в Block\_P и установим P = P +1. Если P ≤ S, повторяем этот шаг.
15. Если S > 1, возвращаемся к шагу 5. Каждый раз мы выделяем M минимальных и максимальных элементов, записываем их в начало и конец файла соответственно, а потом делаем то же самое с оставшимися элементами, пока не дойдем до середины файла.
Преимущество такого алгоритма, кроме отсутствия буфера на диске, это то, что с диска мы читаем данные относительно большими порциями, что ускоряет алгоритм. Реализуем алгоритм на C++. [Читать дальше →][3]
[1]: http://habrahabr.ru/post/266557/
[2]: https://scholar.google.co.il/scholar?cluster=7995905689817415486&hl=ru&as_sdt=0,5
[3]: http://habrahabr.ru/post/268535/#habracut
[>]
[Перевод] Муравьиная оптимизация и сетевые алгоритмы
habra.15
habrabot(difrex,1) — All
2015-10-09 16:00:07
Как вы могли заметить, у нас тут затишье. Но наш творческий поиск не прекращается, и первая октябрьская публикация будет посвящена ACO (Ant Colony Optimization) ![][1] Отдавая должное автору, мы не будем публиковать здесь последнюю часть статьи, содержащую пример на JavaScript, а предложим вам опробовать его на сайте оригинала. Под катом же вы найдете перевод теоретической части, доступно рассказывающей о тонкостях муравьиной оптимизации в различных сценариях. [Читать дальше →][2]
[1]: https://habrastorage.org/files/f7b/030/866/f7b0308662d94be683e0677bcb89f127.jpg
[2]: http://habrahabr.ru/post/268513/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 16:00:07
Как вы могли заметить, у нас тут затишье. Но наш творческий поиск не прекращается, и первая октябрьская публикация будет посвящена ACO (Ant Colony Optimization) ![][1] Отдавая должное автору, мы не будем публиковать здесь последнюю часть статьи, содержащую пример на JavaScript, а предложим вам опробовать его на сайте оригинала. Под катом же вы найдете перевод теоретической части, доступно рассказывающей о тонкостях муравьиной оптимизации в различных сценариях. [Читать дальше →][2]
[1]: https://habrastorage.org/files/f7b/030/866/f7b0308662d94be683e0677bcb89f127.jpg
{kind=link}
[2]: http://habrahabr.ru/post/268513/#habracut
[>]
Освоение специальности Data Science на Coursera: личный опыт
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
![][1] Недавно Владимир Подольский [vpodolskiy][2], аналитик в департаменте по работе с образованием [IBS][3] закончил обучение по специализации Data Science на Coursera. Это набор из 9 курсеровских курсов от Университета Джонса Хопкинса + дипломная работа, успешное завершение которых дает право на сертификат. Для нашего блога на Хабре он написал подробный пост о своей учебе. Для удобства мы разбили его на 2 части. Добавим, что Владимир стал еще и редактором проекта по переводу специализации Data Science на русский язык, который весной [запустили IBS и ABBYY Language Services][4]. _**Часть 1.** О специальности Data Science в общих чертах. Курсы: Инструменты анализа данных (программирование на R); Предварительная обработка данных; Документирование процесса обработки данных._
## Привет, Хабр!
Не так давно закончился мой 7-месячный марафон по освоению специализации «Наука о данных» (Data Science) на Coursera. Организационные стороны освоения специальности очень точно [описаны тут][5]. В своём посте я поделюсь впечатлениями от контента курсов. Надеюсь, после прочтения этой заметки каждый сможет сделать для себя выводы о том, стоит ли тратить время на получение знаний по аналитике данных или нет. [Читать дальше →][6]
[1]: https://habrastorage.org/files/90c/52b/73b/90c52b73b20741d1a8b1d133b5bdbc07.png
[2]: http://habrahabr.ru/users/vpodolskiy/
[3]: http://www.ibs.ru/
[4]: http://www.ibs.ru/media/news/ibs-i-abbyy-language-services-gotovyat-spetsialistov-v-oblasti-bolshikh-dannykh/
[5]: http://megamozg.ru/post/14960/
[6]: http://habrahabr.ru/post/268491/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
![][1] Недавно Владимир Подольский [vpodolskiy][2], аналитик в департаменте по работе с образованием [IBS][3] закончил обучение по специализации Data Science на Coursera. Это набор из 9 курсеровских курсов от Университета Джонса Хопкинса + дипломная работа, успешное завершение которых дает право на сертификат. Для нашего блога на Хабре он написал подробный пост о своей учебе. Для удобства мы разбили его на 2 части. Добавим, что Владимир стал еще и редактором проекта по переводу специализации Data Science на русский язык, который весной [запустили IBS и ABBYY Language Services][4]. _**Часть 1.** О специальности Data Science в общих чертах. Курсы: Инструменты анализа данных (программирование на R); Предварительная обработка данных; Документирование процесса обработки данных._
## Привет, Хабр!
Не так давно закончился мой 7-месячный марафон по освоению специализации «Наука о данных» (Data Science) на Coursera. Организационные стороны освоения специальности очень точно [описаны тут][5]. В своём посте я поделюсь впечатлениями от контента курсов. Надеюсь, после прочтения этой заметки каждый сможет сделать для себя выводы о том, стоит ли тратить время на получение знаний по аналитике данных или нет. [Читать дальше →][6]
[1]: https://habrastorage.org/files/90c/52b/73b/90c52b73b20741d1a8b1d133b5bdbc07.png
{kind=link}
[2]: http://habrahabr.ru/users/vpodolskiy/
[3]: http://www.ibs.ru/
[4]: http://www.ibs.ru/media/news/ibs-i-abbyy-language-services-gotovyat-spetsialistov-v-oblasti-bolshikh-dannykh/
[5]: http://megamozg.ru/post/14960/
[6]: http://habrahabr.ru/post/268491/#habracut
[>]
Запуск DOS-приложения в Linux
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
Необходимость запуска DOS-приложений под Linux возникает нечасто, но случается. Вот как-то и со мной случилось, решил поделиться опытом, может, кому пригодится. А нужно было запустить кем-то, когда-то написанное приложение для поликлиники, работающее на Foxpro под DOSом, в Linux, т.к. денег на покупку Windows лицензий не нашлось. Исходные данные: Suse Linux Enterprise Desktop 10.3 — рабочие станции. Suse Linux Enterprise Server 10.3, на нем шара на Samba (я же до этого и расшаривал для работы с Windows рабочих станций, т.к. на лицензию для Win-сервака тоже денег не было), имя шары, как ни странно, — SHARE. Происходило всё 2-3 года назад, поэтому версии SLED и SLES на момент установки были не такие уж и древние. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268529/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
Необходимость запуска DOS-приложений под Linux возникает нечасто, но случается. Вот как-то и со мной случилось, решил поделиться опытом, может, кому пригодится. А нужно было запустить кем-то, когда-то написанное приложение для поликлиники, работающее на Foxpro под DOSом, в Linux, т.к. денег на покупку Windows лицензий не нашлось. Исходные данные: Suse Linux Enterprise Desktop 10.3 — рабочие станции. Suse Linux Enterprise Server 10.3, на нем шара на Samba (я же до этого и расшаривал для работы с Windows рабочих станций, т.к. на лицензию для Win-сервака тоже денег не было), имя шары, как ни странно, — SHARE. Происходило всё 2-3 года назад, поэтому версии SLED и SLES на момент установки были не такие уж и древние. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268529/#habracut
[>]
Security Week 41: цензура исследований, взлом Outlook Web Access, потери данных на стыках
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
![][1]Сегодня — специальный корпоративный выпуск нашего дайджеста, в котором мы поговорим о таких вещах как ROI, EBITDA, TCO, РСБУ, CRM, SLA, NDA, GAAP, и т.д. Впрочем, нет, поговорим, как обычно, о самых значимых новостях безопасности за неделю. Вышло так, что все три так или иначе относятся к корпоративной безопасности: показывают, как компании взламывают, как утекают данные, и как бизнес на это реагирует. В чем вообще основное отличие между «пользовательской» безопасностью и корпоративной? Во-первых, если пользователям доступны относительно простые защитные решения или методы, то для бизнеса простых решений не бывает — хотя бы из-за того, что инфраструктура значительно сложнее. Во-вторых, чтобы эффективно защитить компанию, нужны не только сложные технологии, но и определенные организационные решения. А как вообще обстоят дела с безопасностью у бизнеса? Скажем так, не очень хорошо. Например, Gartner [считает][2], что через три года на безопасность будет тратиться до 30% IT-бюджета, и что распространенный подход компаний «держать и не пущать» устарел. В смысле, сейчас типичная компания 90% усилий пускает на оборону периметра, и всего 10% — на обнаружение и реагирование. Если атакующему удалось пробить защиту, дальше он оказывается в достаточно благоприятной для него среде, с неприятными для жертвы последствиями. Рекомендация Gartner по изменению этого соотношения до 60/40 выглядит вполне разумной. Например, из нашего [исследования Carbanak][3], атаки на банковские организации, понятно, что в этой самой «зоне 10%» атакующие находились _очень_ долго. Предыдущие дайджесты новостей вы можете найти [тут][4]. [Читать дальше →][5]
[1]: https://habrastorage.org/files/566/ba3/3f4/566ba33f4f174923a3bc4205908a4b37.jpg
[2]: https://threatpost.ru/it-kompaniyam-pridetsya-tratit-30-byudzheta-na-bezopasnost/12493/
[3]: https://securelist.ru/blog/issledovaniya/25106/bolshoe-bankovskoe-ograblenie-apt-kampaniya-carbanak/
[4]: http://habrahabr.ru/search/?target_type=posts&q=%5Bklsw%5D%20&order_by=date
[5]: http://habrahabr.ru/post/268493/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
![][1]Сегодня — специальный корпоративный выпуск нашего дайджеста, в котором мы поговорим о таких вещах как ROI, EBITDA, TCO, РСБУ, CRM, SLA, NDA, GAAP, и т.д. Впрочем, нет, поговорим, как обычно, о самых значимых новостях безопасности за неделю. Вышло так, что все три так или иначе относятся к корпоративной безопасности: показывают, как компании взламывают, как утекают данные, и как бизнес на это реагирует. В чем вообще основное отличие между «пользовательской» безопасностью и корпоративной? Во-первых, если пользователям доступны относительно простые защитные решения или методы, то для бизнеса простых решений не бывает — хотя бы из-за того, что инфраструктура значительно сложнее. Во-вторых, чтобы эффективно защитить компанию, нужны не только сложные технологии, но и определенные организационные решения. А как вообще обстоят дела с безопасностью у бизнеса? Скажем так, не очень хорошо. Например, Gartner [считает][2], что через три года на безопасность будет тратиться до 30% IT-бюджета, и что распространенный подход компаний «держать и не пущать» устарел. В смысле, сейчас типичная компания 90% усилий пускает на оборону периметра, и всего 10% — на обнаружение и реагирование. Если атакующему удалось пробить защиту, дальше он оказывается в достаточно благоприятной для него среде, с неприятными для жертвы последствиями. Рекомендация Gartner по изменению этого соотношения до 60/40 выглядит вполне разумной. Например, из нашего [исследования Carbanak][3], атаки на банковские организации, понятно, что в этой самой «зоне 10%» атакующие находились _очень_ долго. Предыдущие дайджесты новостей вы можете найти [тут][4]. [Читать дальше →][5]
[1]: https://habrastorage.org/files/566/ba3/3f4/566ba33f4f174923a3bc4205908a4b37.jpg
{kind=link}
[2]: https://threatpost.ru/it-kompaniyam-pridetsya-tratit-30-byudzheta-na-bezopasnost/12493/
[3]: https://securelist.ru/blog/issledovaniya/25106/bolshoe-bankovskoe-ograblenie-apt-kampaniya-carbanak/
[4]: http://habrahabr.ru/search/?target_type=posts&q=%5Bklsw%5D%20&order_by=date
[5]: http://habrahabr.ru/post/268493/#habracut
[>]
Программные инструкции на естественном языке, или интенциональное программирование
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
Данная тема способна вызвать скорее негативную реакцию благодаря тому, что большинство разработчиков являются ее противниками. Все потому, что интенциональное программирование, по сравнению с классическим, имеет существенные недостатки:
* слабая детерминированность инструкций на естественном языке
* значительная длина каждой инструкции, что заставляет вводить довольно объемный код
* код выглядит единообразным, что может затруднять его восприятие и процесс поиска
* сниженная скорость работы программы за счет анализа большего количества символов
Но у него есть и существенные достоинства:
* человеку интуитивно понятны все инструкции, нет необходимости в предварительном изучения нового языка
* каждая инструкция однозначно отражает намерение разработчика, ее написавшего
* природная способность естественного языка к обобщению и созданию новых уровней абстракции (как для объектов, так и для методов манипуляции с ними) на основе существующих
* процесс программирования на естественном языке возможен не только в чисто императивном виде, но и в виде общения
Для меня наибольший интерес представляет последний пункт, позволяющий изменять поведение механизированной системы на лету в процессе коммуникации. В этом случае язык может выступать и как средство для манипуляций с данными и как средство для обмена данными. Это наделяет интенциональное программирование способностью к реализации своего потенциала в нишевых областях, таких, как робототехника, когда механизм сможет получать описание поведенческих алгоритмов, а так же любую другую информацию через единый коммуникационный интерфейс, при помощи единого языка. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268401/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
Данная тема способна вызвать скорее негативную реакцию благодаря тому, что большинство разработчиков являются ее противниками. Все потому, что интенциональное программирование, по сравнению с классическим, имеет существенные недостатки:
* слабая детерминированность инструкций на естественном языке
* значительная длина каждой инструкции, что заставляет вводить довольно объемный код
* код выглядит единообразным, что может затруднять его восприятие и процесс поиска
* сниженная скорость работы программы за счет анализа большего количества символов
Но у него есть и существенные достоинства:
* человеку интуитивно понятны все инструкции, нет необходимости в предварительном изучения нового языка
* каждая инструкция однозначно отражает намерение разработчика, ее написавшего
* природная способность естественного языка к обобщению и созданию новых уровней абстракции (как для объектов, так и для методов манипуляции с ними) на основе существующих
* процесс программирования на естественном языке возможен не только в чисто императивном виде, но и в виде общения
Для меня наибольший интерес представляет последний пункт, позволяющий изменять поведение механизированной системы на лету в процессе коммуникации. В этом случае язык может выступать и как средство для манипуляций с данными и как средство для обмена данными. Это наделяет интенциональное программирование способностью к реализации своего потенциала в нишевых областях, таких, как робототехника, когда механизм сможет получать описание поведенческих алгоритмов, а так же любую другую информацию через единый коммуникационный интерфейс, при помощи единого языка. [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268401/#habracut
[>]
Установка неподписанных программ на устройства с iOS 9 без Jailbreak
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
Дорого дня, уважаемые хабражители! Сегодня я расскажу вам о том, как можно установить неподписанное (или плохо подписанное) приложение на устройство с iOS 9. Да, без Jailbreak. Да, бесплатно. Нужен лишь компьютер с OS X и Apple ID. Как такое возможно? Читаем под катом. ![][1] Осторожно! Много картинок! [Читать дальше →][2]
[1]: https://habrastorage.org/files/38b/97d/250/38b97d250e3d41b796ce7cf5df3277ea.png
[2]: http://habrahabr.ru/post/268515/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
Дорого дня, уважаемые хабражители! Сегодня я расскажу вам о том, как можно установить неподписанное (или плохо подписанное) приложение на устройство с iOS 9. Да, без Jailbreak. Да, бесплатно. Нужен лишь компьютер с OS X и Apple ID. Как такое возможно? Читаем под катом. ![][1] Осторожно! Много картинок! [Читать дальше →][2]
[1]: https://habrastorage.org/files/38b/97d/250/38b97d250e3d41b796ce7cf5df3277ea.png
{kind=link}
[2]: http://habrahabr.ru/post/268515/#habracut
[>]
[Из песочницы] Пишем графическую программу на Python с tkinter
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
В работе со студентами и учениками я заметила, что при изучении какого-либо языка программирования большой интерес вызывает работа с графикой. Даже те студенты, которые скучали на заданиях про числа Фибоначчи, и уже казалось бы у них пропадал интерес к изучению языка, активизировались на темах, связанных с графикой. Поэтому предлагаю потренироваться в написании небольшой графической програмки на Python с использованием tkinter (кроссплатформенная библиотека для разработки графического интерфейса на языке Python). Код в этой статье написан для Python 3.5. **Задание**: написание программы для рисования на холсте произвольного размера кругов разных цветов. Не сложно, возможно программа «детская», но я думаю, для яркой иллюстрации того, что может tkinter самое оно. Хочу рассказать сначала о том, как указать цвет. Конечно удобным для компьютера способом. Для этого в tkinter есть специальный инструмент, который можно запустить таким образом: [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268531/#habracut
habra.15
habrabot(difrex,1) — All
2015-10-09 16:30:03
В работе со студентами и учениками я заметила, что при изучении какого-либо языка программирования большой интерес вызывает работа с графикой. Даже те студенты, которые скучали на заданиях про числа Фибоначчи, и уже казалось бы у них пропадал интерес к изучению языка, активизировались на темах, связанных с графикой. Поэтому предлагаю потренироваться в написании небольшой графической програмки на Python с использованием tkinter (кроссплатформенная библиотека для разработки графического интерфейса на языке Python). Код в этой статье написан для Python 3.5. **Задание**: написание программы для рисования на холсте произвольного размера кругов разных цветов. Не сложно, возможно программа «детская», но я думаю, для яркой иллюстрации того, что может tkinter самое оно. Хочу рассказать сначала о том, как указать цвет. Конечно удобным для компьютера способом. Для этого в tkinter есть специальный инструмент, который можно запустить таким образом: [Читать дальше →][1]
[1]: http://habrahabr.ru/post/268531/#habracut